Classification and Logistic Regression
文章目录
- 一、Classification: Probabilistic Generative Model
- Ideal Alternatives
- Two Boxes example
- Two Classes
- Gaussian Distribution
- Probability from Class
- Maximum Likelihood
- Now we can do classification
- Three Steps
- 二、Classification: Logistic Regression
- Step 1: Function Set
- Step 2: Goodness of a Function
- Step 3: Find the best function
- Logistic Regression + Square Error
- Generative v.s. Discriminative
- Multi-class Classification
- Limitation of Logistic Regression
- 总结
一、Classification: Probabilistic Generative Model
Ideal Alternatives
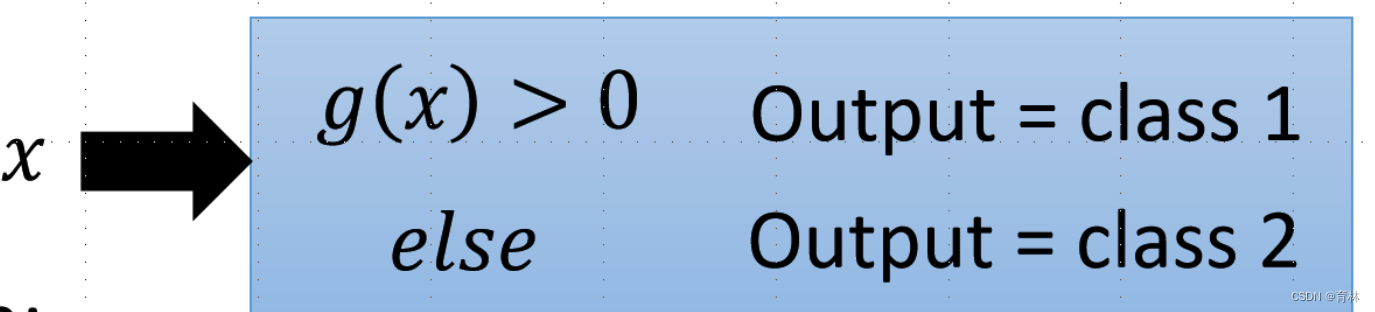
Function (Model):
Loss function:
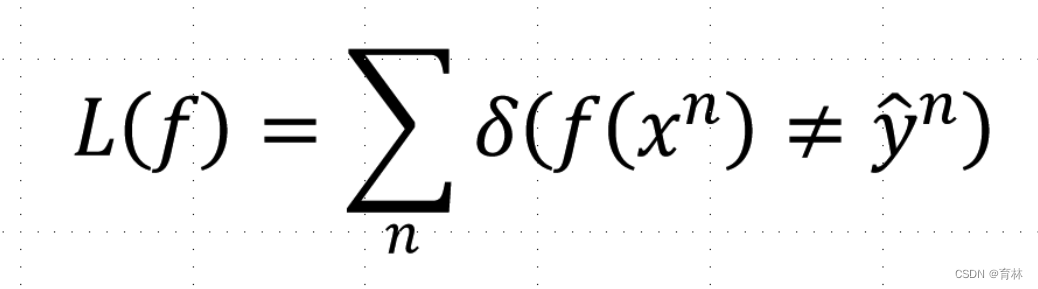
The number of times f get incorrect results on training data.
Find the best function:
Example: Perceptron, SVM
Classification as Regression?
Binary classification as example :
Training: Class 1 means the target is 1; Class 2 means the target is -1
Testing: closer to 1 → class 1; closer to -1 → class 2
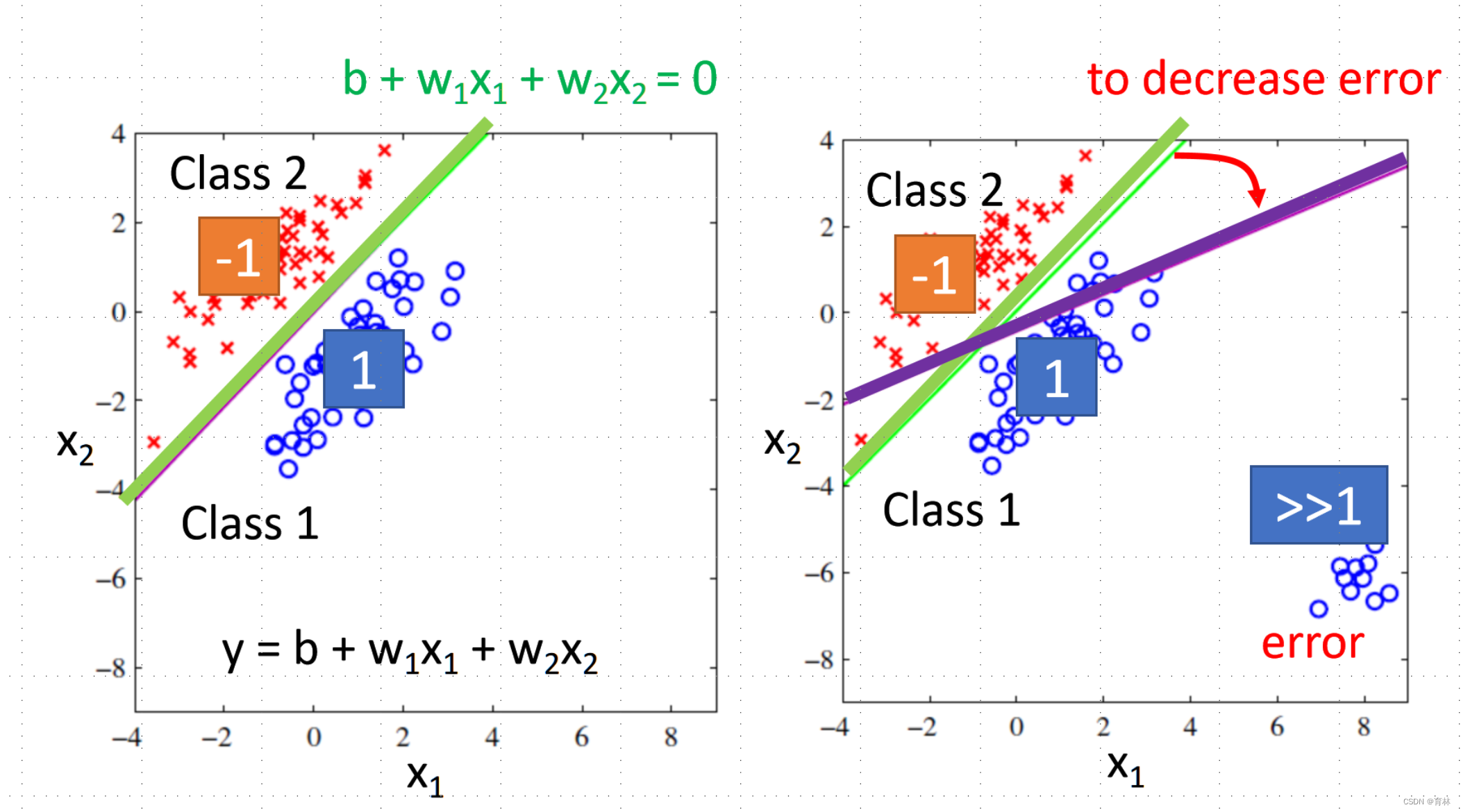
Penalize to the examples that are “too correct”
Multiple class: Class 1 means the target is 1; Class 2 means the target is 2; Class 3 means the target is 3 …… problematic
Two Boxes example
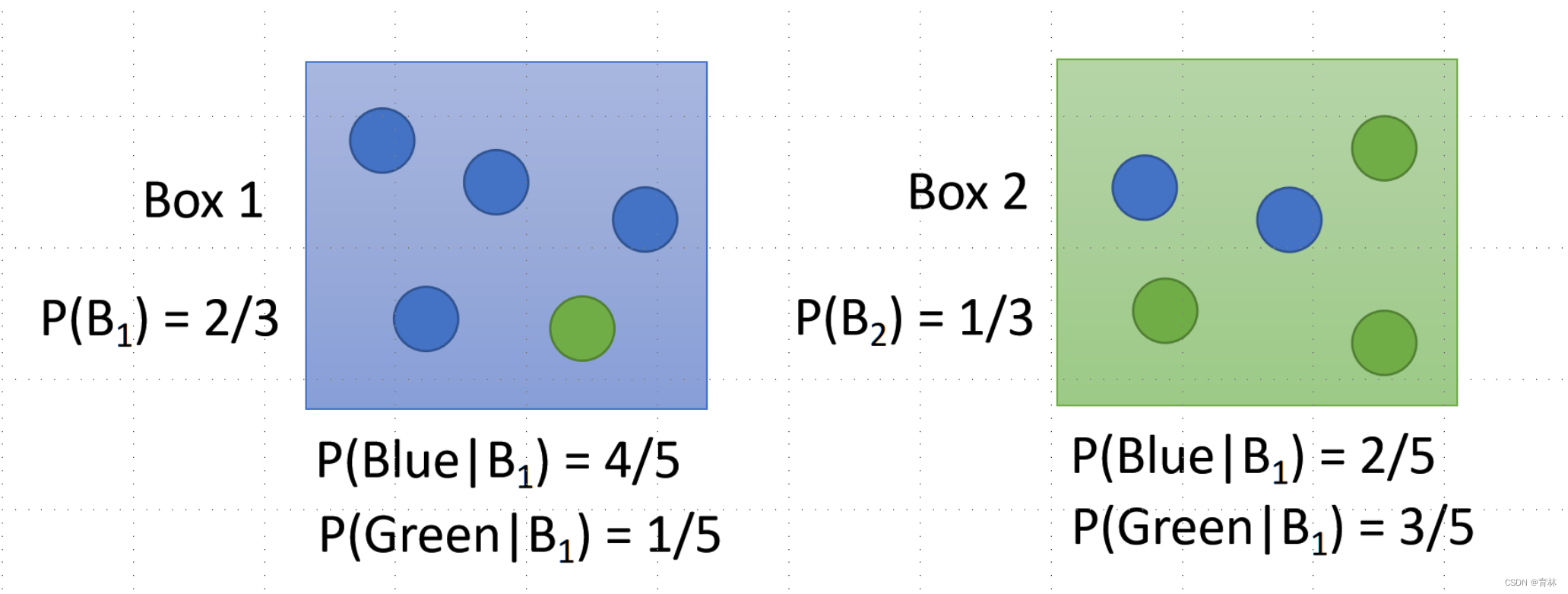
From one of the boxes,where does it come from?
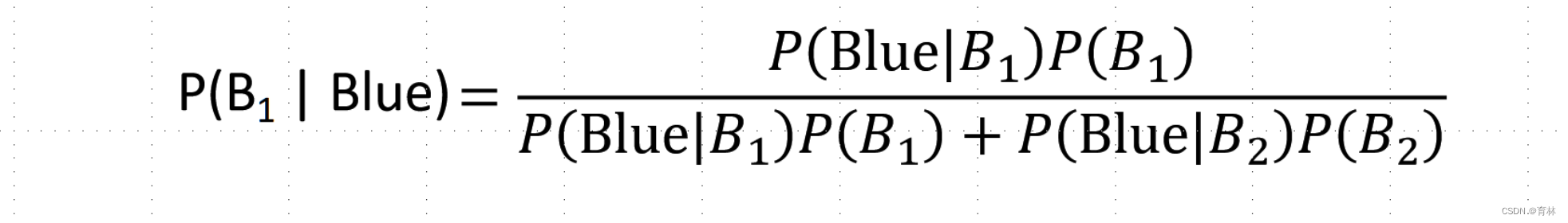
Two Classes
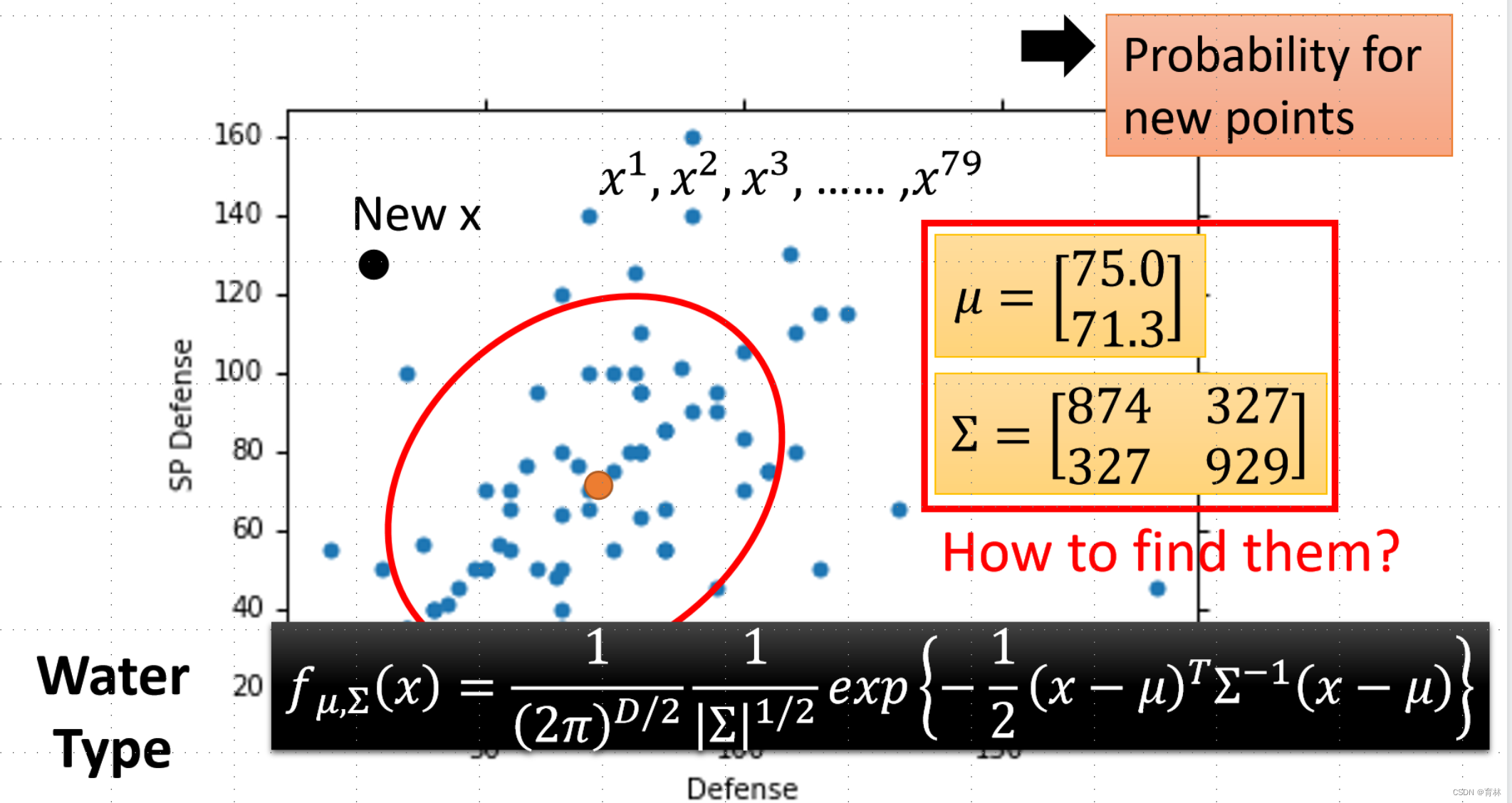
Estimating the Probabilities From training data
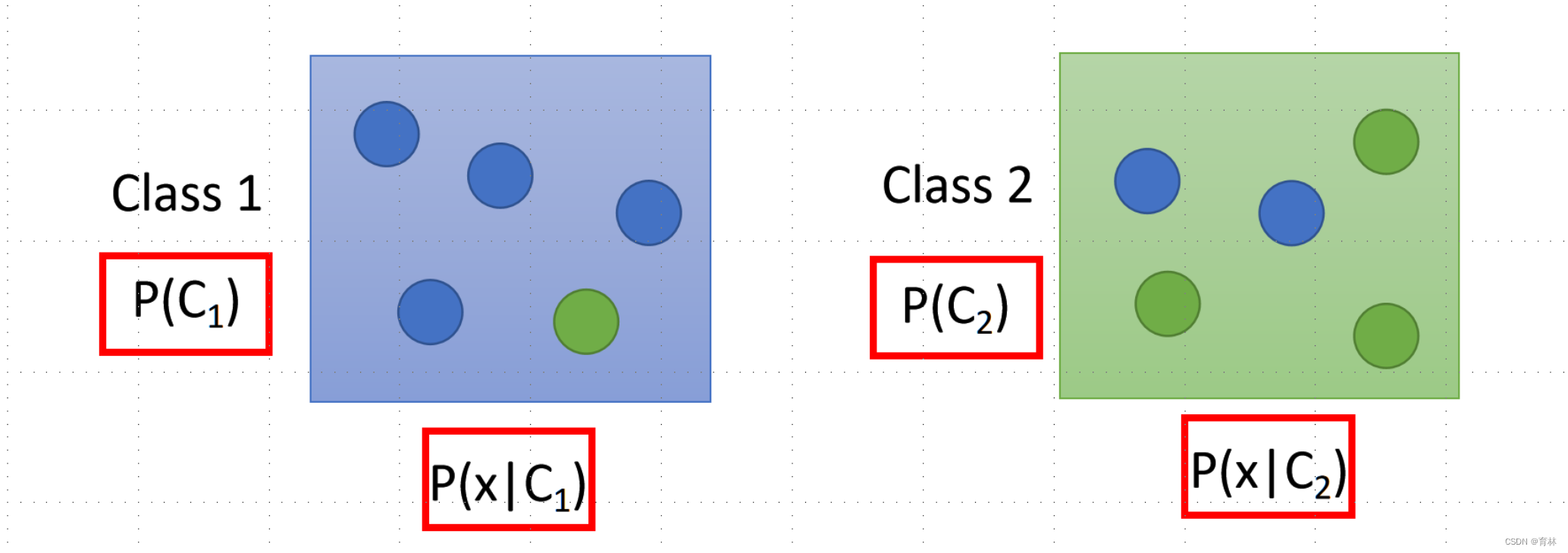
Given an x, which class does it belong to
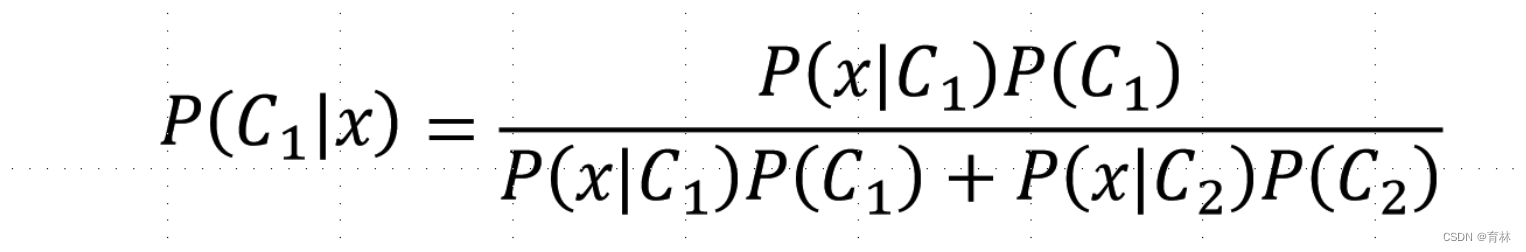
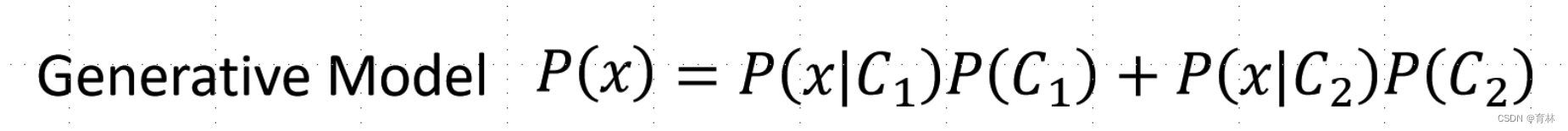
Gaussian Distribution
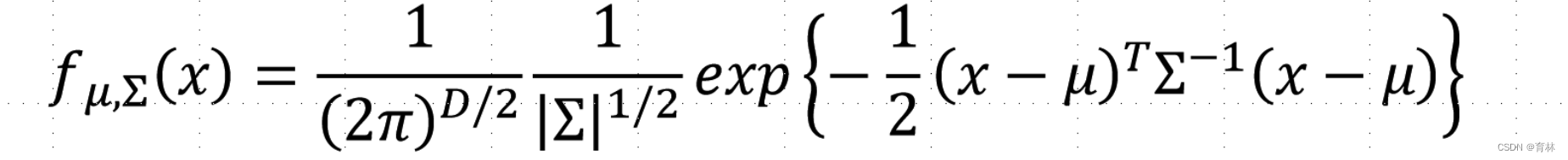
Input: vector x, output: probability of sampling x
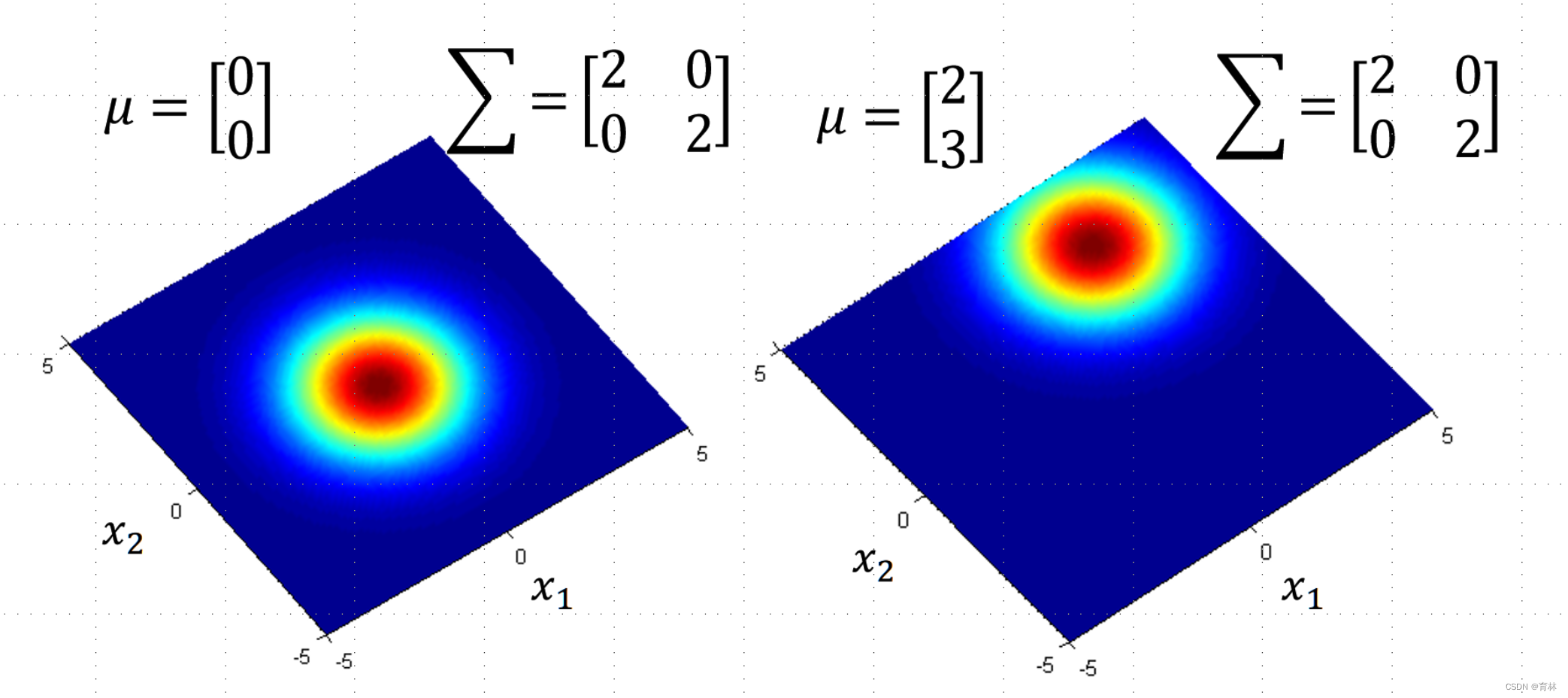
The shape of the function determines by mean μ and covariance matrix Σ
Probability from Class
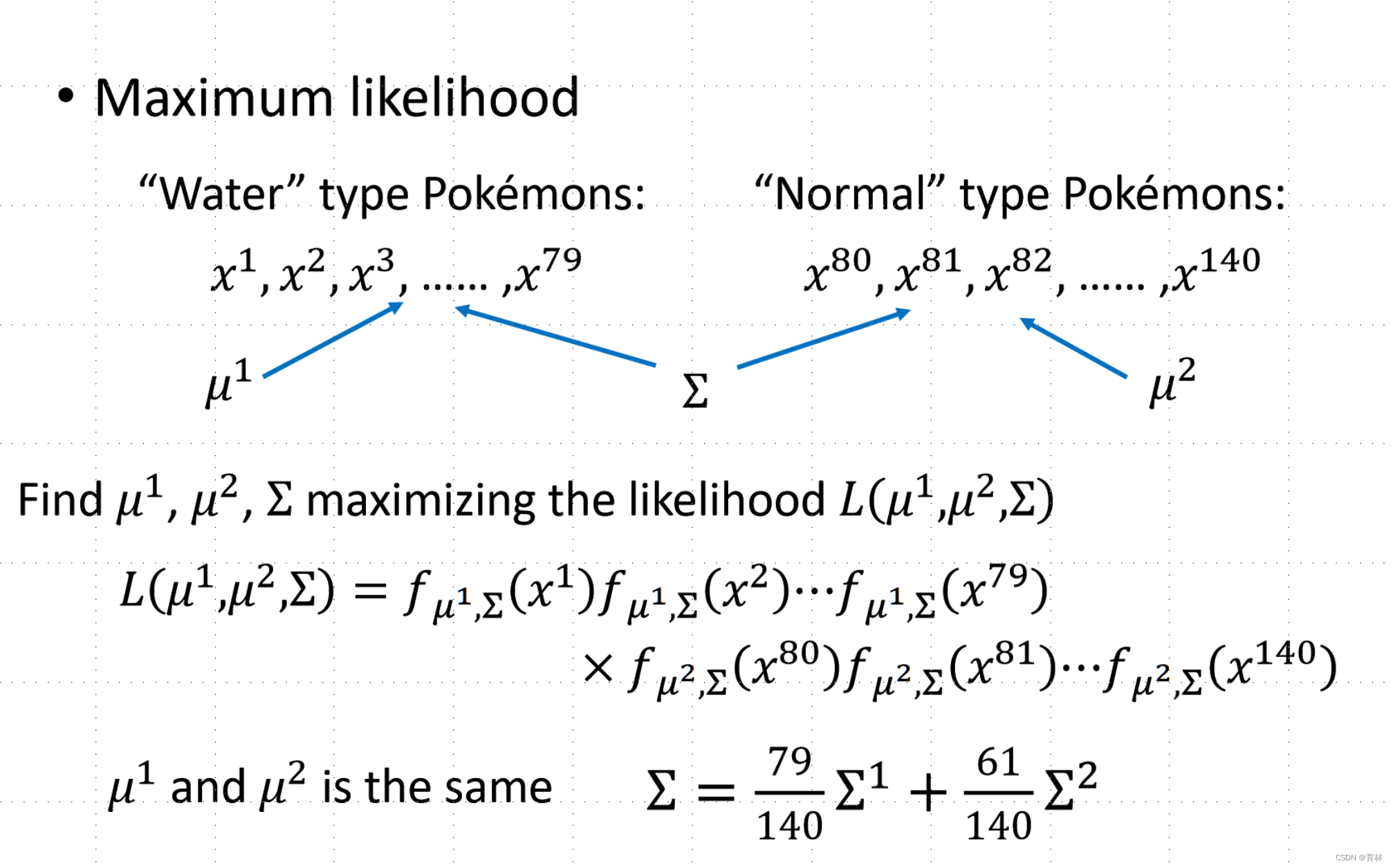
Maximum Likelihood
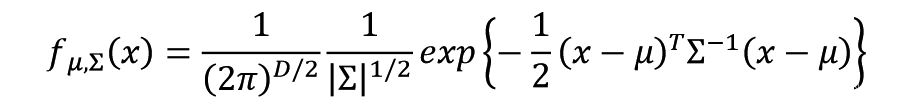
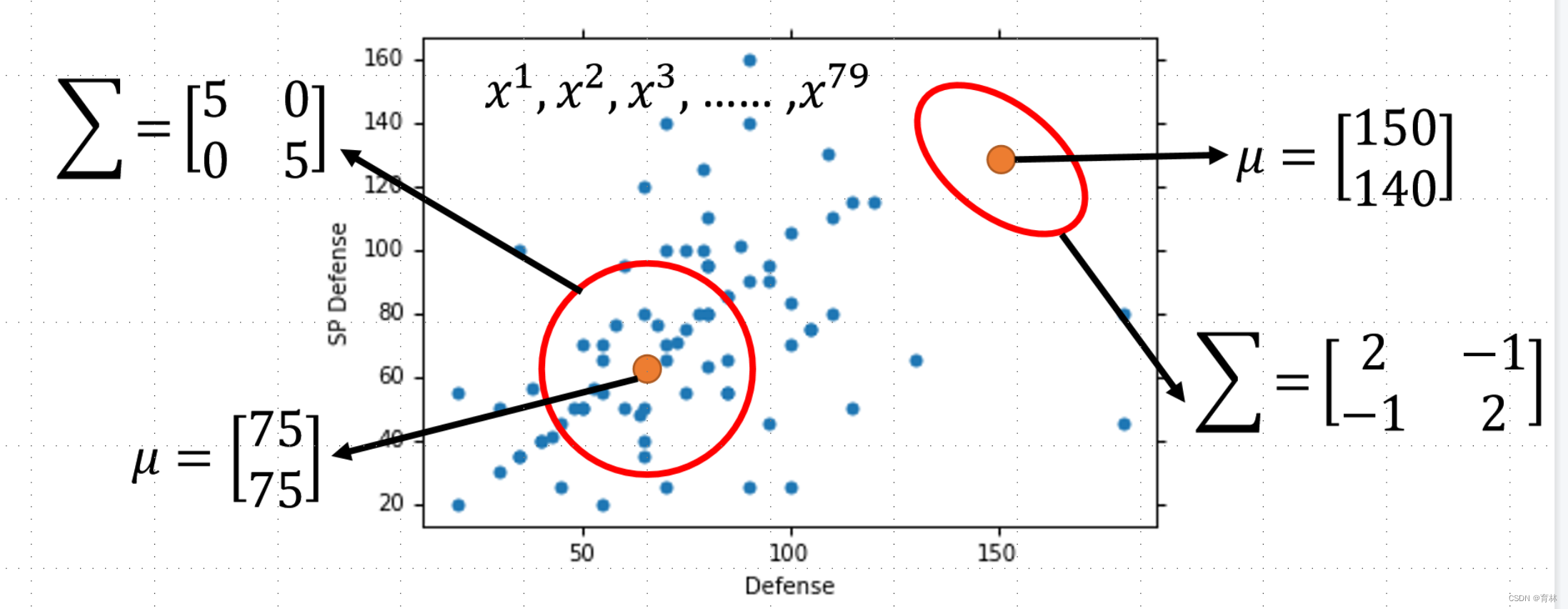
The Gaussian with any mean μ and covariance matrix Σ can generate these points

Likelihood of a Gaussian with mean μ and covariance matrix Σ = the probability of the Gaussian samples x1,x2,x^3, …… ,x^79
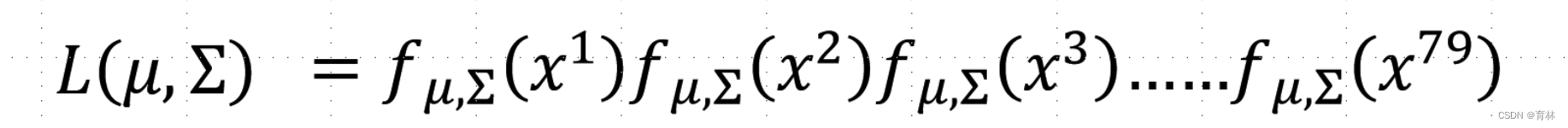
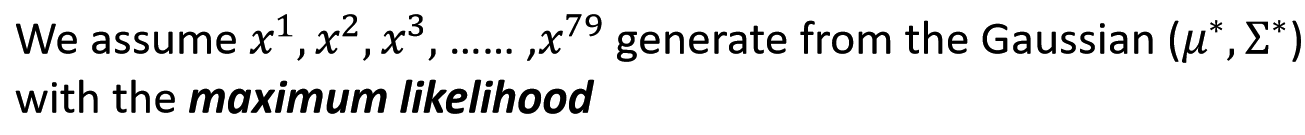
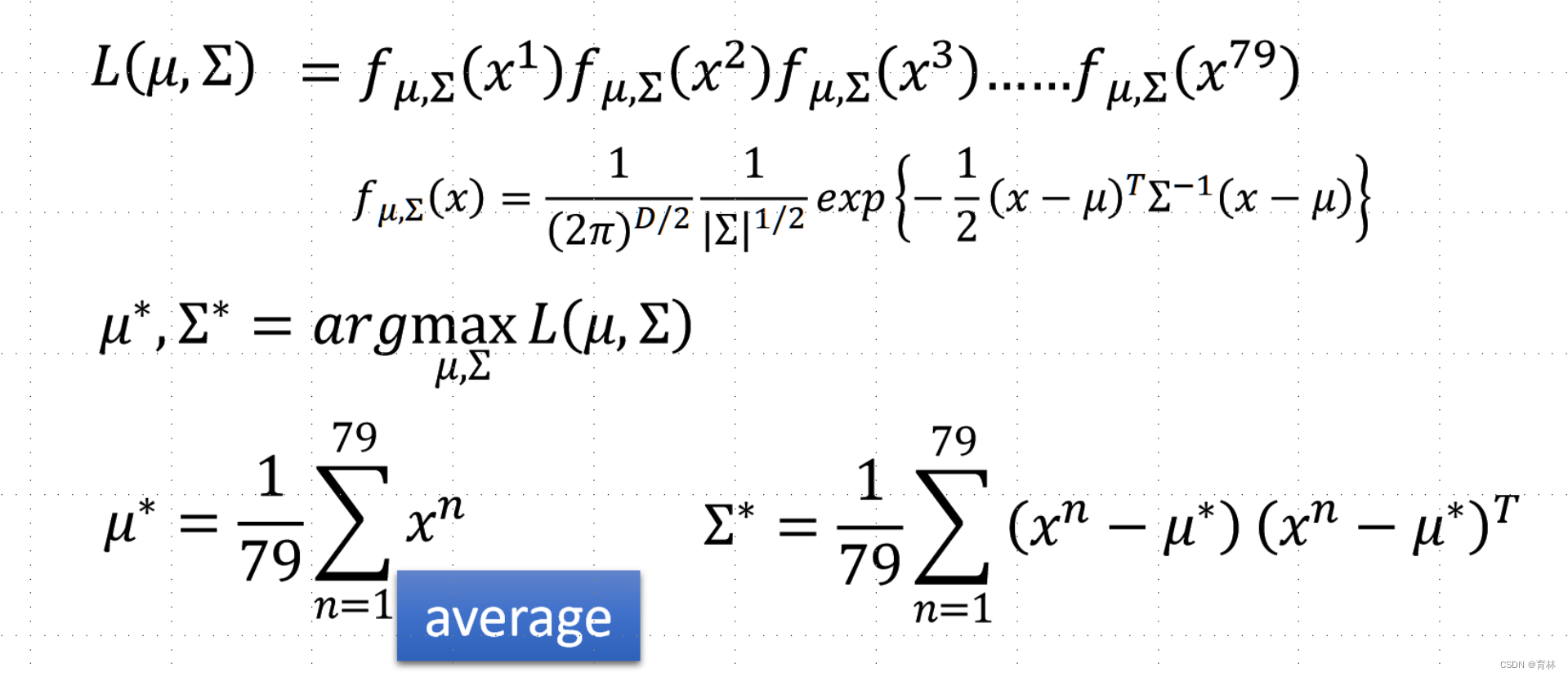
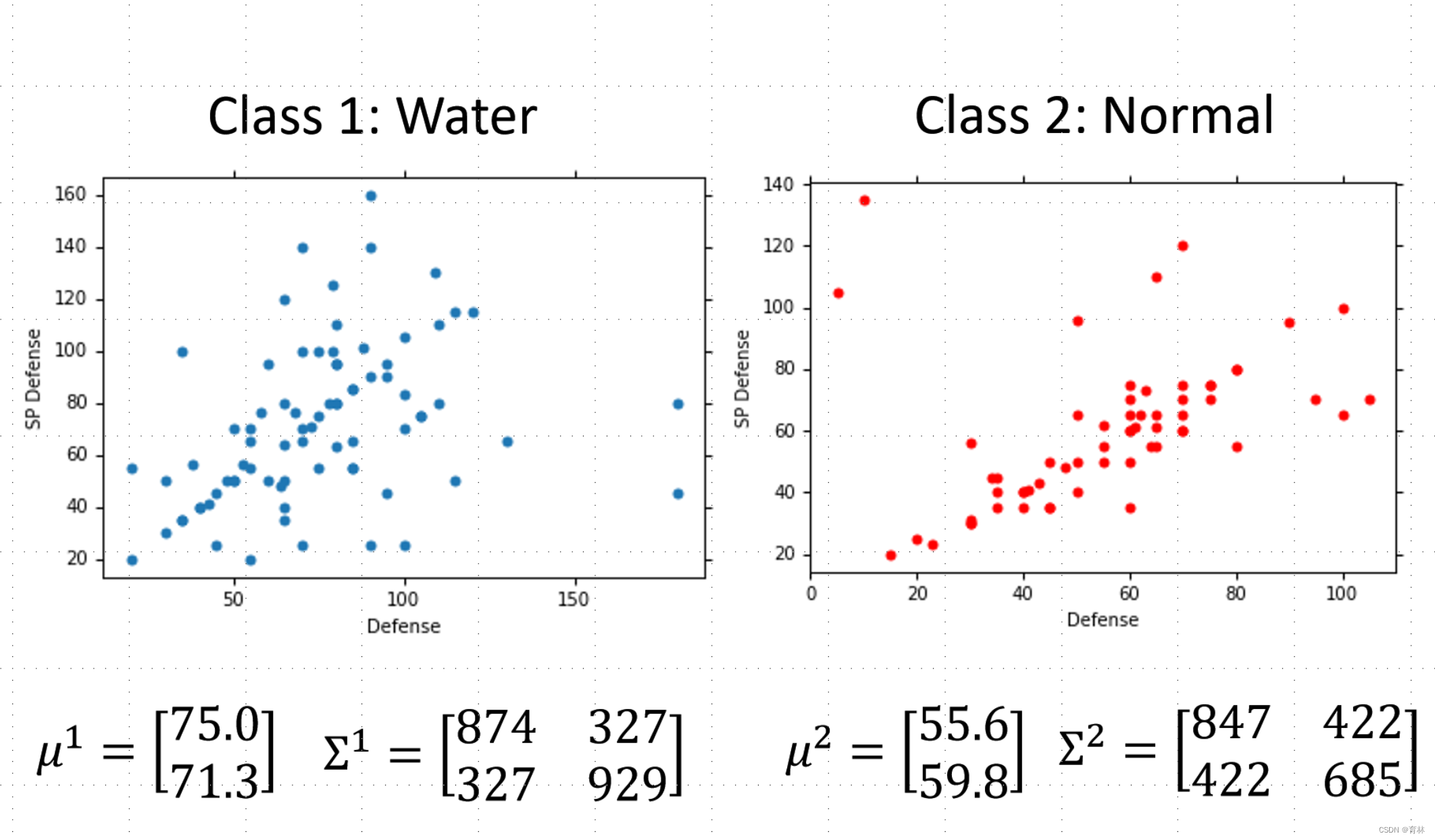
Now we can do classification
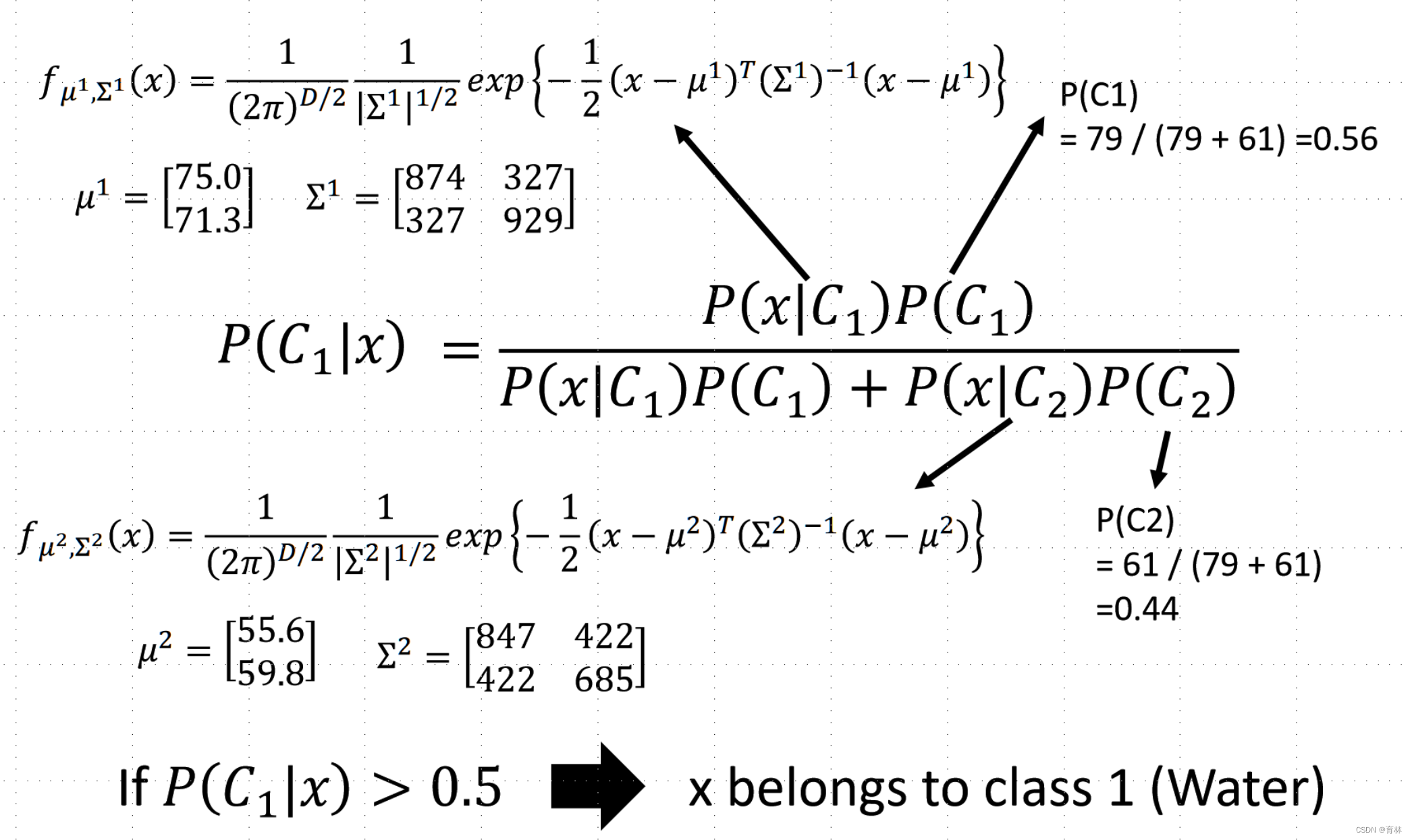
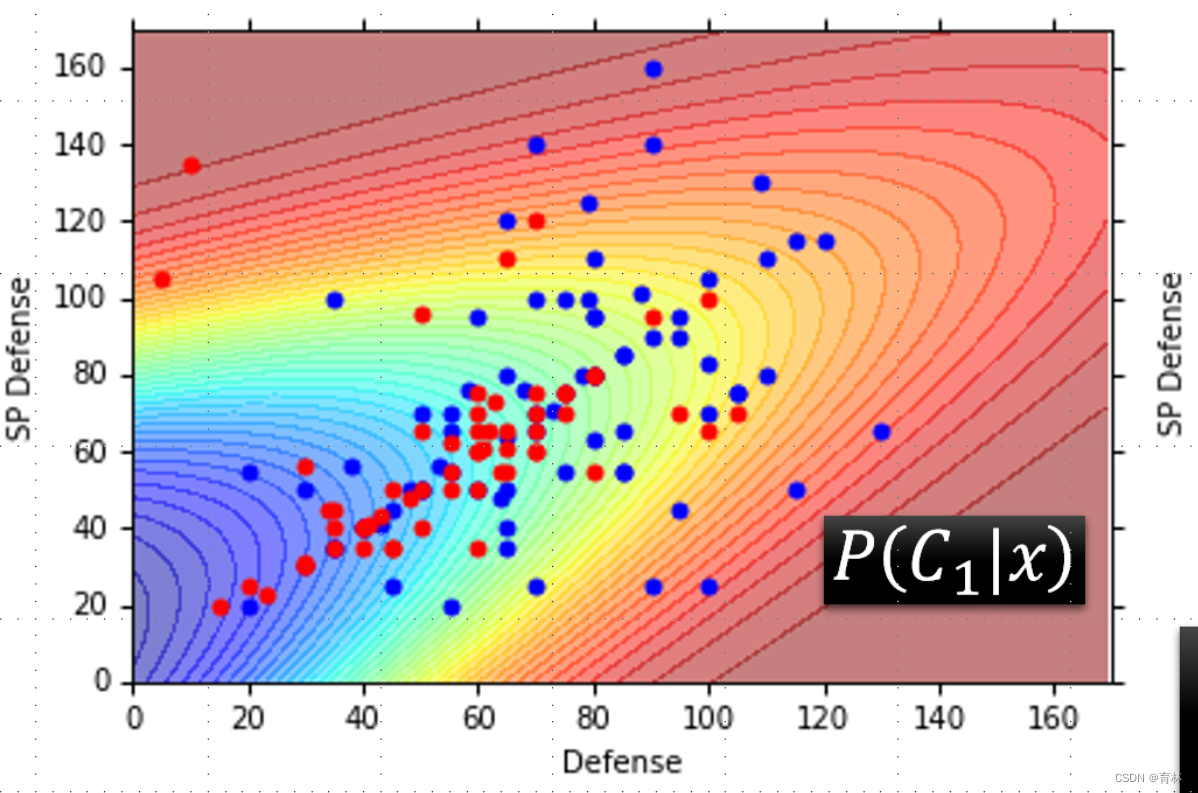
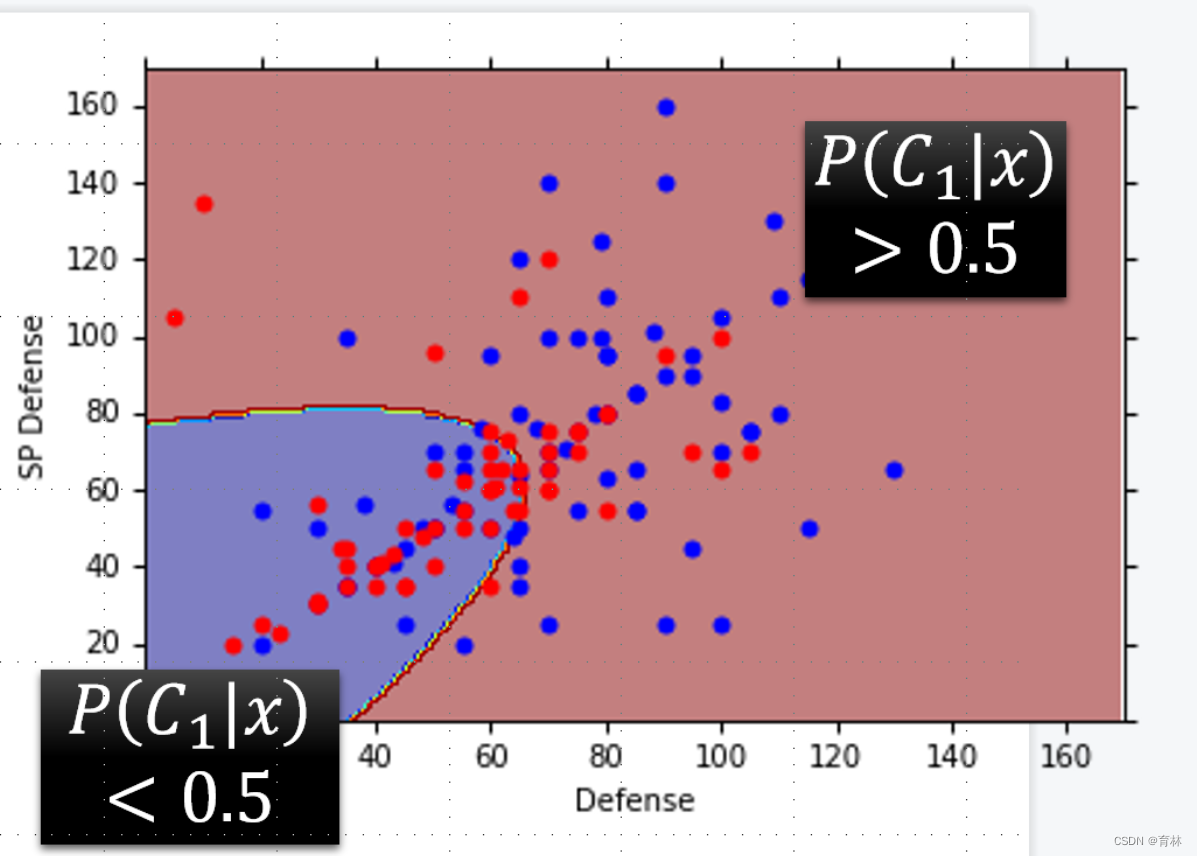
Testing data: 47% accuracy
All: hp, att, sp att,
de, sp de, speed (6 features)

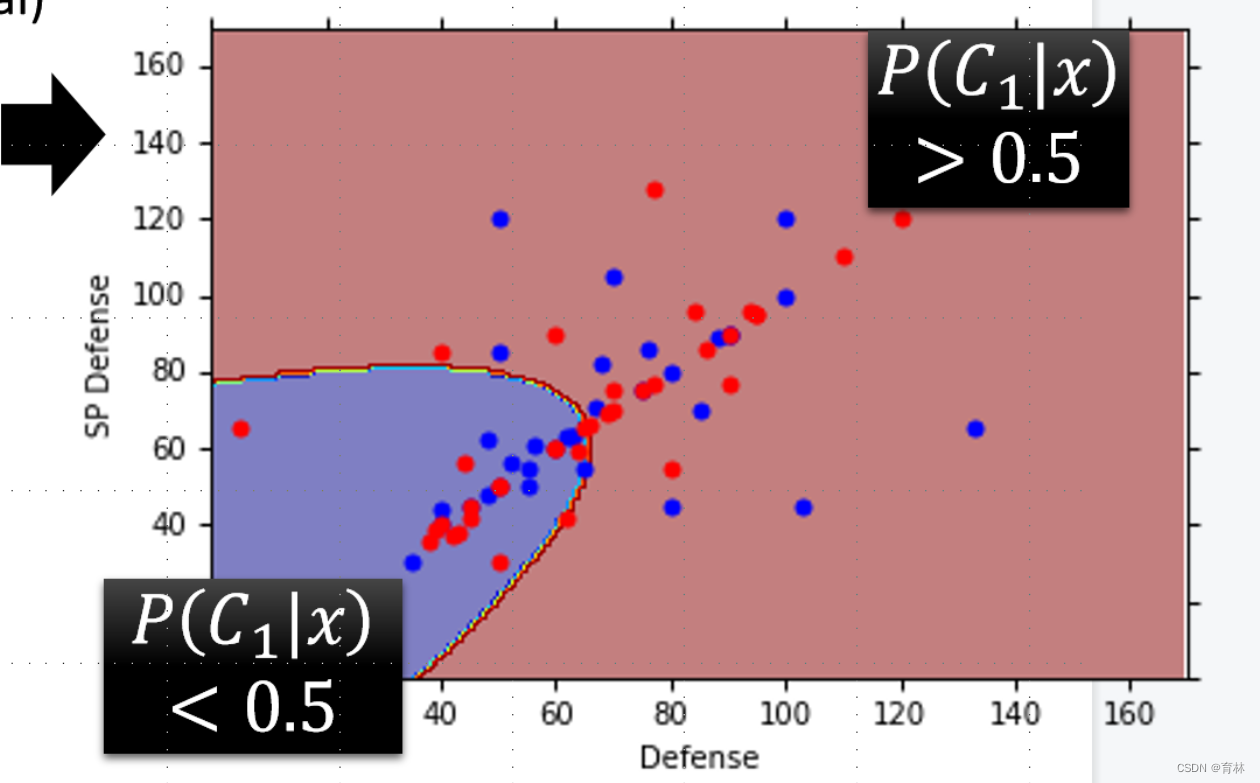
Modifying Model:
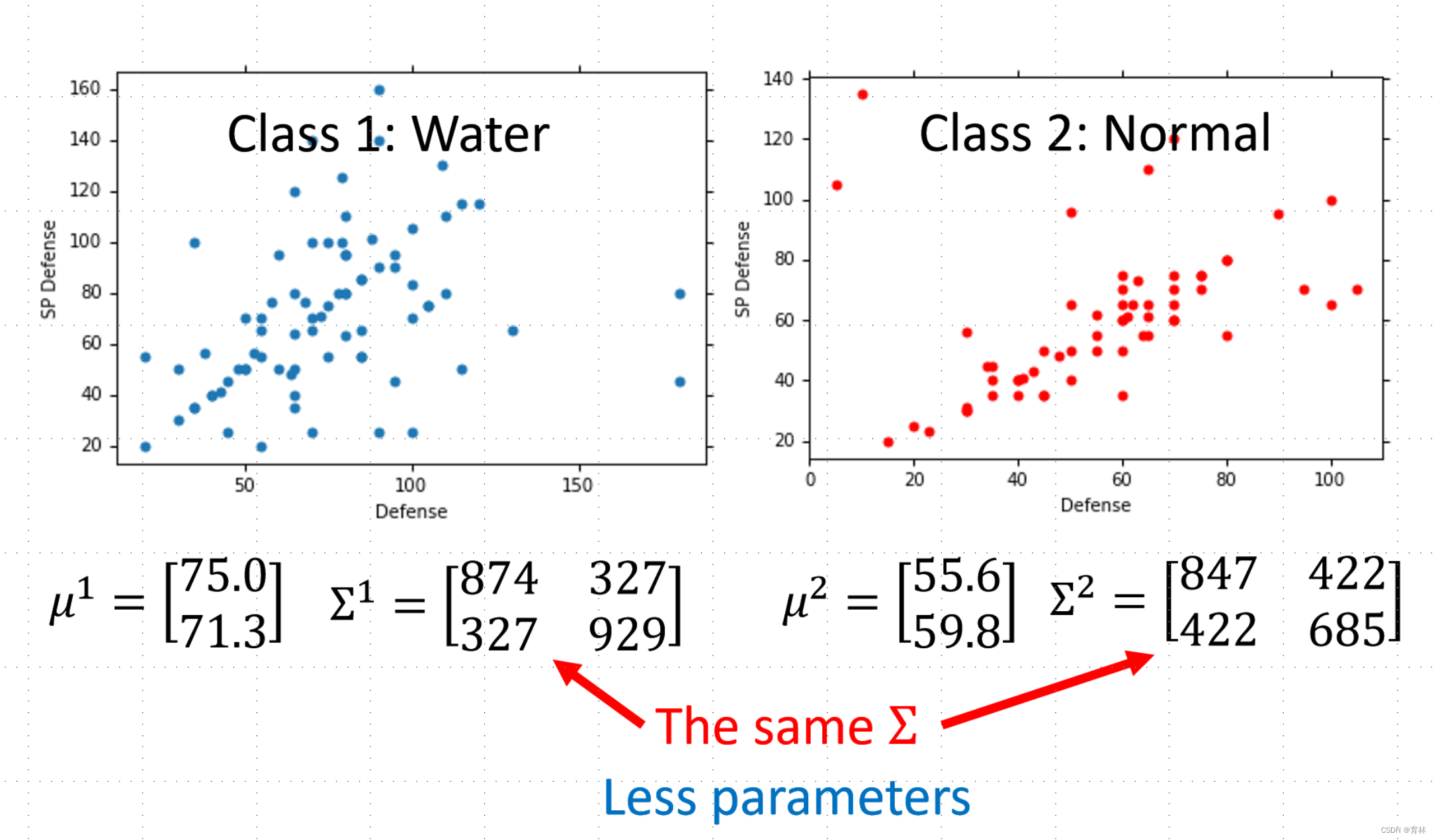
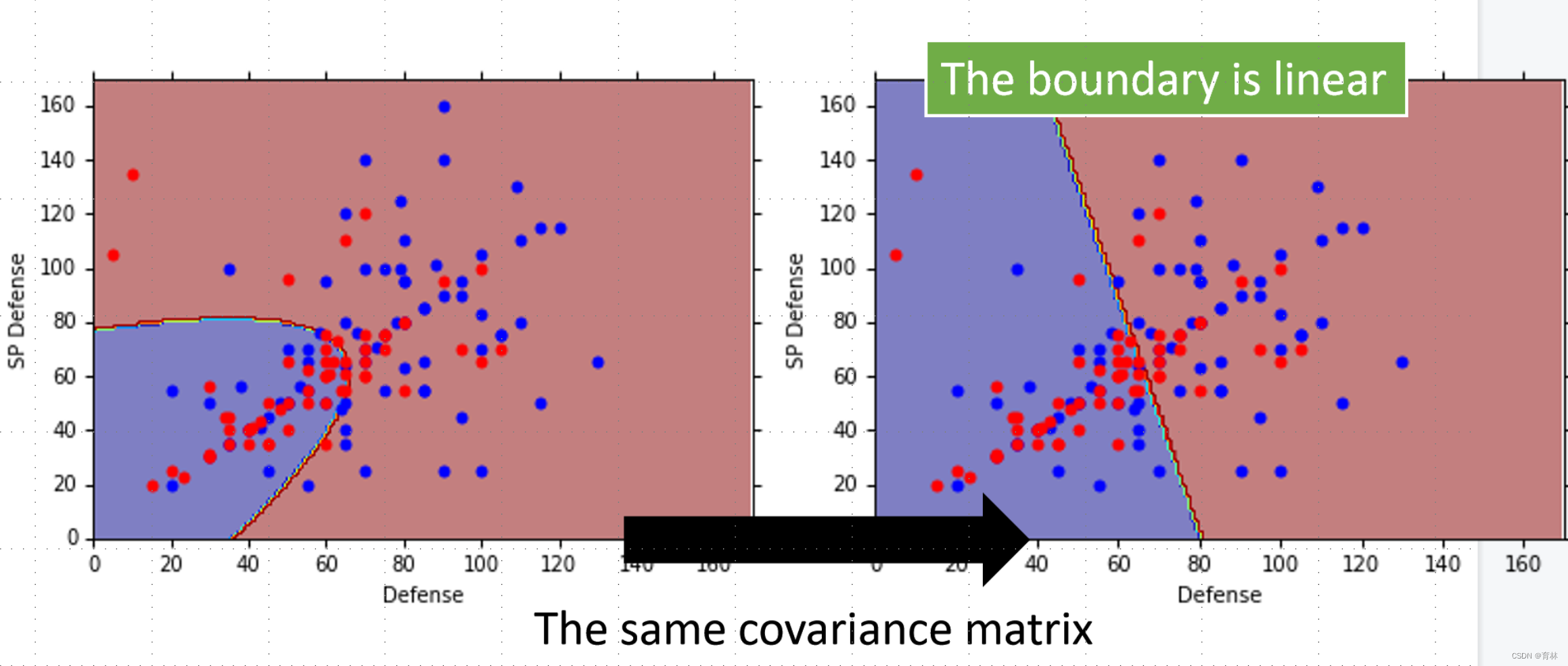

Three Steps
Function Set (Model):
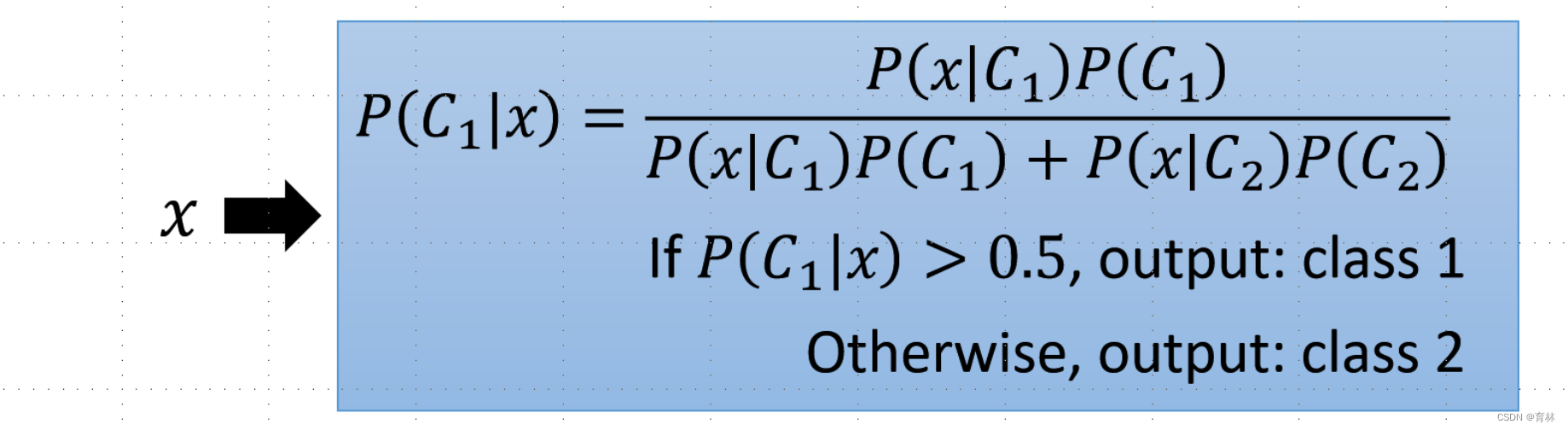
Goodness of a function:
The mean μ and covariance Σ that maximizing the likelihood (the probability of generating data)
Find the best function: easy
Probability Distribution

Posterior Probability:
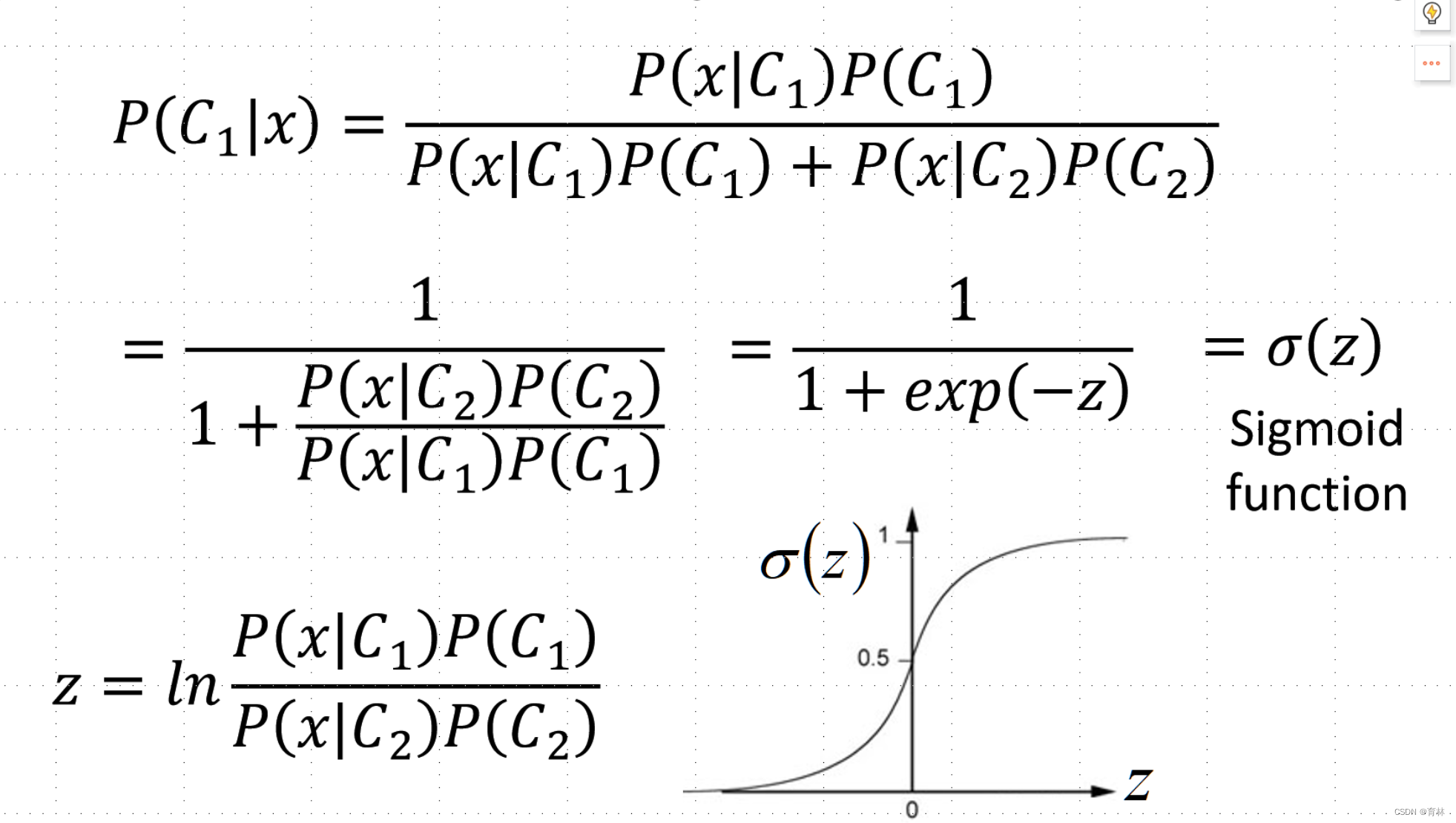
二、Classification: Logistic Regression
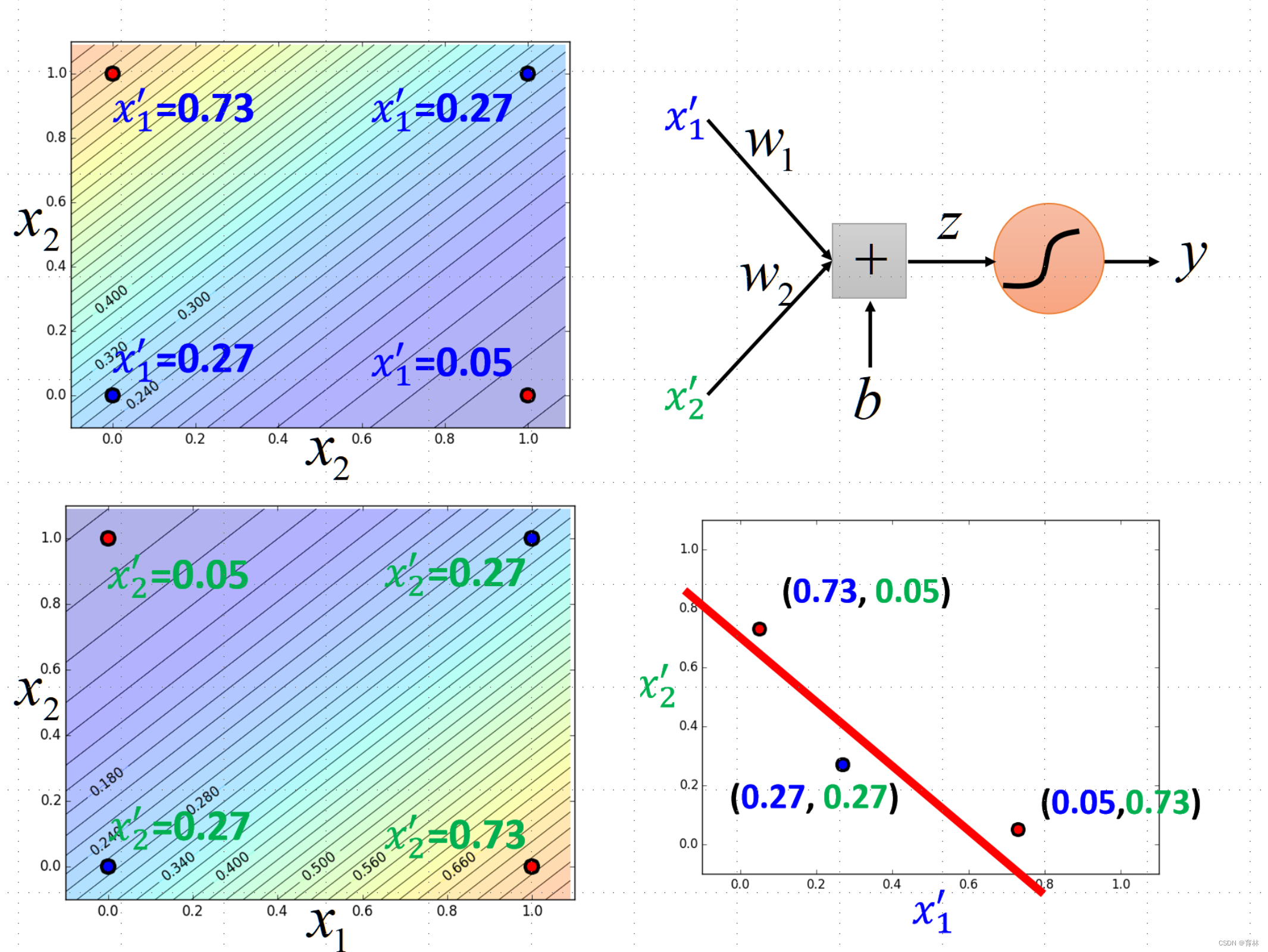
Step 1: Function Set

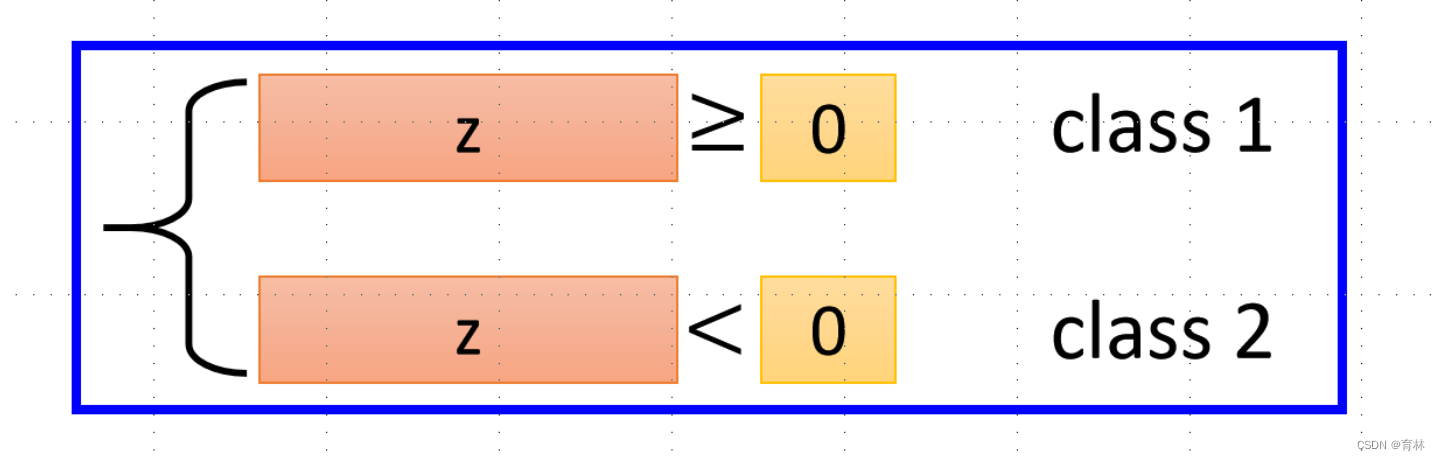
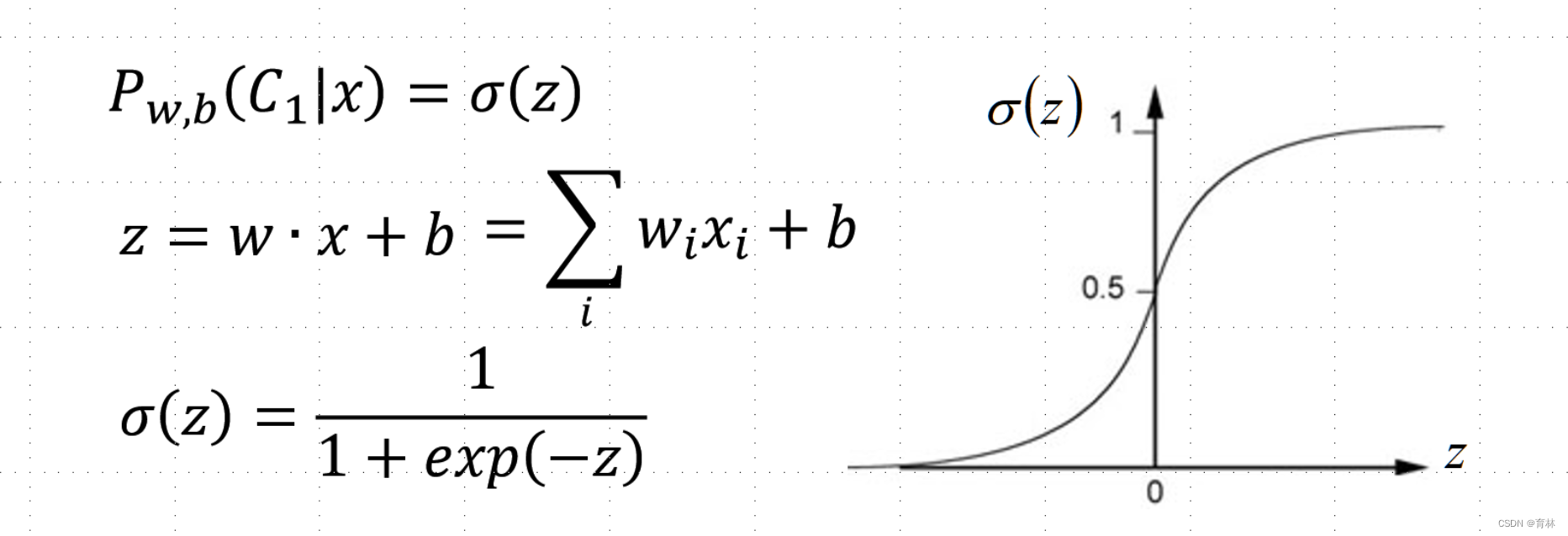
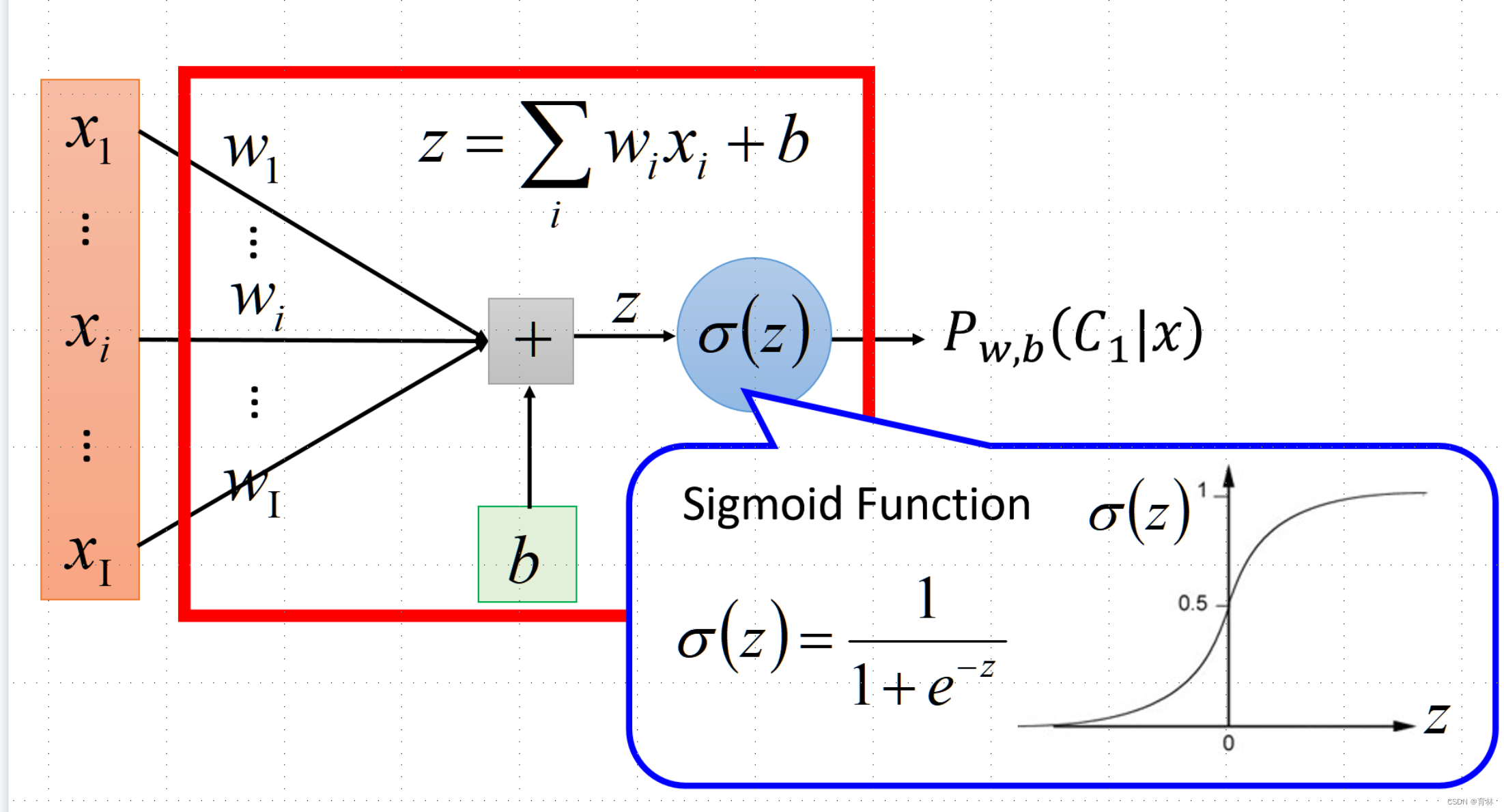
Step 2: Goodness of a Function





Step 3: Find the best function
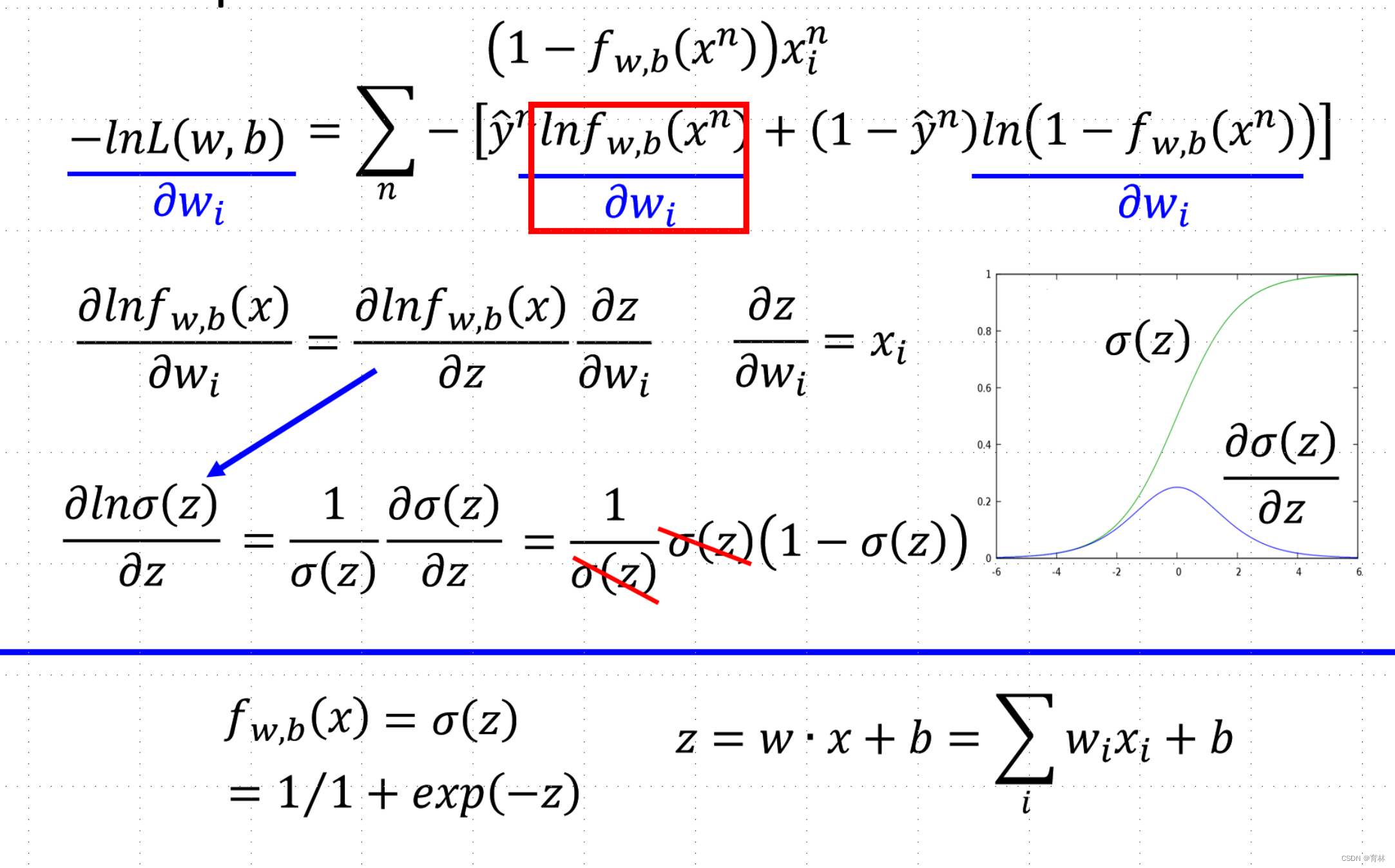


Logistic Regression + Square Error


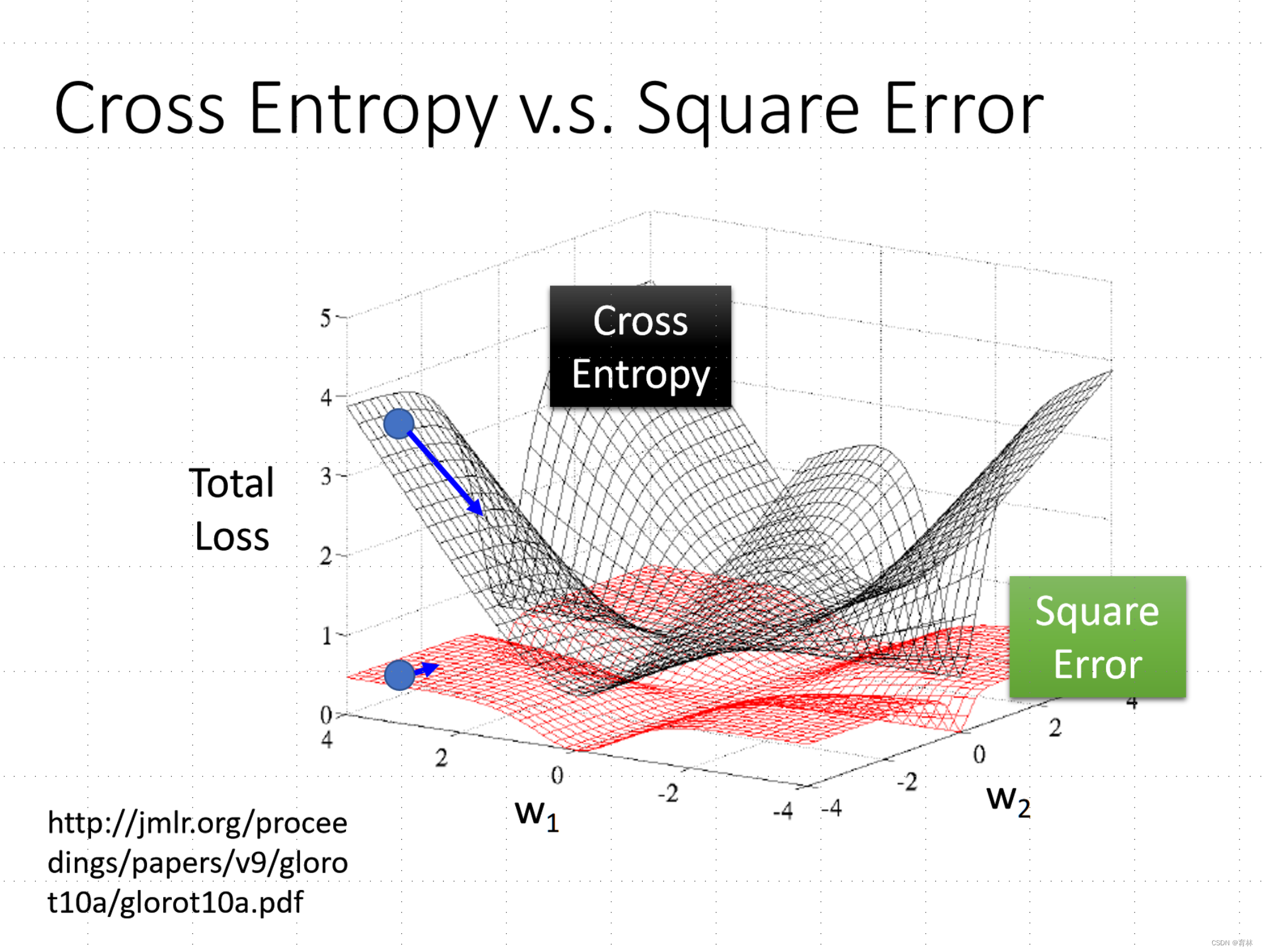

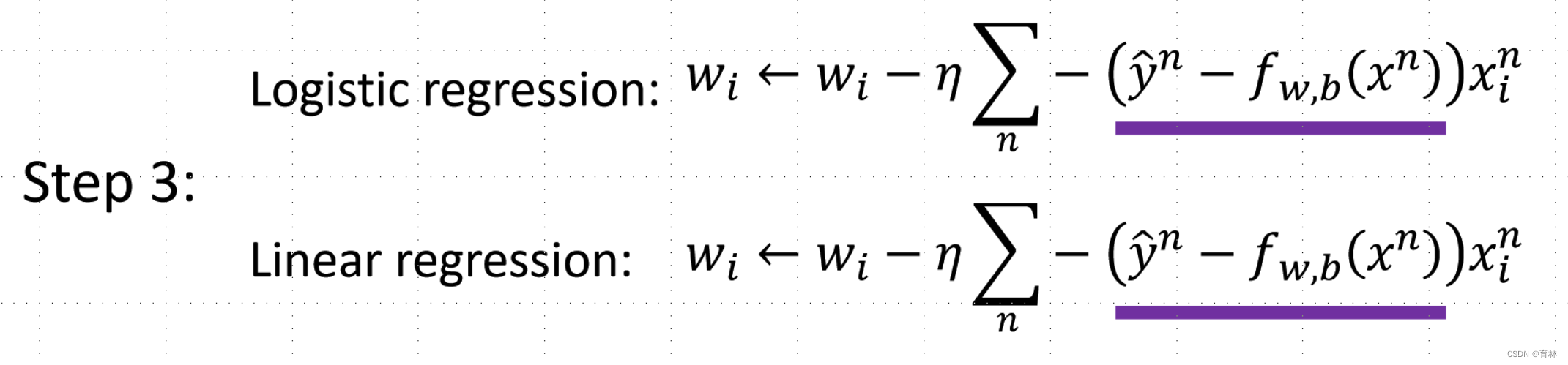
Generative v.s. Discriminative
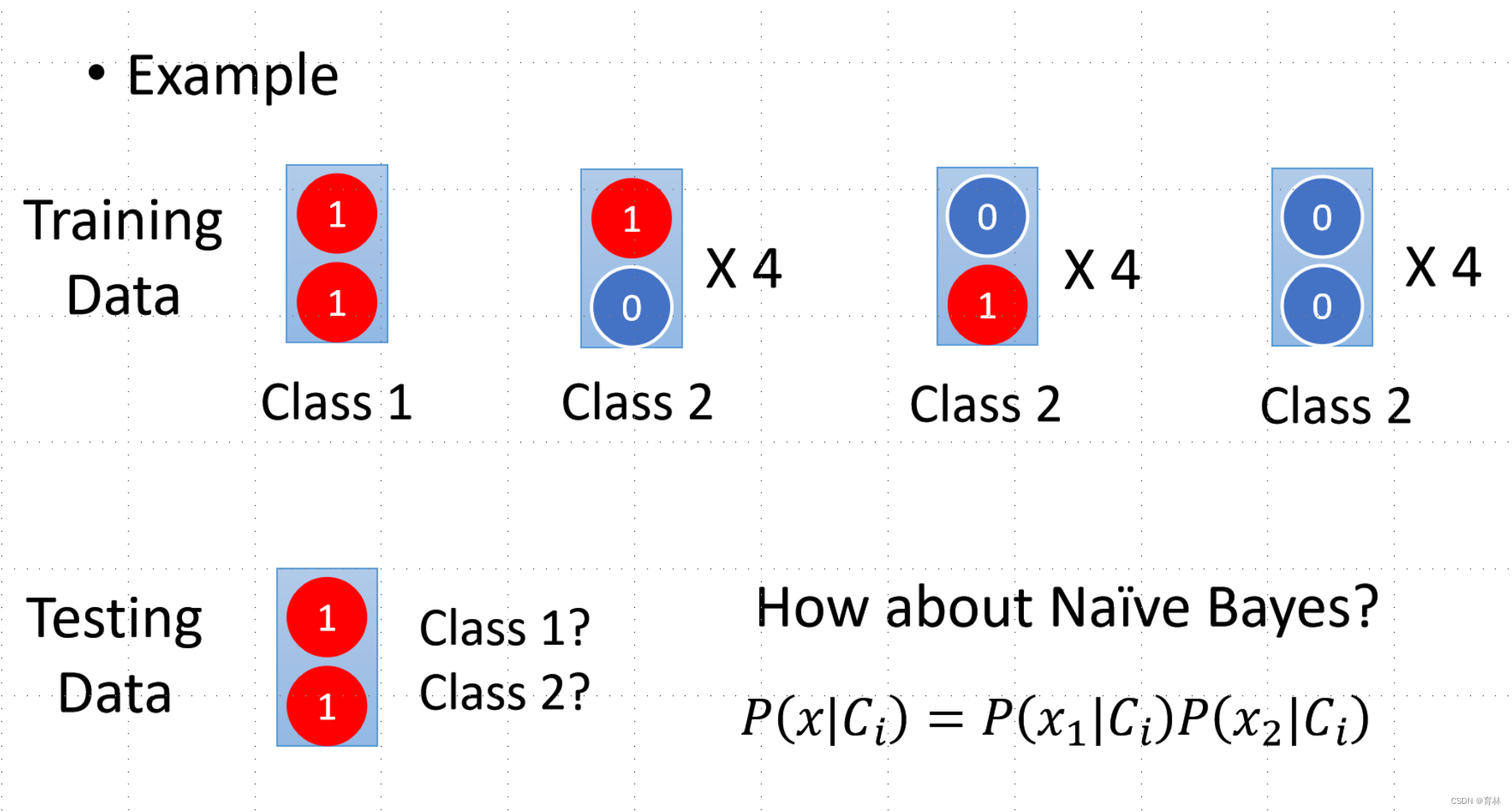
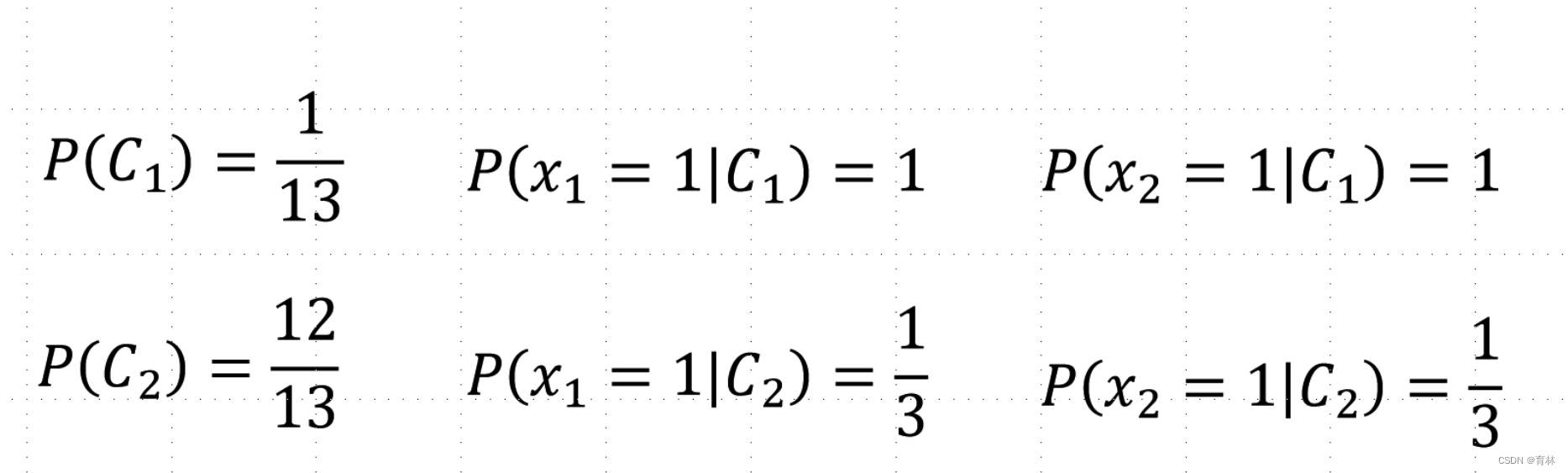

Usually people believe discriminative model is better
Benefit of generative model
With the assumption of probability distribution
less training data is needed
more robust to the noise
Priors and class-dependent probabilities can be estimated from different sources.
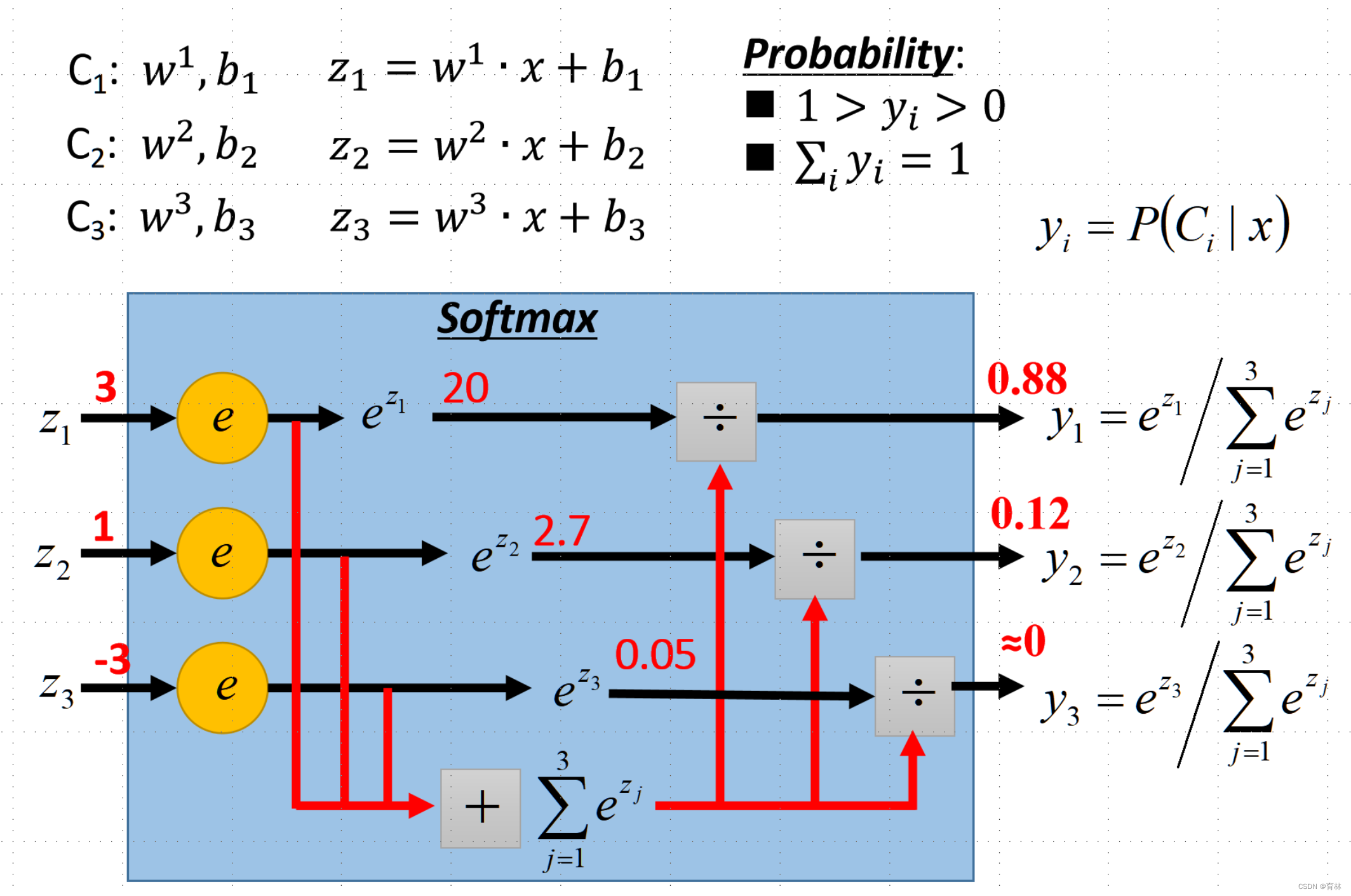
Multi-class Classification
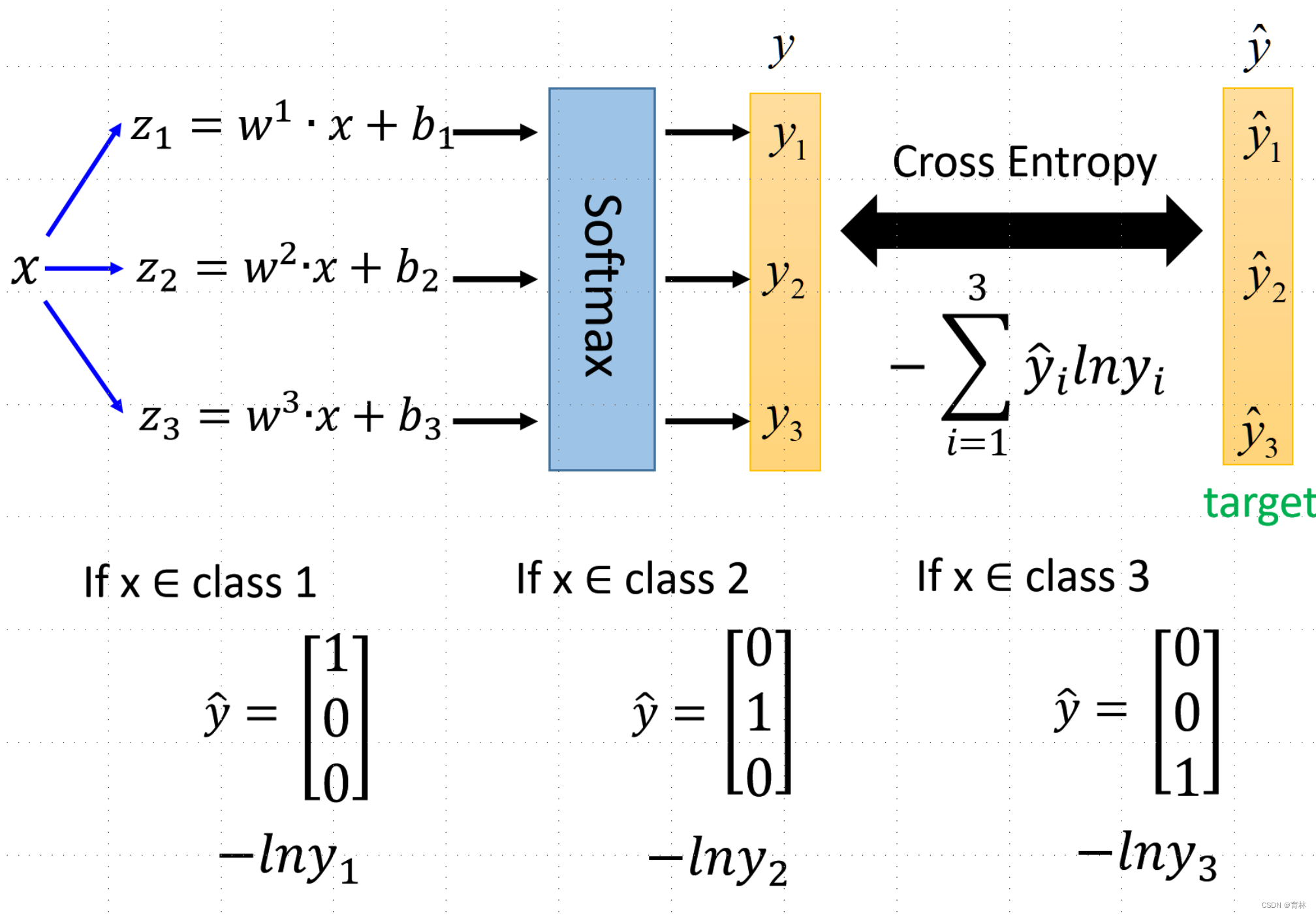
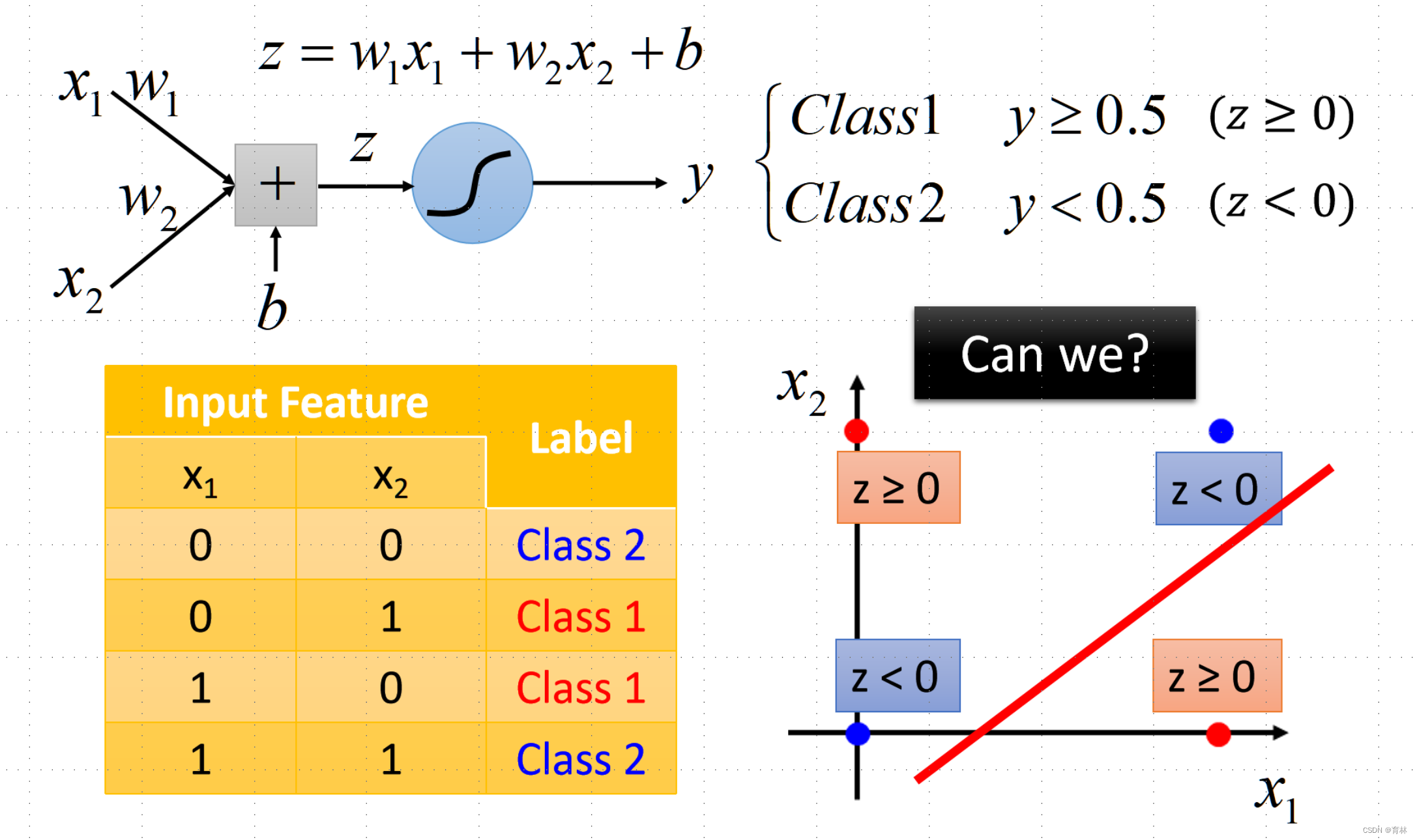
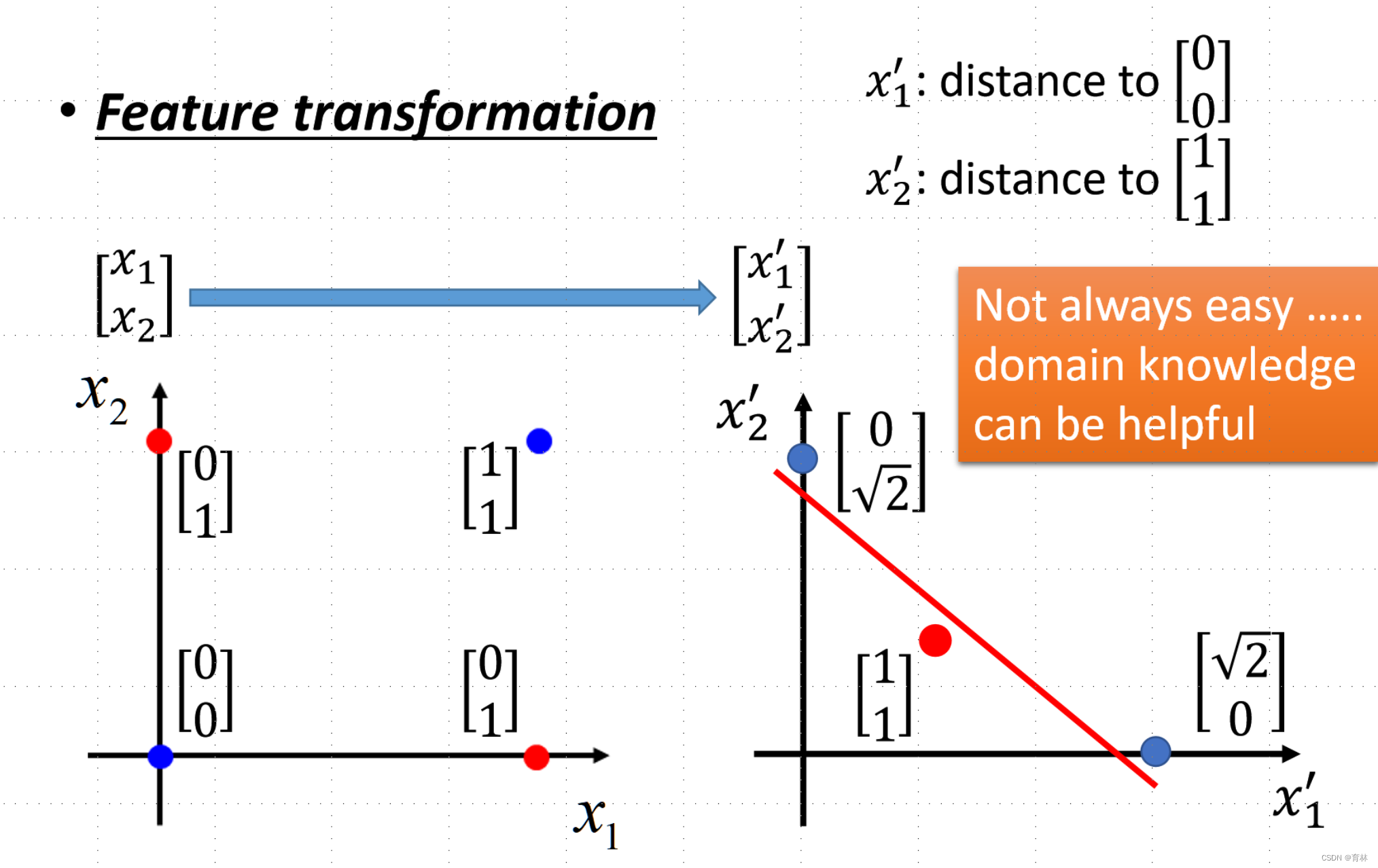
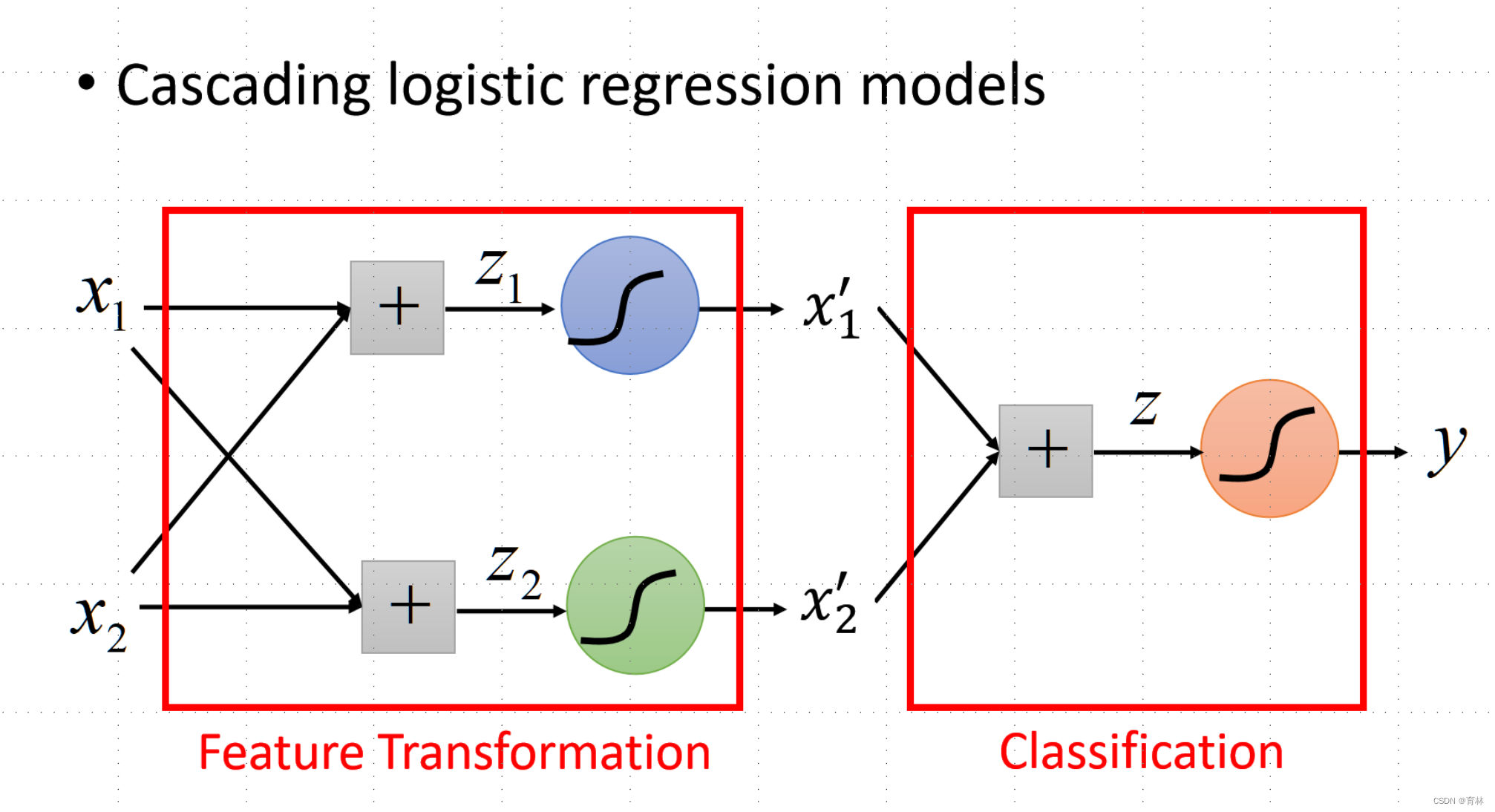
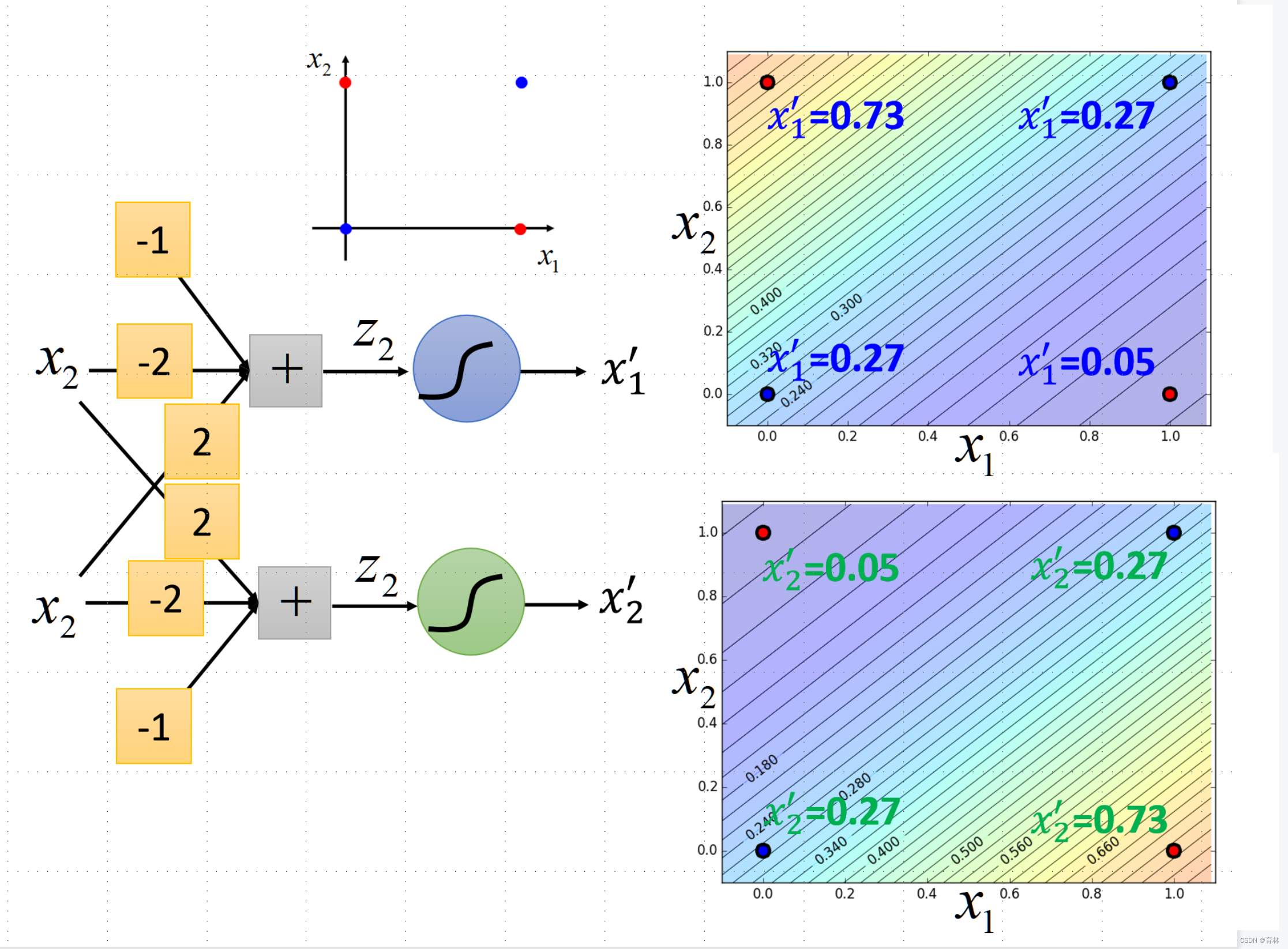
Limitation of Logistic Regression