
Arthas工具、GC日志、常量池
文章目录
- Arthas
- Arthas使用场景
- 使用
- GC日志
- JVM参数汇总
- 常量池
- 常量池
- 字符串常量池
- 字符串常量池案例
- 基本类型和包装类常量池
Arthas
官方文档
Arthas使用场景
- 反编译线上代码,查看最新更新的代码是否成功部署
- 检测JVM运行情况
使用
使用和目标进程一样的用户启动
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
接下来会把当前运行的java进程都打印出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5fXrrRO0-1679204783617)(picture/性能调优/image-20230319112120815.png)]](/uploadfile/202505/744c47590a554bb.png)
直接输入进程号 比如输入3 再回车
输入dashboard然后按回车,就会显示各个线程占用cpu的情况、JVM内存使用情况、jvm参数
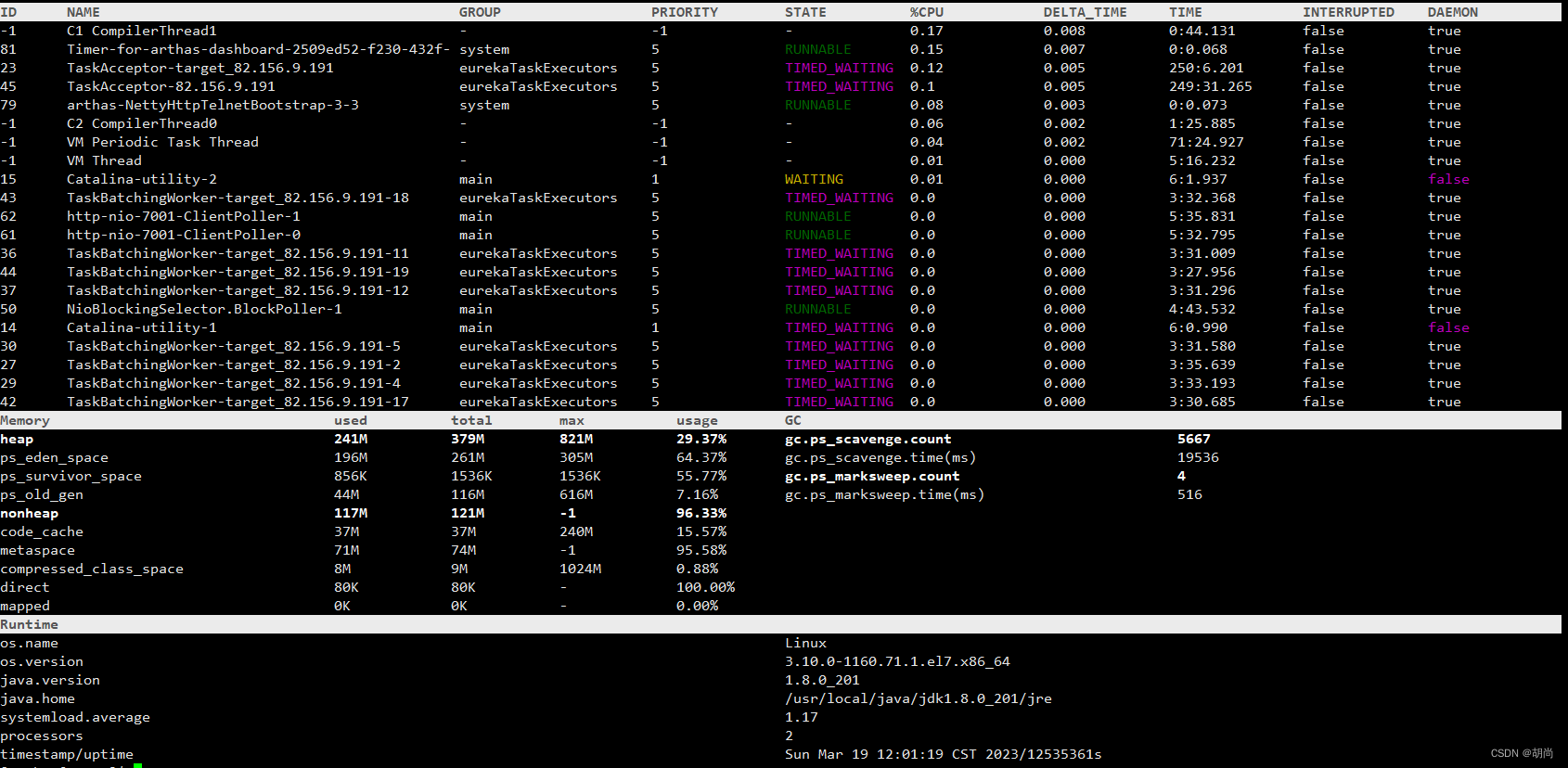
输入thread可以查看线程详细情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wCDUFmhW-1679204783617)(picture/性能调优/image-20230319120503858.png)]](/uploadfile/202505/e7c434a3951d015.png)
输入 thread加上线程ID 可以查看线程堆栈
输入 thread -b 可以查看线程死锁
输入 jad加类的全名 可以反编译,这样可以方便我们查看线上代码是否是正确的版本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KU781gkg-1679204783618)(picture/性能调优/96602)]](/uploadfile/202505/6c9cb4ad6db96ca.png)
GC日志
添加打印gc日志的参数,./gc-%t.log是文件路径 %t是时间,最多保留10个日志文件,每个日志文件达到100M就触发日志轮替
-Xloggc:./gc-%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M
我们实现来分析JDK8默认的Parallel垃圾收集器
java -jar -Xloggc:./gc-%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M microservice-eureka-server.jar
生成的日志文件大概如下图所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mVAjqCix-1679204783618)(picture/性能调优/80226)]](/uploadfile/202505/f65025c7b437633.png)
第一个红框中的内容是一些运行参数,下面几行就是触发MinorGC的日志,第二个红框中的是FullGC的日志。
FullGC打印的日志内容主要是
1、对于2.909: 这是从jvm启动开始计算到这次GC经过的时间,前面还有具体的发生时间日期。
2、Full GC(Metadata GC Threshold)指这是一次full gc,括号里是gc的原因, PSYoungGen是年轻代的GC,ParOldGen是老年代的GC,Metaspace是元空间的GC
3、 6160K->0K(141824K),这三个数字分别对应GC之前占用年轻代的大小,GC之后年轻代占用,以及整个年轻代的大小。
4、112K->6056K(95744K),这三个数字分别对应GC之前占用老年代的大小,GC之后老年代占用,以及整个老年代的大小。
5、6272K->6056K(237568K),这三个数字分别对应GC之前占用堆内存的大小,GC之后堆内存占用,以及整个堆内存的大小。
6、20516K->20516K(1069056K),这三个数字分别对应GC之前占用元空间内存的大小,GC之后元空间内存占用,以及整个元空间内存的大小。
7、0.0209707是该时间点GC总耗费时间。
为了避免元空间不足触发fullgc,然后动态调整元空间容量,我们可以在启动时添加下面参数指定元空间容量
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
CMS垃圾收集器日志
-Xloggc:d:/gc-cms-%t.log -Xms50M -Xmx50M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
大部分还是上面的启动参数,为了更快触发fullGC将堆内存变小 -Xms50M -Xmx50M,并使用parnew和cms垃圾回收器-XX:+UseParNewGC -XX:+UseConcMarkSweepGC ,然后在观察日志文件
G1
-Xloggc:d:/gc-g1-%t.log -Xms50M -Xmx50M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M -XX:+UseG1GC
我们还就可以解决日志分析工具来分析gc日志,比如gceasy
JVM参数汇总
# 表示打印出所有参数选项的默认值
java -XX:+PrintFlagsInitial # 表示打印出所有参数选项在运行程序时生效的值
java -XX:+PrintFlagsFinal
常量池
常量池
java文件编译为class文件后,在class文件中就有一块是常量池,用来存放编译期生成的字面量和符号引用
一个class文件的16进制大体结构如下图:
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-knjhShox-1679204783618)(picture/性能调优/80047)]](/uploadfile/202505/4d2e8457597ced1.png)
对应的含义如下,细节可以查下oracle官方文档
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Oli6o7X4-1679204783618)(picture/性能调优/80124)]](/uploadfile/202505/0085594dde9621f.png)
当然我们一般不会去人工解析这种16进制的字节码文件,我们一般可以通过javap命令生成更可读的JVM字节码指令文件:
javap -v Math.class
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iPvMmdDM-1679204783618)(picture/性能调优/80062)]](/uploadfile/202505/d5fa512e12552a2.png)
红框标出的就是class常量池信息,常量池中主要存放两大类常量:字面量和符号引用。
字面量
就是数值或字符串,出现在等号右边
int a = 1;
int b = 2;
int c = "abcdefg";
int d = "abcdefg";
符号引用
符号一般包括
- 类或接口与全类名
- 字段的名称和描述符
- 方法的方法名与描述符
刚开始这些符号都只是在.class文件中以字节的方式存在,这些常量池加载到内存后就是运行时常量池了,各个常量也就有了具体存放的内存地址,然后就是把符号引用替换为直接引用的过程。
字符串常量池
jdk1.8之前字符串常量池还是方法区中,jdk1.8字符串常量池在堆中。
三种字符串的操作:
-
String s = "abcd";这种字面量,首先会去字符串常量池中使用equals()找,如果找到了就直接返回引用地址,如果没找到则在堆中创建一个字符串对象,字符串常量池中指向堆中对象的内存地址,再把这个地址返回。
字符串常量池我们可以理解为一个hashtable,key-value的格式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b5NBCEqh-1679204783618)(picture/性能调优/image-20230319130629197.png)]](/uploadfile/202505/49eee07db796c86.png)
-
String s1 = new String("hushang");hushang这个字面量 和上面一样肯定还是会在常量池中创建,但同时还会在堆中创建一个字符串对象,真正返回的是第二个创建对象的引用地址
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mstCnWln-1679204783619)(picture/性能调优/image-20230319131049508.png)]](/uploadfile/202505/d74dcf7e1569.png)
-
intern方法
String s1 = new String("hushang"); String s2 = s1.intern();System.out.println(s1 == s2); //false调用intern()方法时,如果这个字符串在字符串常量池中存在则返回常量池中的内存地址
如果这个字符串对象在堆中存在,但常量池中不存在则直接返回堆中的这个对象地址。 jdk1.6版本需要将 s1 复制到字符串常量池里
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p7419kwI-1679204783619)(picture/性能调优/image-20230319131631197.png)]](/uploadfile/202505/d2e5ef7451d0869.png)
字符串常量池案例
-
下面代码创建了几个对象
String s1 = new String("he") + new String("llo"); String s2 = s1.intern();System.out.println(s1 == s2); // 在 JDK 1.6 下输出是 false,创建了 6 个对象 // 在 JDK 1.7 及以上的版本输出是 true,创建了 5 个对象下图是jdk1,6 的情况,两个字面量会在常量池中创建,new对象还会在堆中创建,最后会创建一个hello的字符串返回给s1,但是方法区永久代中不存在当前hello字符串,则会创再创建一个对象返回给s2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-abmGdcnA-1679204783619)(picture/性能调优/96690)]](/uploadfile/202505/ee896082ee527.png)
下图是jdk1.7及之后的情况,去掉了永久代,字符串常量池存在堆内存中。如果某个字符串在堆中存在但是常量池中不存在,其实是将堆中这个对象的地址引用保存在常量池中再返回
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9TXrIuFL-1679204783619)(picture/性能调优/96692)]](/uploadfile/202505/1b7a74d019582bf.png)
-
输出结果
String s0="zhuge"; String s1="zhuge"; String s2="zhu" + "ge"; System.out.println( s0==s1 ); //true System.out.println( s0==s2 ); //true/zhu”和”ge”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量
第三行行代码会在编译时进行优化,变为s2=“zhuge” -
输出结果
String s0="zhuge"; String s1=new String("zhuge"); String s2="zhu" + new String("ge"); System.out.println( s0==s1 ); // false System.out.println( s0==s2 ); // false System.out.println( s1==s2 ); // falses0使用的是常量池中地址引用,s1是堆内存地址引用,s2这种情况是不会再编译时继续优化的 最后是使用的新创建的对象
-
输出结果
String a = "a1";String b = "a" + 1;System.out.println(a == b); // true String a = "atrue";String b = "a" + "true";System.out.println(a == b); // true String a = "a3.4";String b = "a" + 3.4;System.out.println(a == b); // true -
输出结果
String a = "ab"; String bb = "b"; String b = "a" + bb;System.out.println(a == b); // falseString s1 = "abc"; String s2 = "a"; String s3 = s2 + "bc";System.out.println(s1 == s3); // false字符串常量加法中有字符串引用存在,引用的值在编译时是没法确定的,所以
"a" + bb是没办法优化的,只有在程序运行期来动态分配并将连接后的新地址赋给b。 -
输出结果
String a = "ab"; final String bb = "b"; String b = "a" + bb;System.out.println(a == b); // true和上面实例中唯一不同的是bb字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + bb和"a" + "b"效果是一样的。
-
输出结果
String a = "ab"; final String bb = getBB(); String b = "a" + bb;System.out.println(a == b); // falseprivate static String getBB() { return "b"; }JVM对于字符串引用bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b
-
最后一个案例
// 字符串常量池:"计算机"和"技术" 堆内存:str1引用的对象"计算机技术" // StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用 String str2 = new StringBuilder("计算机").append("技术").toString(); //没有出现"计算机技术"字面量,所以不会在常量池里生成"计算机技术"对象 System.out.println(str2 == str2.intern()); //true //"计算机技术" 在池中没有,但是在heap中存在,则intern时,会直接返回该heap中的引用//字符串常量池:"ja"和"va" 堆内存:str1引用的对象"java" // StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用 String str1 = new StringBuilder("ja").append("va").toString(); //没有出现"java"字面量,所以不会在常量池里生成"java"对象 System.out.println(str1 == str1.intern()); //false //java是关键字,在JVM初始化的相关类里肯定早就放进字符串常量池了String s1=new String("test"); System.out.println(s1==s1.intern()); //false //"test"作为字面量,放入了池中,而new时s1指向的是heap中新生成的string对象,s1.intern()指向的是"test"字面量之前在池中生成的字符串对象String s2=new StringBuilder("abc").toString(); System.out.println(s2==s2.intern()); //false //同上
基本类型和包装类常量池
Byte,Short,Integer,Long,Character,Boolean实现了常量池,另外两种浮点数类型的包装类则没有实现常量池。
常量池中在程序刚开始运行时就会创建-128~127之间的值,如果值这个区间的话则会使用常量池中的,如果超过了127则不会使用常量池的
public class Test {public static void main(String[] args) {//5种整形的包装类Byte,Short,Integer,Long,Character的对象, //在值小于127时可以使用对象池 Integer i1 = 127; //这种调用底层实际是执行的Integer.valueOf(127),里面用到了IntegerCache对象池Integer i2 = 127;System.out.println(i1 == i2);//输出true //值大于127时,不会从对象池中取对象 Integer i3 = 128;Integer i4 = 128;System.out.println(i3 == i4);//输出false //用new关键词新生成对象不会使用对象池Integer i5 = new Integer(127); Integer i6 = new Integer(127);System.out.println(i5 == i6);//输出false //Boolean类也实现了对象池技术 Boolean bool1 = true;Boolean bool2 = true;System.out.println(bool1 == bool2);//输出true //浮点类型的包装类没有实现对象池技术 Double d1 = 1.0;Double d2 = 1.0;System.out.println(d1 == d2);//输出false }
}