
到底要怎么保证Kafka的消息幂等性?
文章目录
- 一、面试流经典答法
- 二、Kafka是如何考虑幂等问题的
- 三、项目中常见的Kafka消息幂等问题处理思路是怎样的?
- 总结
如何保证Kafka的消息幂等性? 这同样是一个不应该被当做八股文的面试题。之前在介绍Kafka消息安全的时候,提到过。在Kafka的消费者端,由于Kafka有消息重试机制,所以通常是不会造成消息丢失的。唯一需要注意的是消费者端尽量不要使用异步方式来处理消息。但是,其实这也带来了另一个问题。Kafka的消费重试机制有可能造成同一个消息多次投递给消费者,所以有可能一个消息被多次推送到消费者端进行处理。这就需要消费者防止消息被重复处理。这就是消息的幂等性问题。
那么要如何处理这样的消息幂等性问题呢?这次同样先从面试流经典答法入手。然后再来梳理下Kafka是如何考虑消息幂等性问题的,以及真正在项目中是如何处理这个问题的。
一、面试流经典答法
面试流的经典答法通常是哪儿疼医哪。既然消息重复问题最终会在消费者端体现,那么处理消息重复问题,自然也由消费者处理。
1、消费者进行幂等性控制
简单点的面试答案就是在消费者进行消息处理之前,增加一个过程,对消息进行检验。比如在电商下单的场景,如果上游传递过来一个订单的消息,需要消费者完成订单的相关下单操作。这时,最简单的幂等性处理方法就是在进行下单处理之前,去数据库中查询一下订单状态,看下这个订单是否已经完成了下单。伪代码如下:
Order oldOrder = OrderMapper.queryOrder(orderId);
//创建订单之前,去数据库中判断一下订单是否已经下过了。
if(null != oldOrder){//订单下单createOrder(order);
}else{return;
}
2、使用布隆过滤器辅助进行重复判断
有经验一点的程序员会发现,上面的这个处理方式会有一点效率的问题。查询数据库的性能本来就是比较低的,当消息量比较大时,每个消息都去数据库里转一圈,性能消耗是非常巨大的。尤其对于那些真正重复的消息,什么逻辑都不做,就去数据库查一下,这有点得不偿失。
所以有一种优化方式是使用布隆过滤器BloomFIlter来优化去数据库里查询的步骤。网上以及很多中间件中都有很多BloomFilter的实现类。在使用时也很简单。通常都是构建一个BloomFilter,然后将数据库里的Order全部一股脑的添加到这个Bloomfilter中。在消费者进行消费时,就用这个BloomFilter去判断是否包含待处理的orderID。如果不包含,就进行下单业务。伪代码如下:
//构建布隆过滤器。将已有订单ID全部添加进去。
BloomFilter filter= new BloomFilter();
filter.add("order1");
filter.add("order2");
.....
//消费消息时,使用布隆过滤器判断订单是否重复。
if(!filter.contains(orderId)){createOrder(order);filter.add(orderId);
}else{return;
}
这样检查订单是否重复的逻辑就不用再经过数据库了。布隆过滤器的过滤性能非常高,查询元素的时间复杂度只有O(1), 并且布隆过滤器的实现也不复杂,本质上就是一个0和1组成的很长的二进制数组,这样的数据结构使得布隆过滤器对具体存储的介质并不挑剔。本地缓存或者Redis都可以很方便高效的实现布隆过滤器。甚至在很多中间件中都已经包含了布隆过滤器的具体实现。
通常对于幂等性问题,面试聊到这也就差不多了。再深入一点就是解释一下布隆过滤器的实现原理。
其实布隆过滤器的实现原理也不复杂,按照下面一个图解释就可以了。
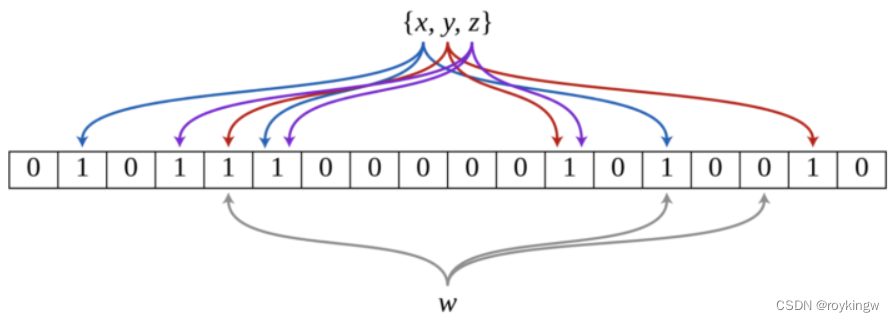
1、布隆过滤器的本质就是中间那一个位数组。初识全都是0。
2、上面的x,y,z是待添加的已有元素。添加时通过一系列的Hash函数,将已有元素x散列成一个位数组。将这个位数组对应位置的1记录到布隆过滤器的原始位数组中,这样就完成了记录的添加。
3、当布隆过滤器要去判断是否包含元素w时,也是同样将元素w散列成一个位数组,然后拿那些1的位置与原始位数组进行比较。如果w的位数组中每个1的位置都和原始数组匹配,那就就判断w包含在布隆过滤器中。而如果有一个记录为1的位置与原始位数组不匹配,那么就判断元素w没有包含在布隆过滤器中。
布隆过滤器有一个误判的问题。就是如果布隆过滤器判断不包含一个元素,那么这个元素就肯定没有包含在布隆过滤器中。但是如果布隆过滤器判断包含一个元素,那么这个元素有可能没有包含在布隆过滤器中。
从上图就可以判断,假如w元素散列后的结果是第2,4,5三个位置为1,也就是 01011000000这样的结果。 那么布隆过滤器会认为w一定是包含在原始数据中的。因为每个对应位置的值都是1。但是实际上,这几个为1的位置,并不是一个完整元素映射出来的,而是x,y,z三个元素共同映射出来的。这样就出现了误判。
但是回到判断订单是否重复的问题,我们需要的是布隆过滤器判断订单ID不存在,这时布隆过滤器是不会误判的。也就是说布隆过滤器的误判问题对于我们这个判断订单是否重复的场景,是没有影响的。
二、Kafka是如何考虑幂等问题的
对于Kafka消息幂等的问题,绝大部分的面试八股文也就分析到这了。就算再有些花里胡哨的指导,其实也都是围绕这个订单ID,做一些其他的判重手段。比如如果业务上没有orderId这样的唯一区分的参数,那么就用分布式ID生成服务,主动生成一个唯一标识,然后可以加锁,用分布式锁、乐观锁等等其他手段来替代布隆过滤器进行判重。总而言之,都是一个思路:消息重复判断都是消费者端自己控制的。但是事实真的是这样吗?
其实我们不妨深究一下为什么会产生重复的消息。如果Kafka所有相关组件都工作正常,是不会有重复消息问题的。业务上不会傻到让消息生产者重复多次推送同一条订单消息。消费者如果能够控制处理时间,让每一批消息处理都不超时,那么Kafka也不会闲着没事向消费者多次推送同一批消息。那为什么又还是需要考虑消费者的幂等问题呢?这其中就又提到了分布式系统的一个重要的元凶:网络。 因为网络是非常不靠谱的,所以跨网络的RPC请求通常都需要考虑失败重试。而正是这个重试机制,才产生了我们这里讨论的幂等性问题。那既然提到了网络,那就不止Kafka与消费者之间跨网络了。上游的生产者与Kafka之间也跨了网络。那为什么我们没有去考虑过生产者与Kafka之间的重试问题呢?这就是因为Kafka已经帮我们做了设计。但是注意,Kafka帮我们做了设计不代表我们就不需要考虑幂等性问题了。
1、先来细看一下消息生产者与Kafka之间如何发送消息的。
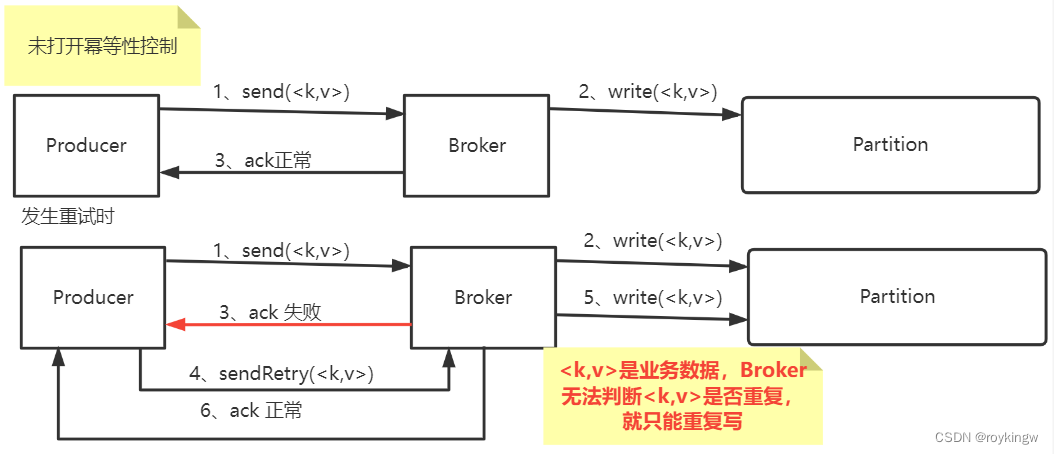
我们使用Kafka的生产者往kafka发消息时,都只是指定消息的key和value。其中key主要用来找到对应的Partition。而value是消息的主体,这两个元素都不足以区分不同的消息。如果一切工作正常,生产者发一次消息,Broker保存一次消息到Partition,发消息这事就很圆满了。 但是,如果Broker往Producer的ack回应出现了异常,生产者就会认为消息发送失败了,就会发起重试。这时Broker接收到两条key和value都相同的消息,他是无法判断这一条消息是否重复的。也就是说Broker无法判断是同一条消息发送了两次还是生产者就是要发送两条key和value相同的消息。此时Broker就只能将两条消息都保存下来,这样就造成了生产者端的消息重复。
但是,在Kakfa的生产者KafkaProducer中,Kafka提供了一系列的参数可以设置。其中就有一个参数 ENABLE_IDEMPOTENCE_CONFIG来进行幂等性判断。一下是Kafka源码当中对这个参数的描述。
public static final String ENABLE_IDEMPOTENCE_CONFIG = "enable.idempotence";public static final String ENABLE_IDEMPOTENCE_DOC = "When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer " + "retries due to broker failures, etc., may write duplicates of the retried message in the stream. "+ "Note that enabling idempotence requires " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + " to be less than or equal to " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE+ " (with message ordering preserved for any allowable value), " + RETRIES_CONFIG + " to be greater than 0, and "+ ACKS_CONFIG + " must be 'all'. "+ ""+ "Idempotence is enabled by default if no conflicting configurations are set. "+ "If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled. "+ "If idempotence is explicitly enabled and conflicting configurations are set, a ConfigException is thrown.";
从这段注释中能简单看到,幂等性问题不是一个简答参数就设置完事了的,需要多个参数配合。
这个参数的值默认设置为true,表示打开幂等性判断。这时,Kafka在发送消息时,会增加两个数据。
- PID: 每个新的Producer在初始化的过程中都会被分配一个唯一的PID。这个PID对用户是不可见的。
- Sequence Number:对于每个PID,这个Producer发送的数据的每个
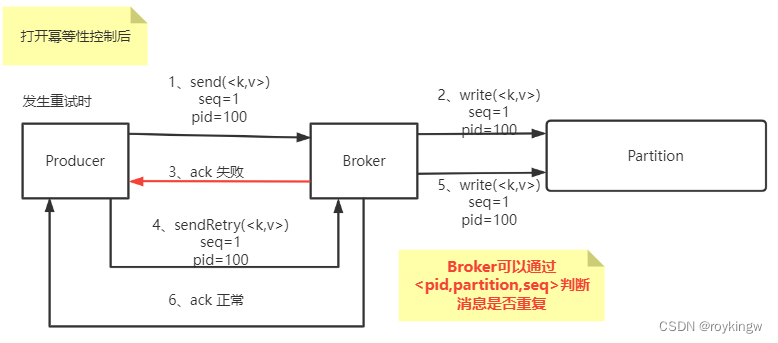
这样,Kafka在打开idempotence幂等性控制后,在Broker端就会保证每个具有相同的
实际上,这就保证了生产消息的at-most-once语义。再加上大家耳熟能详的生产者端的重试机制保证at-least-once语义,这样整体上就保证了消息生产的Exactaly-once语义。
2、再来看Kafka与消费者之间的幂等性问题:
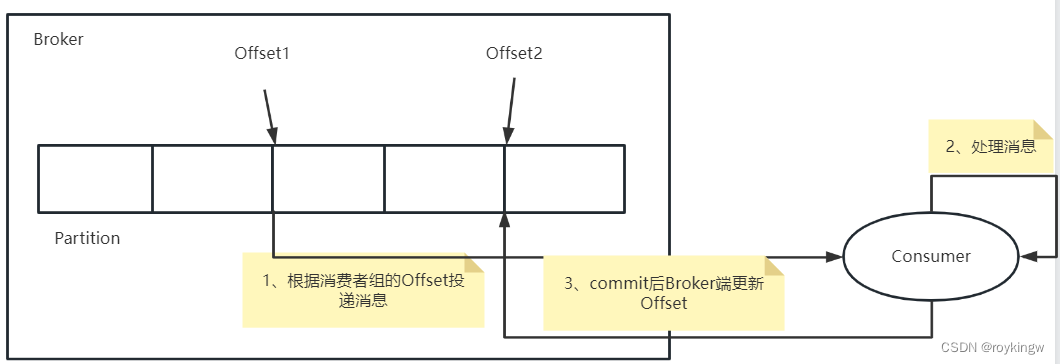
我们都知道Kafka是通过Partition上记录的Offset来控制每一个消费者组的消费进度。每次拉取一批消息后,kafka就会等待消费者向Broker进行提交。提交后Broker端就会更新Offset,这一批消息也就不会重复投递了。但是Broker端并无法预测消费者要处理多长时间。所有Broker端能做的也只有尽力等待。但是如果等待超过了消费者端的max.poll.interval.ms参数设置的时长,那么Broker就只能认为消费者处理失败。这样同一个组的消费者再来拉取消息时,Broker就向其他消费者实例重复投递消息,这样就产生了消费者幂等问题。这个参数默认设置是300秒。
public static final String MAX_POLL_INTERVAL_MS_CONFIG = "max.poll.interval.ms";public static final String MAX_POLL_INTERVAL_MS_DOC = "The maximum delay between invocations of poll() when using "+ "consumer group management. This places an upper bound on the amount of time that the consumer can be idle "+ "before fetching more records. If poll() is not called before expiration of this timeout, then the consumer "+ "is considered failed and the group will rebalance in order to reassign the partitions to another member. "+ "For consumers using a non-null group.instance.id which reach this timeout, partitions will not be immediately reassigned. "+ "Instead, the consumer will stop sending heartbeats and partitions will be reassigned "+ "after expiration of session.timeout.ms. This mirrors the behavior of a static consumer which has shutdown.";
其实这个过程中,Broker端要做的就是准确判断Consumer端的消息投递是否正常。但是,作为一个通用服务,Kafka并没有办法精确预估生产者的处理时长。甚至由于网络的不稳定性,消息到底到没到Consumer都无法主动判断。所以Broker端能做的最好的方式就是精确预估好消费者的业务处理时长,通过处理时长来判断消费者是正常处理还是消息投递失败。比如确认消费者正常处理到Commit需要1000毫秒,那么Broker端只要等待1000毫秒就可以了。但是问题就在于,由于消费者的业务处理速度以及commit提交的速度都是不确定的,所以等待时长不管设置多长,理论上,只要有一次消费者处理慢了,就会造成不必要的消息重复投递。更何况,Kafka为了支持高吞吐,也不可能将等待时间设置成太长。
三、项目中常见的Kafka消息幂等问题处理思路是怎样的?
从上面的分析可以看到,这个超时时间不管怎么设置,其实都无法达到最理想的效果。 最终还是需要消费者端做幂等控制。但是在很多大型项目中,消费者端的业务逻辑可能本身就很耗时也很复杂。要再加上一个幂等性的判断是非常困难的。例如很多大型项目,可能订单信息需要落地的地方不只是数据库,可能还有MongoDB,ES等其他存储,或者还要更新Redis。要判断一个订单之前是否完整处理了,就会比较麻烦。那么大型项目通常是怎么考虑这类问题的呢?
其实就可以从offset入手来考虑这个问题。
Kafka中的Offset反映的是消息的处理进度。但是,在业务层面,其实最关心的并不是消息的处理进度,而是订单的处理进度。这两者虽然有关联,但是因为需要进行跨网络提交、确认,所以实际上是有区别的。 那么能不能将Offset从Broker端抽出来,自行进行管理呢。这样让新抽出来的Offset直接反映业务上订单的处理进度,这样不就可以通过订单的处理进度直接判断业务处理到哪个程度了吗?
比如说,我们可以自行在Redis里记录当前队列里订单的处理进度。当前处理到了第10条订单。 那么即便前面第8条,第9条订单的消息重复发生了投递,我们通过这个订单进度也就可以快速判断出订单8和订单9已经处理过了,就不用在处理逻辑上单独去判断第8条和第9条订单有没有记录了。
这种思路的伪代码如下:
while(true){//拉取消息ConsumerRecords records = consumer.poll(Duration.ofSeconds(1));records.partitions().forEach(partition ->{//从redis获取partition的偏移量String redisKafkaOffset = redisTemplate.opsForHash().get(partition.topic(), "" + partition.partition()).toString();long redisOffset = StringUtils.isEmpty(redisKafkaOffset)?-1:Long.valueOf(redisKafkaOffset);List> partitionRecords = records.records(partition);partitionRecords.forEach(record ->{//redis记录的偏移量>=kafka实际的偏移量,表示已经消费过了,则丢弃。if(redisOffset >= record.offset()){return;}//业务端只需要实现这个处理业务的方法就可以了,不用再处理幂等性问题doMessage(record.topic(),record.value());});});//处理完成后立即保存Redis偏移量long saveRedisOffset = partitionRecords.get(partitionRecords.size() - 1).offset();redisTemplate.opsForHash().put(partition.topic(),"" + partition.partition(),saveRedisOffset);//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。。consumer.commitAsync();
}
通过处理进度来统一管理处理进度,防止重复消费。而具体的业务逻辑就不用再过多关心幂等性问题了,可以更专注处理自己的业务逻辑,实现其中的doMessage方法就可以为了。
示例考虑到Redis的性能,所以是每处理一批消息,更新一次Redis中的Offset。其实如果Redis性能足够的话,完全可以处理一条消息就更新一次Redis中的Offset。这样进度管理更精确。但是通常Kafka所面临的都是高并发场景,这样对Redis的压力也是非常大的。需要进行合理的估算。
总结
实际上,将Offset从kafka的Broker端抽出来自行进行管理后,可以给使用Kafka带来非常大的灵活性,远不止减少幂等判断这样一个用处。你还能想到哪些用处呢?不妨自己思考思考,或者评论出来,大家一起讨论讨论。