
实战项目:保险行业用户分类
迪丽瓦拉
2025-06-01 21:02:15
0次
这里写目录标题
- 1、项目介绍
- 1.1 行业背景
- 1.2 数据介绍
- 2、代码实现
- 导入数据
- 探索数据
- 处理列标签名异常
- 创建自定义翻译函数
- 探索用户基本信息
- 自定义探索特征频率函数
- 探索家庭成员字段信息
- 探索疾病相关字段
- 自定义函数筛选相关性高于某个值的字段
- 探索投资相关字段
- 探索家庭收入
- 探索所处地区情况
- 数据清洗
- 删除特征
- 删除重复值
- 划分训练集与测试集
- 填充缺失值
- 填充缺失值
- 填充众数
- 替换填充
- 对测试集进行填充(总结)
- 转码
- 0-1转码
- 哑变量转码
- 对测试集进行转码(总结)
- 初步建模
- 网格搜索找最优参数
- 模型评估
- 输出规则
- 3、输出结果分析
1、项目介绍
项目目的:决策树建模,对保险行业用户进行分类,找到最具有购买倾向的用户,从而进行促销
1.1 行业背景
介绍发展现状和趋势变化(宏观、业界、社会)
保险行业衡量指标:
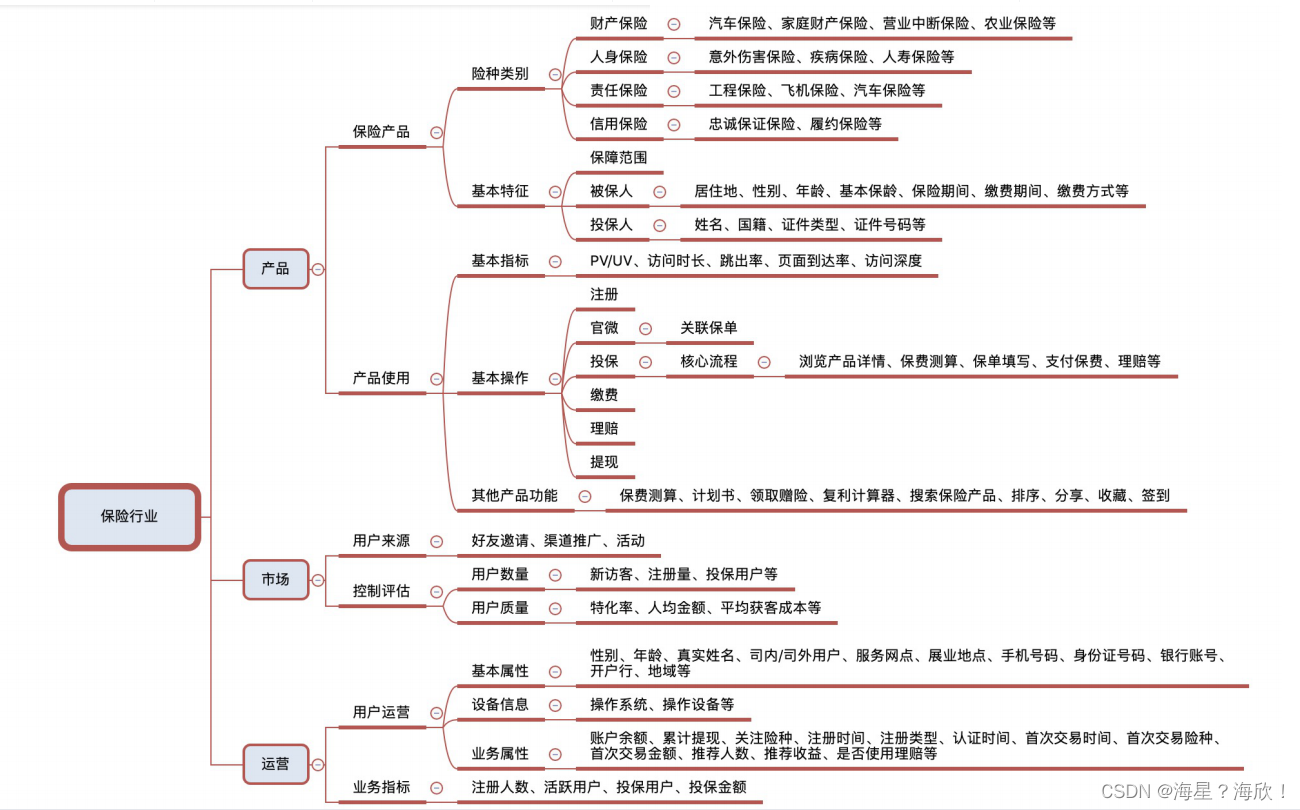
1.2 数据介绍
数据-提取码1111
数据字典-提取码1111
数据来源:某保险公司,要推销某款产品
商业目的:为该产品做用户画像,找到最具有购买倾向的人群进行营销
数据有76个字段,要处理。数据信息分成几块信息:
基本信息:
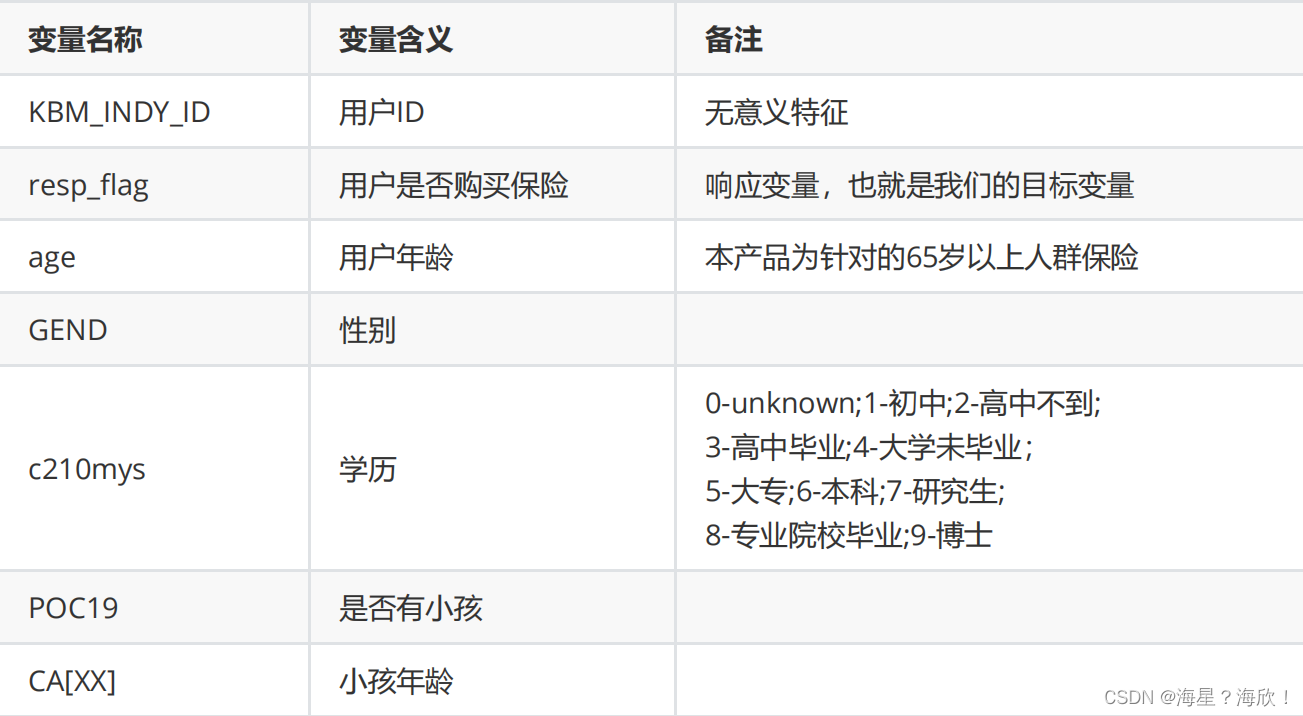
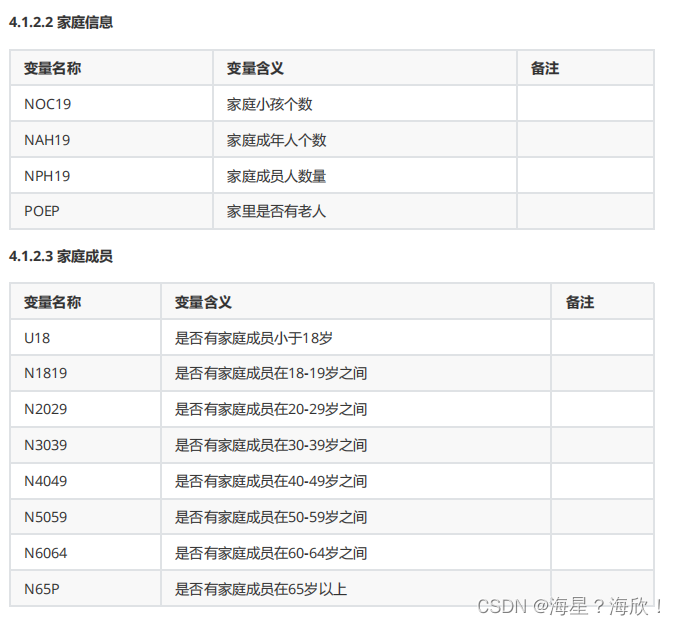
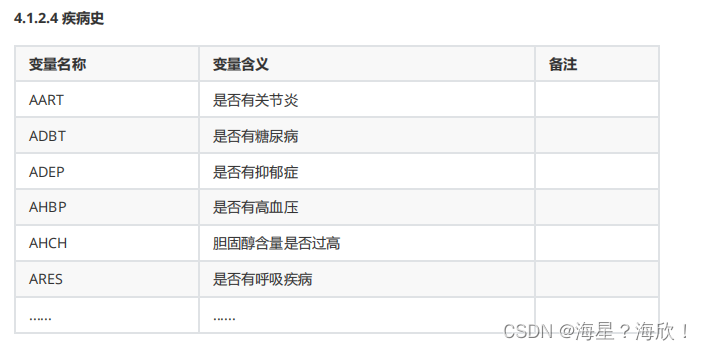
金融信息、个人习惯、家庭状况、居住城市等这几方面的信息
接下来的处理:判断哪些特征很可能与用户是否购买保险有相关关系,结合业务经验,通过数据可视化,特征工程等方法,探索哪些特征更重要
流程:
-
导入数据,观察
了解数据样本和特征个数,基本信息,检查是否有重复值 -
探索数据,数据可视化
用户年龄分布情况,用户年龄、性别、学习分别与购买保险之间的关系
缺失值填充方案
- 转码方案(01转码、哑变量、特殊需要替换的变量)
- 特殊:相同字段or要删除的字段(高度相关字段、无用字段)
空值填充、变量编码、模型建模
先切分训练集测试集,再填充缺失值,再转码
- 探索数据,数据可视化
#全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
2、代码实现
导入数据
data_00 = pd.read_csv('data/ma_resp_data_temp.csv')
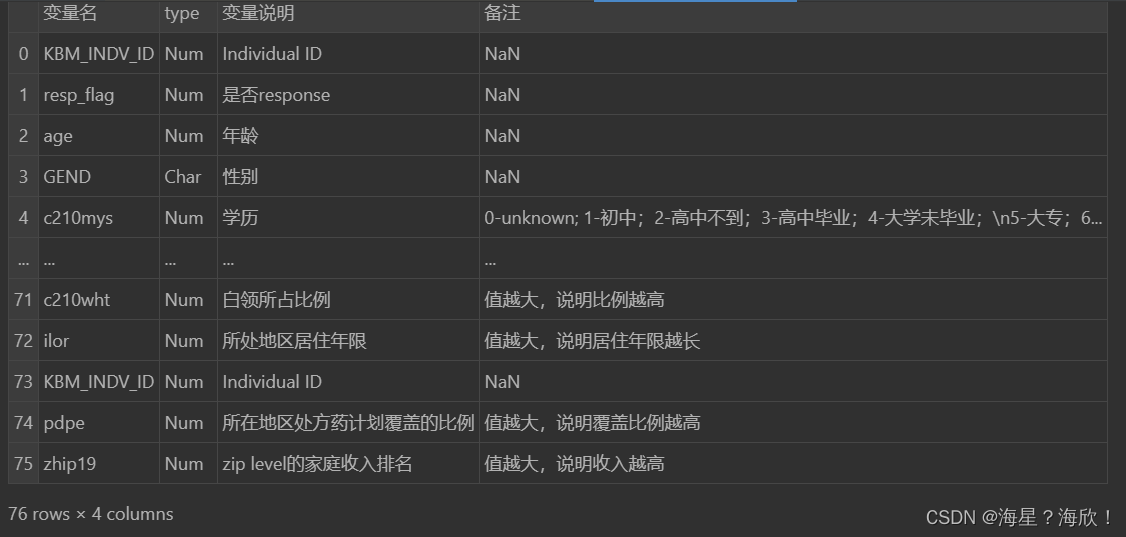
feature_dict = pd.read_excel('保险案例数据字典.xlsx')
data_01 = data_00.copy()#备份一下
探索数据
data_01.head()
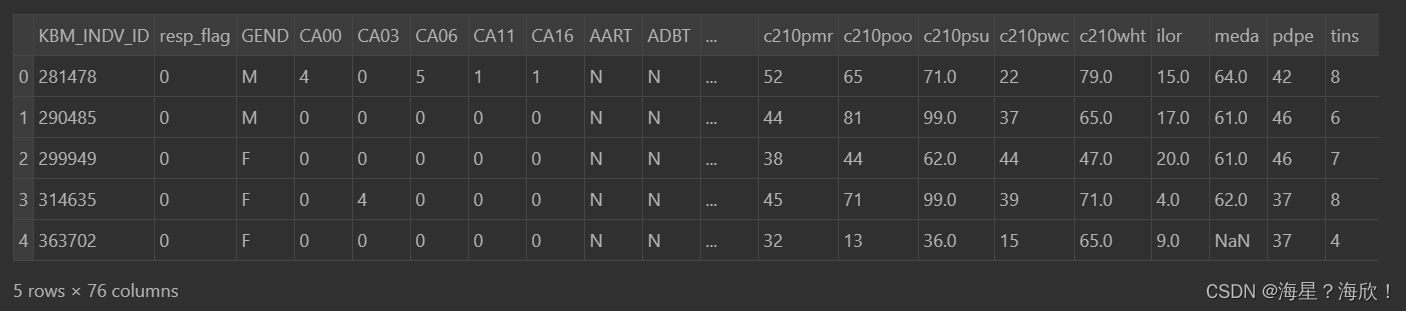
feature_dict #数据字典中是字段的信息
处理列标签名异常
问题:数据中字段和字典中的,不匹配
解决:判断data_01中列标签名是否都出现在数据字典的变量名中
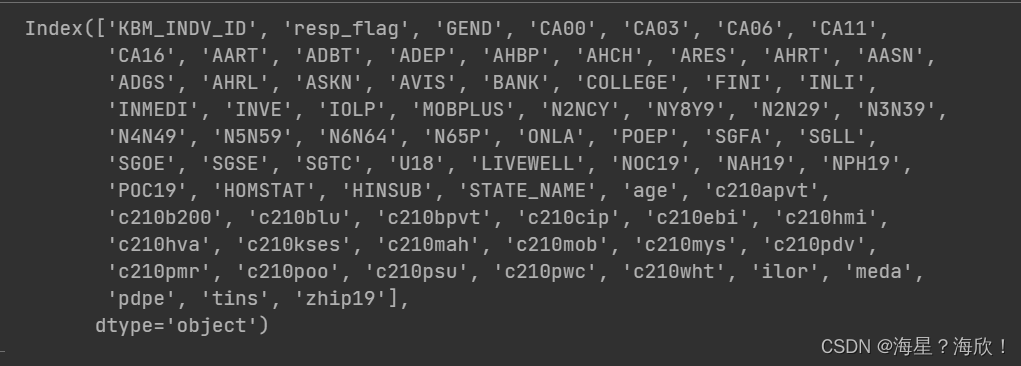
#处理列标签名异常
data_01.columns
feature_dict.变量名
#求补集(找出不匹配的)
np.setxor1d(data_01.columns,feature_dict.变量名)
#输出的结果是属于其中一个,但不属于另一个的特征

推测:N2029对应N2N29,以此类推
#数据表列标签
NY8Y9', 'N2N29', 'N3N39', 'N4N49', 'N5N59', 'N6N64'
#相互对应
#数据字典
'N1819', 'N2029','N3039','N4049', 'N5059','N6064'meda
# 删掉
data_01['meda'].nunique()#输出75,重复率高,直接删除
替换异常标签
a = ['NY8Y9', 'N2N29', 'N3N39', 'N4N49', 'N5N59', 'N6N64']
b = ['N1819', 'N2029','N3039','N4049', 'N5059','N6064']
# 要替换的列标签,做成映射字典
dic = dict(zip(a,b))
dic
#自定义要转化的向量化函数
def tran(x):if x in dic:return dic[x]else:return x
tran = np.vectorize(tran) #向量化#使用向量化函数替换异常表头
data_01.columns = tran(data_01.columns)
dic内容:

创建自定义翻译函数
提高探索数据效率,创建自定义翻译函数,通过映射字典的方式,替换DataFrame列标签名为中文
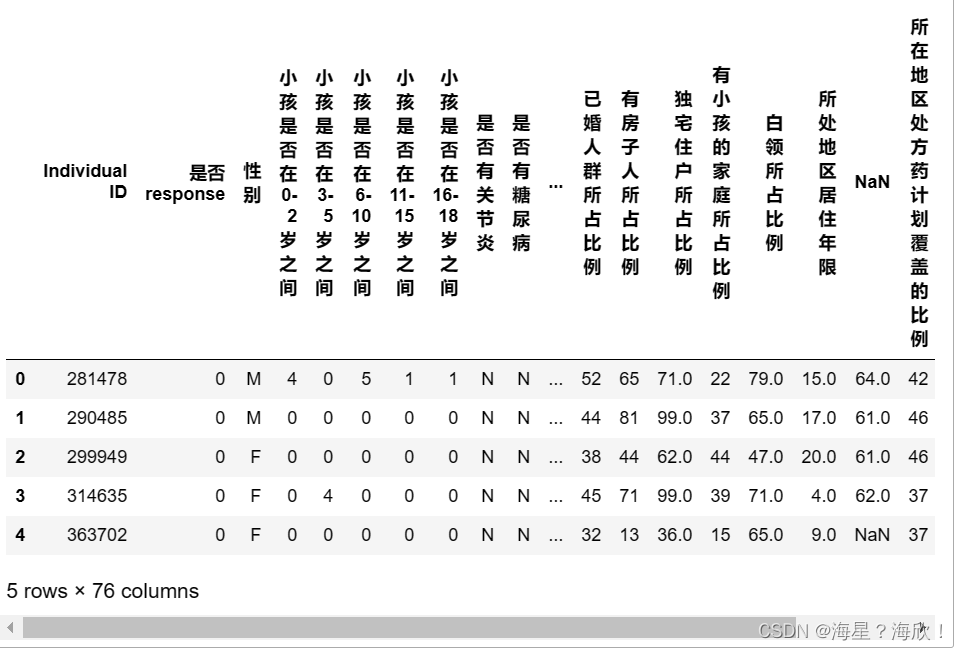
dic = {k:v for k,v in feature_dict[['变量名','变量说明']].values.reshape(-1,2)}def chinese(x):y = x.copy()#将输入进来的字段名通过字典映射的方式去对应y.columns = pd.Series(y.columns).map(dic)return y
chinese(data_01).head()
探索用户基本信息
feature_dict.变量名[:5]
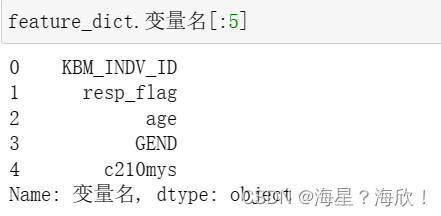
feature_dict.变量名[:5].tolist() #得到列表
#['KBM_INDV_ID', 'resp_flag', 'age', 'GEND', 'c210mys']
data_01[feature_dict.变量名[:5].tolist()].head()
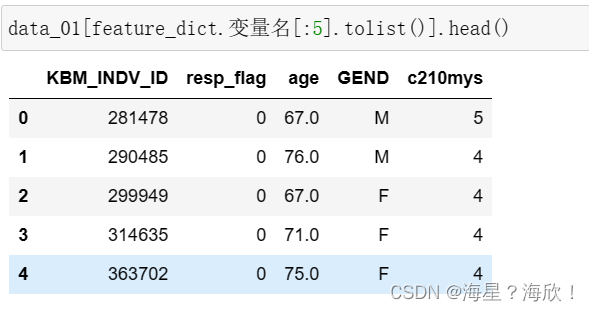
#将0_4列取出来并进行翻译
data0_4 = chinese(data_01[feature_dict.变量名[:5].tolist()])
data0_4.head()
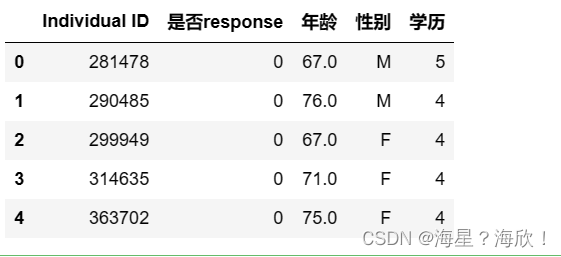
data0_4.info()
data0_4.isnull().sum()
自定义探索特征频率函数
输入一个DataFrame,输出每个特征的频数分布
def fre(x):for i in x.columns:print("字段名:",i)print("----------")print("字段数据类型:",x[i].dtype)print("----------------------------")print(x[i].value_counts()) #频数print("----------------------------")print("缺失值的个数:",x[i].isnull().sum())print("------------------------------------------------\n\n")
fre(data0_4)
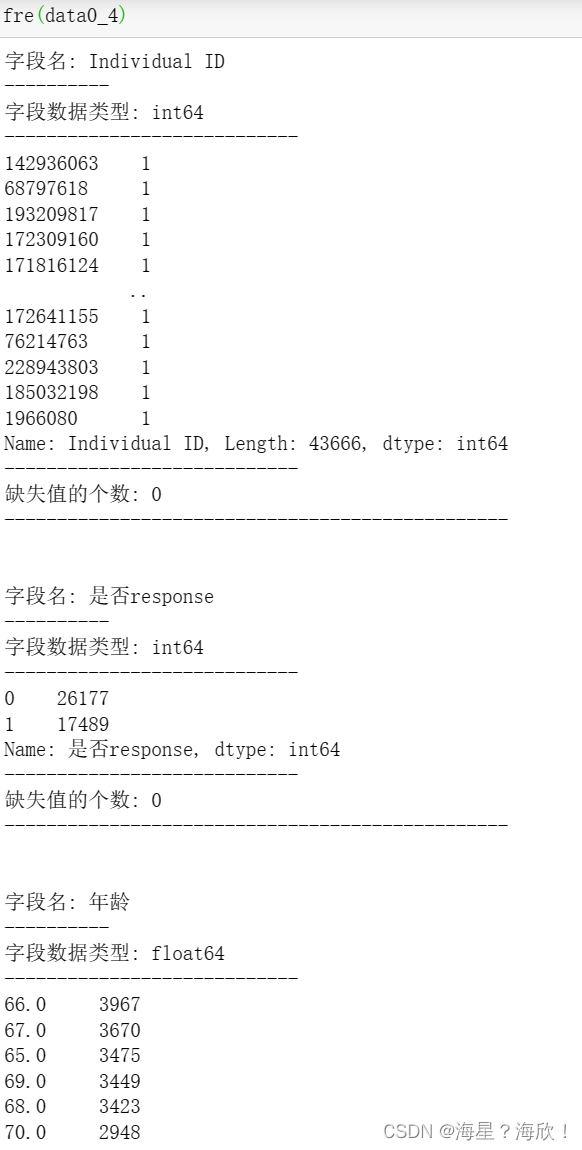
根据这些输出信息,在字典里进行备注,需不需要填充,删除,转码等操作?
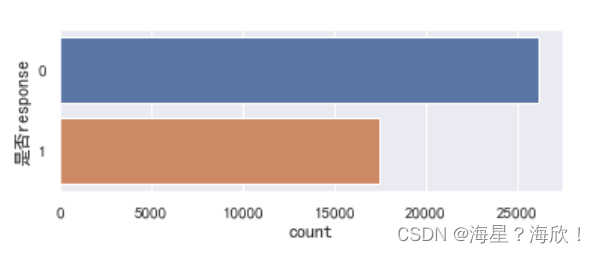
#条形图对目标列可视化一下
import seaborn as sns#中文编码
sns.set_style("darkgrid",{"font.sans-serif":['simhei','Droid Sans Fallback']})
#sns.set()plt.figure(1,figsize=(6,2))
sns.countplot(y='是否response',data=data0_4)
plt.show()
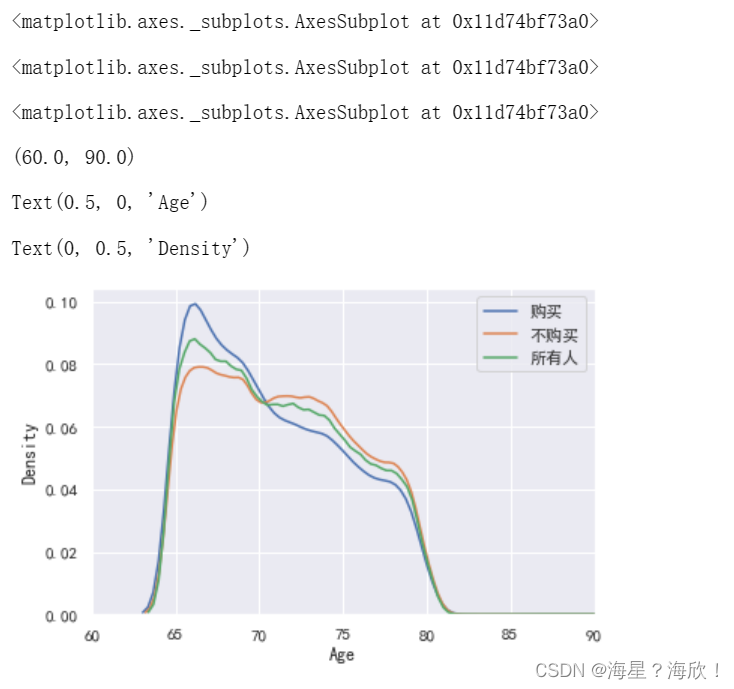
#根据年龄 概率密度图
#针对购买人群、非购买人群,所有人群的概率密度图
sns.kdeplot(data0_4.年龄[data0_4.是否response==1],label='购买')
sns.kdeplot(data0_4.年龄[data0_4.是否response==0],label='不购买')
sns.kdeplot(data0_4.年龄.dropna(),label='所有人')plt.xlim([60,90])
plt.xlabel('Age')
plt.ylabel('Density')
探索家庭成员字段信息
#将5_22列取出来并进行翻译
data5_22 = chinese(data_01[feature_dict.变量名[5:23].tolist()])
data5_22.head()
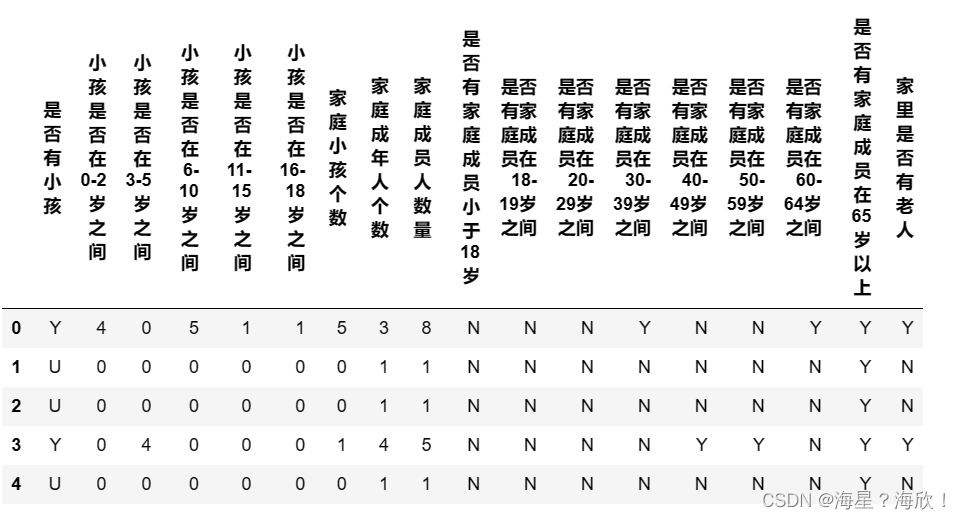
fre(data5_22)

探索疾病相关字段
#将23_35列取出来并进行翻译
data23_35 = chinese(data_01[feature_dict.变量名[23:35].tolist()])
data23_35.head()
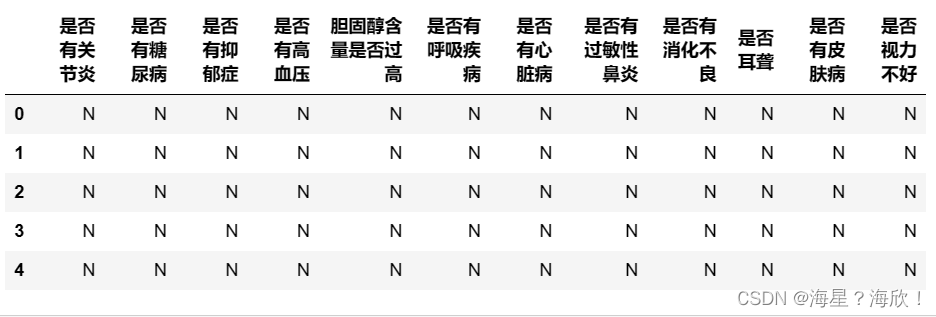
fre(data23_35)
#0 1 转码
def zero_one(x):for i in x.columns:if x[i].dtype == 'object':dic = dict(zip(list(x[i].value_counts().index),range(x[i].nunique())))x[i] = x[i].map(dic)return x
zero_one(data23_35).corr()
23-35字段全是,是否的结果,进行01转码

import matplotlib.pyplot as plt
import seaborn as sns#画一个热力图
sns.heatmap(zero_one(data23_35).corr(),cmap='Blues')
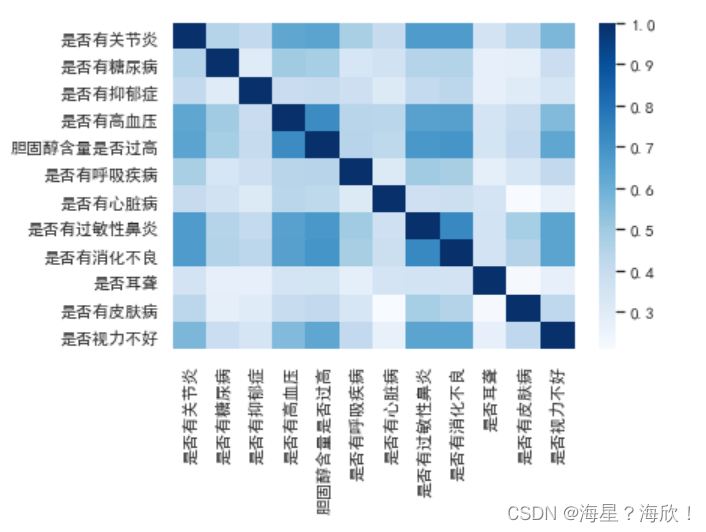
自定义函数筛选相关性高于某个值的字段
筛选相关性高于0.65的字段
def higt_cor(x,y=0.65):data_cor = (x.corr()>y)a=[]for i in data_cor.columns:if data_cor[i].sum()>=2:a.append(i)return a #这些是我们要考虑删除的
higt_cor(data23_35) #删除这三个:是否有关节炎 胆固醇含量是否过高 是否有过敏性鼻炎

探索投资相关字段
#将35_41列取出来并进行翻译
data35_41 = chinese(data_01[feature_dict.变量名[35:41].tolist()])
data35_41.head()
fre(data35_41)
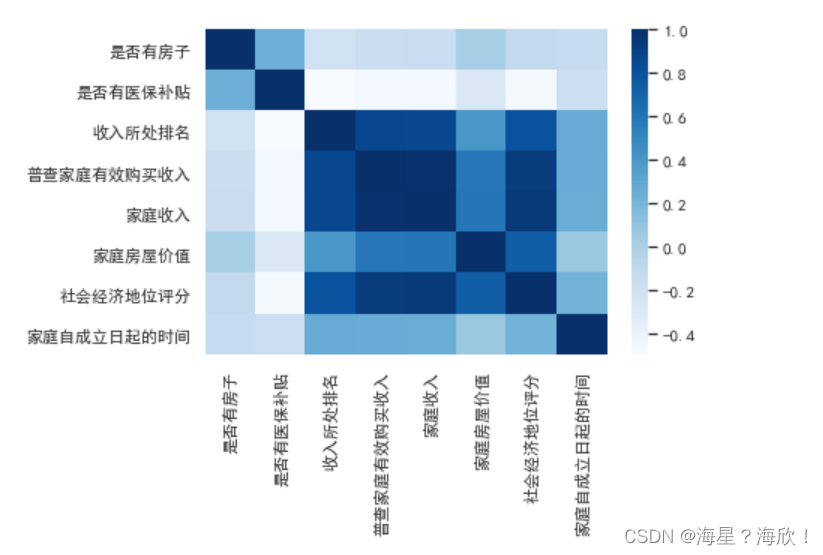
sns.heatmap(zero_one(data35_41).corr(),cmap='Blues')
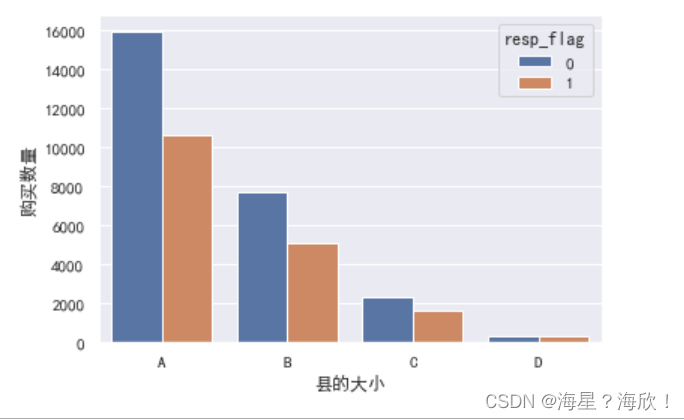
sns.countplot(x='N2NCY',hue='resp_flag',data=data_01)
plt.xlabel('县的大小')
plt.ylabel('购买数量')
探索家庭收入
#将51_59列取出来并进行翻译
data51_59 = chinese(data_01[feature_dict.变量名[51:59].tolist()])
data51_59.head()
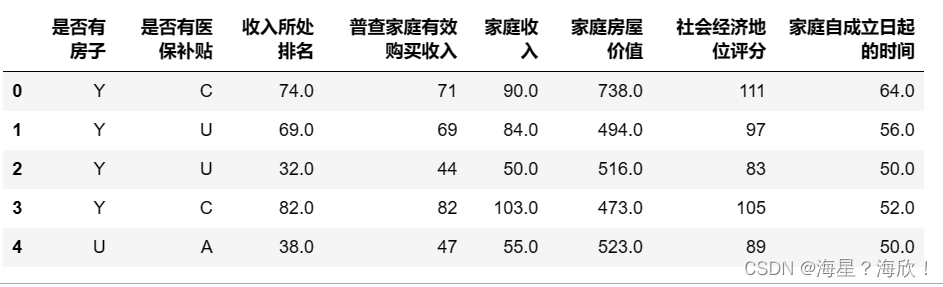
fre(data51_59)
sns.heatmap(zero_one(data51_59).corr(),cmap='Blues')
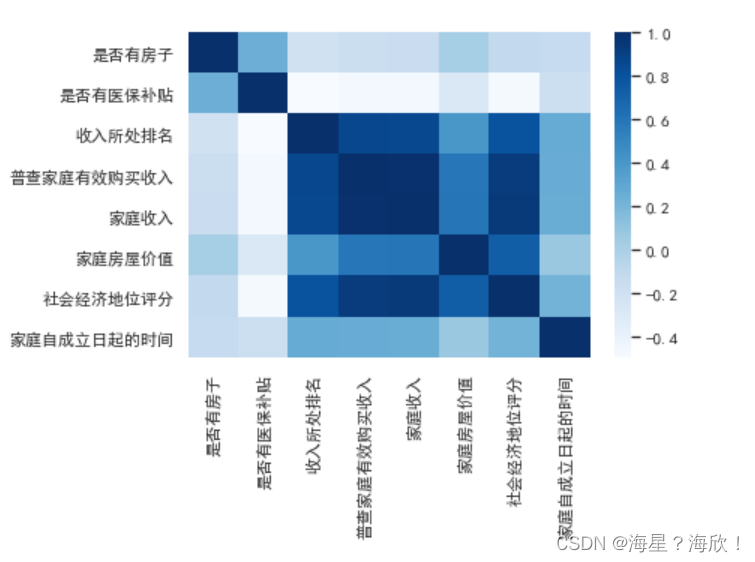
higt_cor(data51_59)
#输出:['收入所处排名', '普查家庭有效购买收入', '家庭收入', '家庭房屋价值', '社会经济地位评分']
探索所处地区情况
#将59列之后取出来并进行翻译
data59 = chinese(data_01[feature_dict.变量名[59:].tolist()])
data59.head()
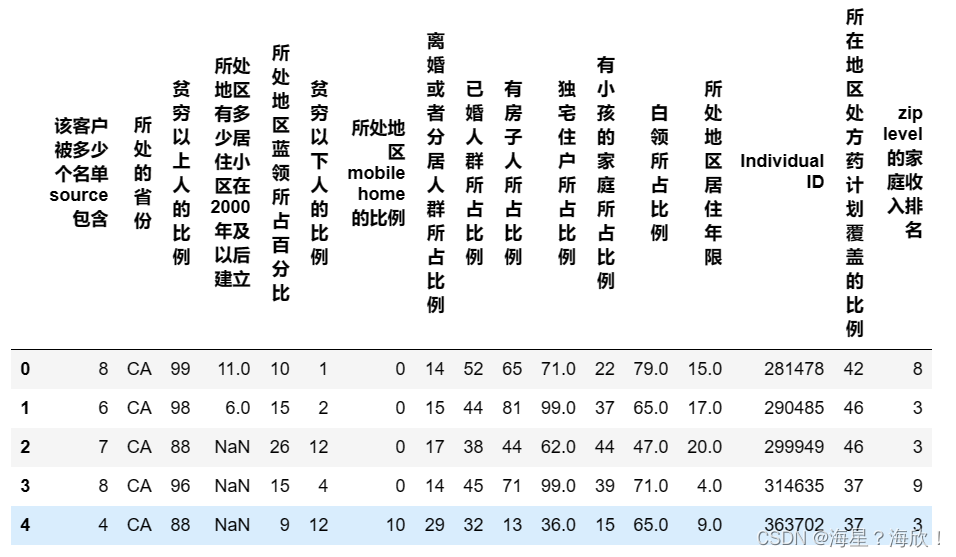
fre(data59)
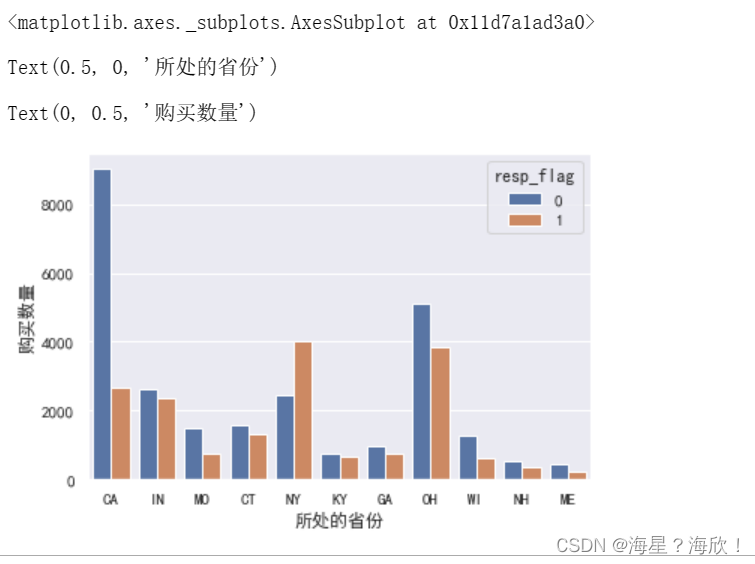
sns.countplot(x='STATE_NAME',hue='resp_flag',data=data_01)
plt.xlabel('所处的省份')
plt.ylabel('购买数量')
a = chinese(data_01[["c210apvt","c210blu","c210bpvt","c210mob","c210wht","zhip19"]])
sns.heatmap(a.corr(),cmap='Blues')
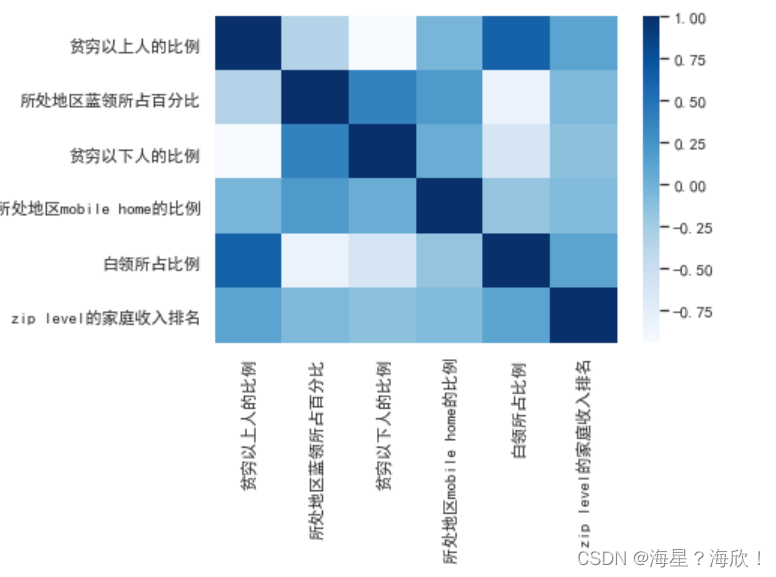
higt_cor(data59)
#输出:['贫穷以上人的比例', '已婚人群所占比例', '有房子人所占比例', '独宅住户所占比例']
sns.heatmap(data59.corr(),cmap='brg')
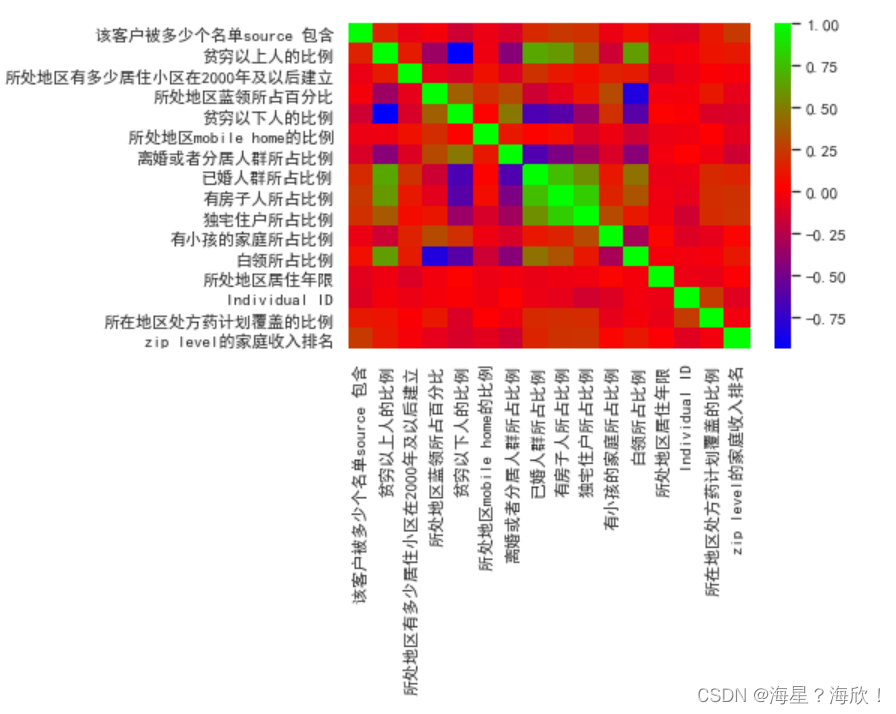
要做的处理记录在字典中
数据清洗
data_02 = data_01.copy()
data_02.shape
#(43666, 76)
删除特征
del_col = ["KBM_INDV_ID","U18","POEP","AART","AHCH","AASN","COLLEGE","INVE","c210cip","c210hmi","c210hva","c210kses","c210blu","c210bpvt","c210poo","KBM_INDV_ID","meda"]data_02 = data_02.drop(columns=del_col)
data_02.shape #(43666, 60)
删除重复值
data_02.drop_duplicates().shape
#(43666, 60)
划分训练集与测试集
一定要先划分数据集再填充、转码
from sklearn.model_selection import train_test_splity = data_02.pop('resp_flag') #标签
X = data_02 #特征Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=100)
Xtrain_01=Xtrain.copy()
Xtest_01=Xtest.copy()
Ytrain_01=Ytrain.copy()
Ytest_01=Ytest.copy()
填充缺失值
填充缺失值
fil = ["age","c210mah","c210b200","c210psu","c210wht","ilor"]Xtrain_01[fil].median()
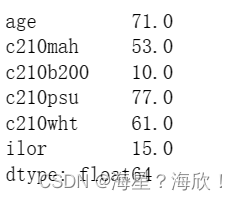
dic = dict(zip(Xtrain_01[fil].median().index,Xtrain_01[fil].median()))
dic

#向训练集填充中位数
Xtrain_01 = Xtrain_01.fillna(dic)
填充众数
mod = ["N1819","ASKN","MOBPLUS","N2NCY","LIVEWELL","HOMSTAT","HINSUB"]dic_mod = dict(zip(Xtrain_01[mod].mode().columns,Xtrain_01[mod].iloc[0,:]))Xtrain_01 = Xtrain_01.fillna(dic_mod)
替换填充
Xtrain_01['N6064'] = Xtrain_01['N6064'].replace('0','N') #0 替换成 N
Xtrain_01.isnull().sum()[Xtrain_01.isnull().sum()!=0]
#Series([], dtype: int64)
对测试集进行填充(总结)
# 需要填的字段
fil = ["age","c210mah","c210b200","c210psu","c210wht","ilor"]#填充中位数--测试集dic = dict(zip(Xtest_01[fil].median().index,Xtest_01[fil].median()))Xtest_01 = Xtest_01.fillna(dic) # #填充众数--测试集
mod = ["N1819","ASKN","MOBPLUS","N2NCY","LIVEWELL","HOMSTAT","HINSUB"]dic_mod = dict(zip(Xtest_01[mod].mode().columns,Xtest_01[mod].iloc[0,:]))Xtest_01 = Xtest_01.fillna(dic_mod) # #替换填充
Xtest_01['N6064'] = Xtest_01['N6064'].replace('0','N') Xtest_01.isnull().sum()[Xtest_01.isnull().sum() !=0]
#Series([], dtype: int64)
转码
encod_col = pd.read_excel('保险案例数据字典_清洗.xlsx',sheet_name=2)
encod_col.head()
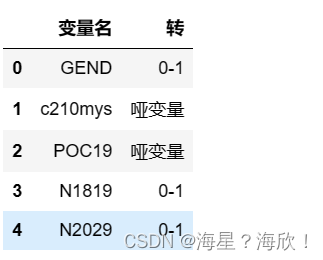
# 查看Xtrain_01中object类型
object_tr =Xtrain_01.describe(include='O').columns
object_tr

#检查一下转码的目标是否出现
np.setdiff1d(object_tr,encod_col['变量名'])
#array([], dtype=object)
0-1转码
# 获取0-1 转码的变量名
z_0_list = encod_col[encod_col['转']=='0-1'].变量名
z_0_list.head()

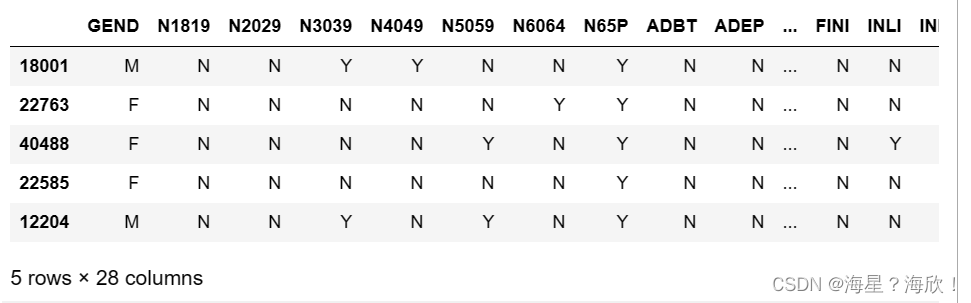
Xtrain_02 = Xtrain_01[z_0_list]
Xtrain_02.head()
#sklearn的预处理模块
from sklearn.preprocessing import OrdinalEncoder#fit_transform 直接转
new_arr = OrdinalEncoder().fit_transform(Xtrain_02)
new_arr

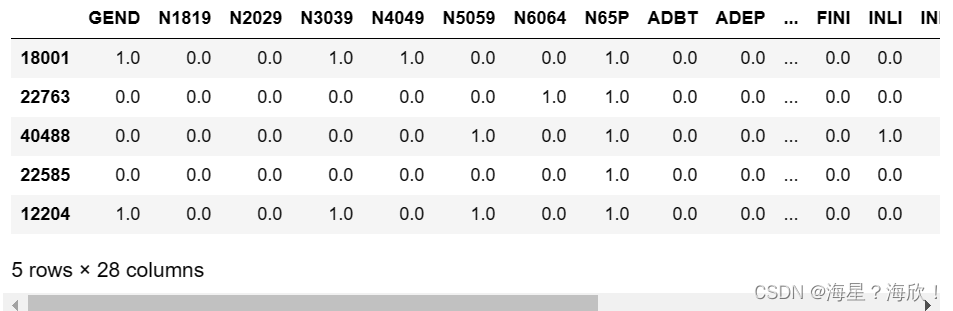
# columns 设置表头为原来的 index 索引也是原来
Xtrain_02 = pd.DataFrame(data=new_arr,columns=Xtrain_02.columns,index=Xtrain_02.index)
Xtrain_02.head()
将转好的Xtrain_02 0-1编码变量 替换掉Xtrain_01
Xtrain_01[z_0_list] = Xtrain_02
Xtrain_01.head()
哑变量转码
#获取哑变量---转码的变量名o_h_list = encod_col[encod_col['转']=='哑变量'].变量名
o_h_list

Xtrain_01[o_h_list].head()
o_h_01 = ['c210mys','LIVEWELL'] #非字符型的变量
o_h_02 = [i for i in o_h_list if i not in o_h_01] #字符类型的变量#先转o_h_02
Xtrain_02 = Xtrain_01.copy()
chinese(Xtrain_02[o_h_02]).head()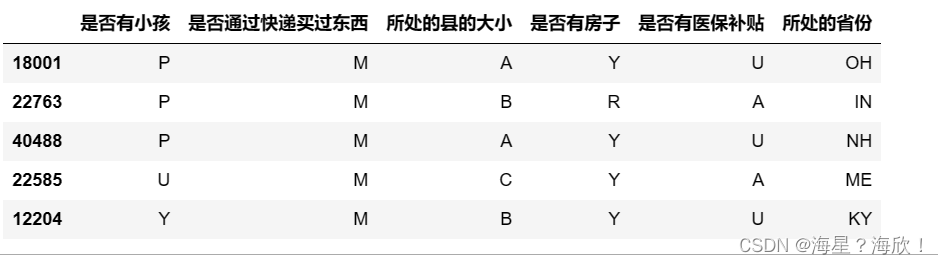
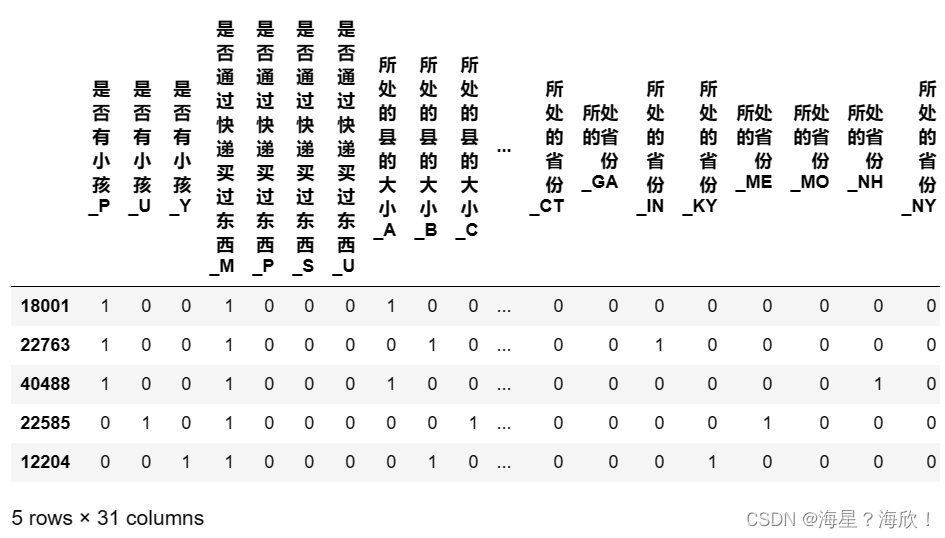
Xtrain_02 = pd.get_dummies(chinese(Xtrain_02[o_h_02]))
Xtrain_02.head()
#w我们再转 o_h_01
Xtrain_03 = Xtrain_01.copy()#转成字符类型
Xtrain_03 = Xtrain_03[o_h_01].astype(str)
#转化覆盖
Xtrain_03 = pd.get_dummies(chinese(Xtrain_03[o_h_01]))Xtrain_03.head()
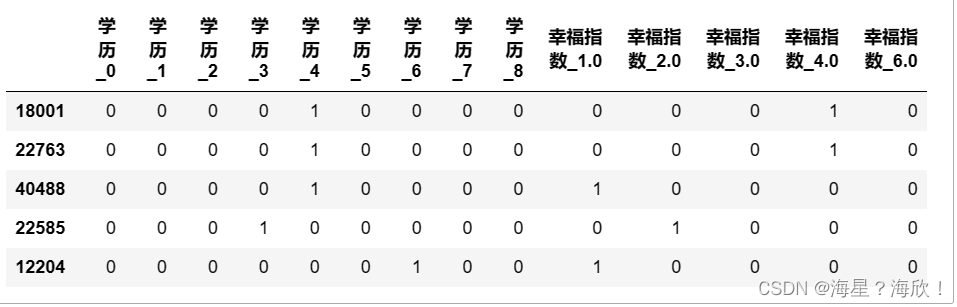
Xtrain_02 Xtrain_03 是转好的 先删除原转码的字段再将转好的插入到数据集中
# Xtrain_04 删除原转码的字段
Xtrain_04 = Xtrain_01.copy()
Xtrain_04 = chinese(Xtrain_04.drop(columns=o_h_01+o_h_02))
Xtrain_04.head()
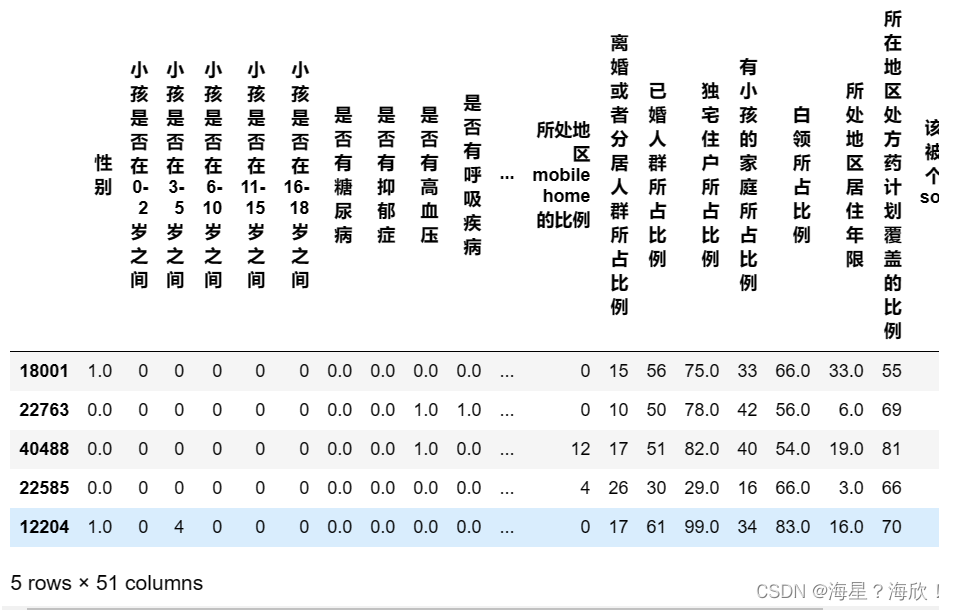
Xtrain_04.shape #(30566, 51)Xtrain_02.shape #字符的哑变量
#(30566, 31)Xtrain_03.shape #非字符的哑变量
#(30566, 14)
#将 Xtrain_04 Xtrain_02 Xtrain_03 合并
Xtrain_05 = pd.concat([Xtrain_04,Xtrain_02,Xtrain_03],axis=1)
Xtrain_05.shape
#(30566, 96)
Xtrain_05.head()
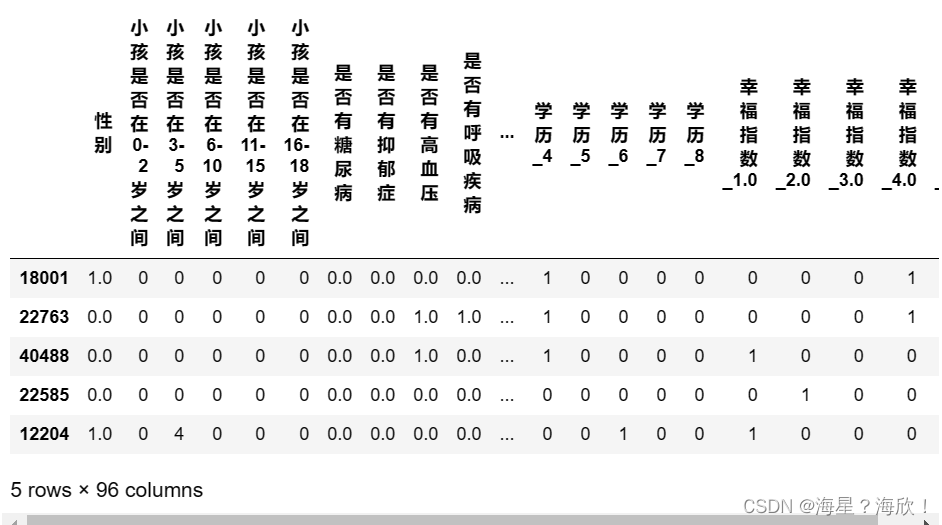
对测试集进行转码(总结)
0-1 转码总结
#获取需要转码的字段
encod_col = pd.read_excel('保险案例数据字典_清洗.xlsx',sheet_name=2)# 查看Xtest_01中object类型
object_tr =Xtest_01.describe(include='O').columns#检查一下转码的目标是否出现
np.setdiff1d(object_tr,encod_col['变量名'])#0-1 转码
# 获取0-1 转码的变量名
z_0_list = encod_col[encod_col['转']=='0-1'].变量名Xtest_02 = Xtest_01[z_0_list]#sklearn的预处理模块
from sklearn.preprocessing import OrdinalEncoder#fit_transform 直接转
new_arr = OrdinalEncoder().fit_transform(Xtest_02)
# columns 设置表头为原来的 index 索引也是原来
Xtest_02 = pd.DataFrame(data=new_arr,columns=Xtest_02.columns,index=Xtest_02.index)Xtest_01[z_0_list] = Xtest_02Xtest_01.head()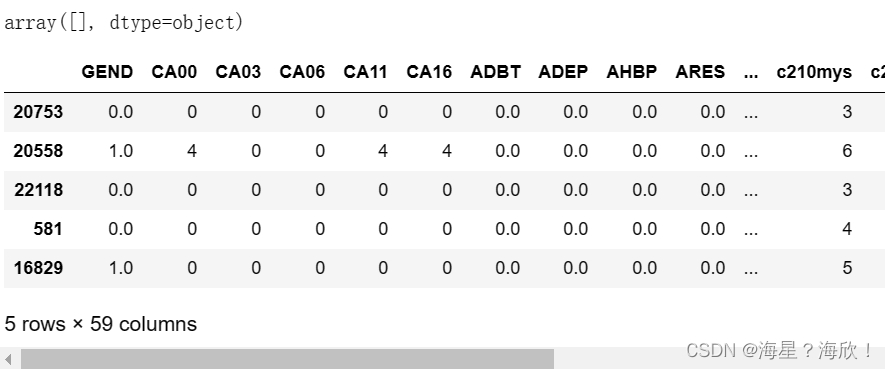
哑变量,总结
#获取哑变量转码的变量
o_h_list = encod_col[encod_col['转']=='哑变量'].变量名o_h_01 = ['c210mys','LIVEWELL'] #非字符型的变量
o_h_02 = [i for i in o_h_list if i not in o_h_01] #字符类型的变量#先转o_h_02 字符类型
Xtest_02 = Xtest_01.copy()
Xtest_02 = pd.get_dummies(chinese(Xtest_02[o_h_02]))#w我们再转 o_h_01 非字符
Xtest_03 = Xtest_01.copy()
#转成字符类型
Xtest_03 = Xtest_03[o_h_01].astype(str)
#转化覆盖
Xtest_03 = pd.get_dummies(chinese(Xtest_03[o_h_01]))# Xtrain_04 删除原转码的字段
Xtest_04 = Xtest_01.copy()
Xtest_04 = chinese(Xtest_04.drop(columns=o_h_01+o_h_02))#将 Xtest_04 Xtest_02 Xtest_03 合并
Xtest_05 = pd.concat([Xtest_04,Xtest_02,Xtest_03],axis=1)
Xtest_05.shape #(13100,96)
Xtest_05.head()
初步建模
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_scoreclf = DecisionTreeClassifier(random_state=420,class_weight='balanced')
cvs = cross_val_score(clf,Xtrain_05,Ytrain)
cvs.mean()
网格搜索找最优参数
from sklearn.model_selection import GridSearchCV#测试参数
param_test = {'splitter':('best','random'),'criterion':('gini','entropy'), #基尼 信息熵'max_depth':range(3,15) #最大深度#,min_samples_leaf:(1,50,5)
}gsearch= GridSearchCV(estimator=clf, #对应模型param_grid=param_test,#要找最优的参数scoring='roc_auc',#准确度评估标准 n_jobs=-1,# 并行数 个数 -1:跟CPU核数一致cv = 5,#交叉验证 5折iid=False,# 默认是True 与各个样本的分布一致 verbose=2#输出训练过程)gsearch.fit(Xtrain_05,Ytrain_01)

#优化期间观察到的最高评分
gsearch.best_score_gsearch.best_params_

模型评估
from sklearn.metrics import accuracy_score #准确率
from sklearn.metrics import precision_score #精准率
from sklearn.metrics import recall_score #召回率
from sklearn.metrics import roc_curve
y_pre = gsearch.predict(Xtest_05)
accuracy_score(y_pre,Ytest) #0.609007633precision_score(y_pre,Ytest) #0.7481523
recall_score(y_pre,Ytest)#0.5100116264048572
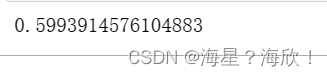
fpr,tpr,thresholds = roc_curve(y_pre,Ytest) #roc参数
import matplotlib.pyplot as pltplt.plot(fpr,tpr,c='b',label='roc曲线')
plt.plot(fpr,fpr,c='r',ls='--')
输出规则
#最优参数
#{'criterion': 'entropy', 'max_depth': 6, 'splitter': 'best'}
from sklearn.tree import DecisionTreeClassifier
from sklearn import treeimport graphviz#将最优参数放到分类器
clf = DecisionTreeClassifier(criterion='entropy',max_depth=6,splitter='best')
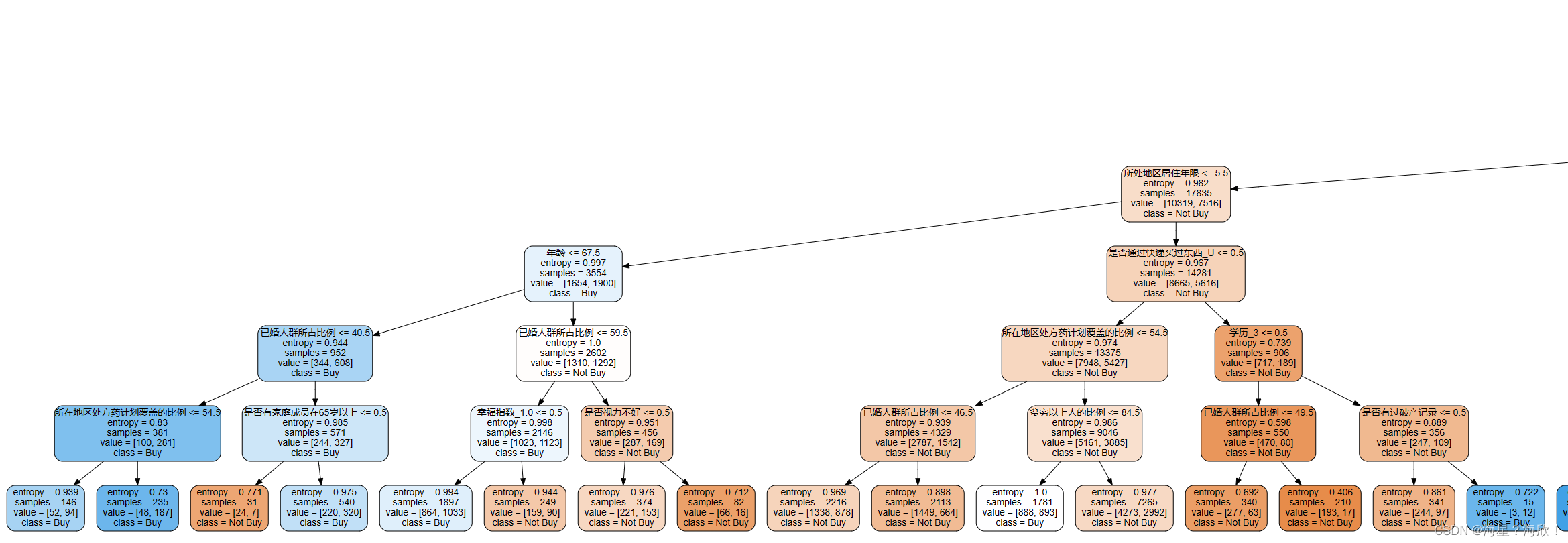
clf = clf.fit(Xtrain_05,Ytrain)features = Xtrain_05.columns
dot_data = tree.export_graphviz(clf,feature_names=features,class_names=['Not Buy','Buy'],filled=True,rounded=True,leaves_parallel=False)graph= graphviz.Source(dot_data)graph
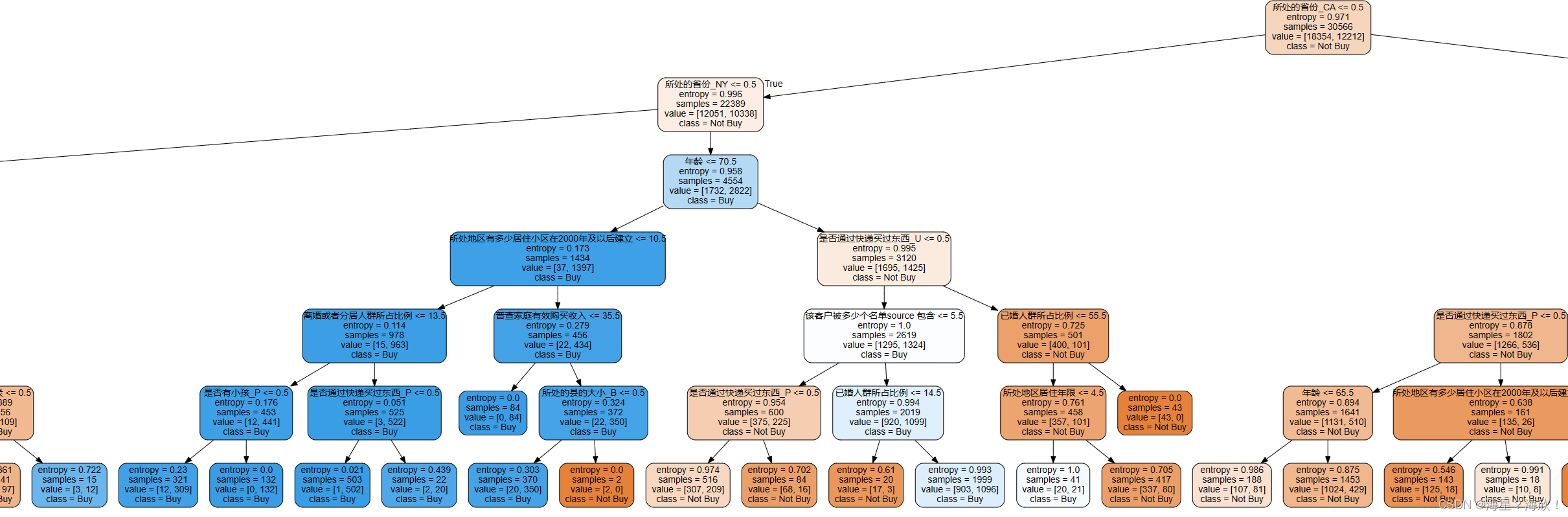
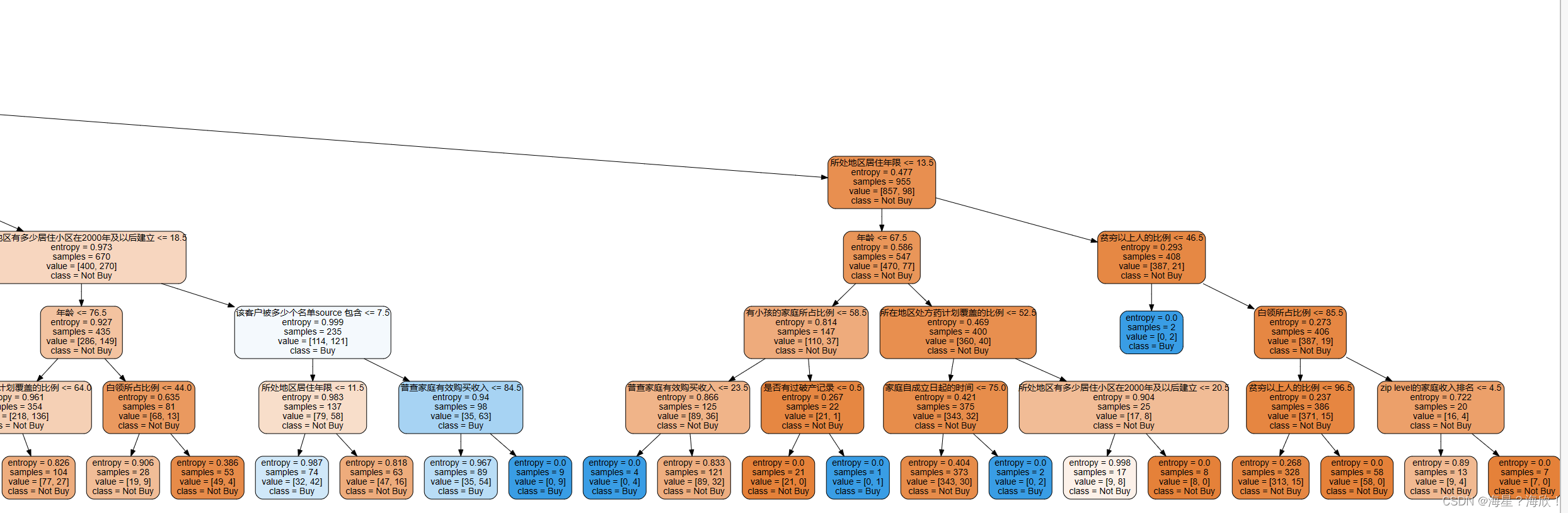
3、输出结果分析
购买比例最高的两类客户的特征是什么?
第一类:
- 处于医疗险覆盖率比例较低区域
- 居住年限小于7年
- 65-72岁群体
那么我们对业务人员进行建议的时候就是,建议他们在医疗险覆盖率比例较低的区域进行宣传推广,然后重点关注那些刚到该区域且年龄65岁以上的老人,向这些人群进行保险营销,成功率应该会更高。
第二类: - 处于医疗险覆盖率比例较低区域
- 居住年限大于7年
- 居住房屋价值较高
这一类人群,是区域内常住的高端小区的用户。这些人群也同样是我们需要重点进行保险营销的对象。
其他建议:
- 了解客户需求
我们需要了解客户的需求,并根据客户的需求举行保险营销。PIOS数据∶向客户推荐产品,并利用个人的数据(个人特征)向客户推荐保险产品。旅行者∶根据他们自己的数据(家庭数据),生活阶段信息推荐的是财务保险、人寿保险、保险、旧保险和用户教育保险。外部数据、资产保险和人寿保险都提供给高层人士,利用外部数据,我们可以改进保险产品的管理,增加投资的收益和收益。 - 开发新的产品
保险公司还应协助外部渠道开发适合不同商业环境的保险产品,例如新的保险类型,如飞行延误保险、旅行时间保险和电话盗窃保险。目的是提供其他保险产品,而不是从这些保险中受益,而是寻找潜在的客户。此外,保险公司将通过数据分析与客户联系,了解客户。外部因素将降低保险的营销成本,并直接提高投资回报率。
相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
A.机器学习入门算法(三):基...
机器学习算法(三):K近邻(k-nearest neigh...
数字温湿度传感器DHT11模块...
模块实例https://blog.csdn.net/qq_38393591/article/deta...
有限元三角形单元的等效节点力
文章目录前言一、重新复习一下有限元三角形单元的理论1、三角形单元的形函数(Nÿ...
Redis 所有支持的数据结构...
Redis 是一种开源的基于键值对存储的 NoSQL 数据库,支持多种数据结构。以下是...
win下pytorch安装—c...
安装目录一、cuda安装1.1、cuda版本选择1.2、下载安装二、cudnn安装三、pytorch...
MySQL基础-多表查询
文章目录MySQL基础-多表查询一、案例及引入1、基础概念2、笛卡尔积的理解二、多表查询的分类1、等...
keil调试专题篇
调试的前提是需要连接调试器比如STLINK。 然后点击菜单或者快捷图标均可进入调试模式。 如果前面...
MATLAB | 全网最详细网...
一篇超超超长,超超超全面网络图绘制教程,本篇基本能讲清楚所有绘制要点&#...
IHome主页 - 让你的浏览...
随着互联网的发展,人们越来越离不开浏览器了。每天上班、学习、娱乐,浏览器...
TCP 协议
一、TCP 协议概念 TCP即传输控制协议(Transmission Control ...
营业执照的经营范围有哪些
营业执照的经营范围有哪些 经营范围是指企业可以从事的生产经营与服务项目,是进行公司注册...
C++ 可变体(variant...
一、可变体(variant) 基础用法 Union的问题: 无法知道当前使用的类型是什...
血压计语音芯片,电子医疗设备声...
语音电子血压计是带有语音提示功能的电子血压计,测量前至测量结果全程语音播报...
MySQL OCP888题解0...
文章目录1、原题1.1、英文原题1.2、答案2、题目解析2.1、题干解析2.2、选项解析3、知识点3...
【2023-Pytorch-检...
(肆十二想说的一些话)Yolo这个系列我们已经更新了大概一年的时间,现在基本的流程也走走通了,包含数...
实战项目:保险行业用户分类
这里写目录标题1、项目介绍1.1 行业背景1.2 数据介绍2、代码实现导入数据探索数据处理列标签名异...
记录--我在前端干工地(thr...
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前段时间接触了Th...
43 openEuler搭建A...
文章目录43 openEuler搭建Apache服务器-配置文件说明和管理模块43.1 配置文件说明...