
ETL工具—AWS Glue
一、什么是AWS Glue
AWS Glue 是一项无服务器数据集成服务,可让使用分析功能的用户轻松发现、准备、移动和集成来自多个来源的数据。您可以将其用于分析、机器学习和应用程序开发。它还包括用于编写、运行任务和实施业务工作流程的额外生产力和数据操作工具。
AWS Glue 将主要数据集成功能整合到一项服务中。其中包括数据发现、现代 ETL、清理、转换和集中式编目。这也是一项无服务器服务,即无需管理基础设施。通过在一项服务中灵活支持 ETL、ELT 和流式传输之类的所有工作负载,AWS Glue 可为不同工作负载和类型的用户提供支持。
二、 AWS Glue 环境的架构
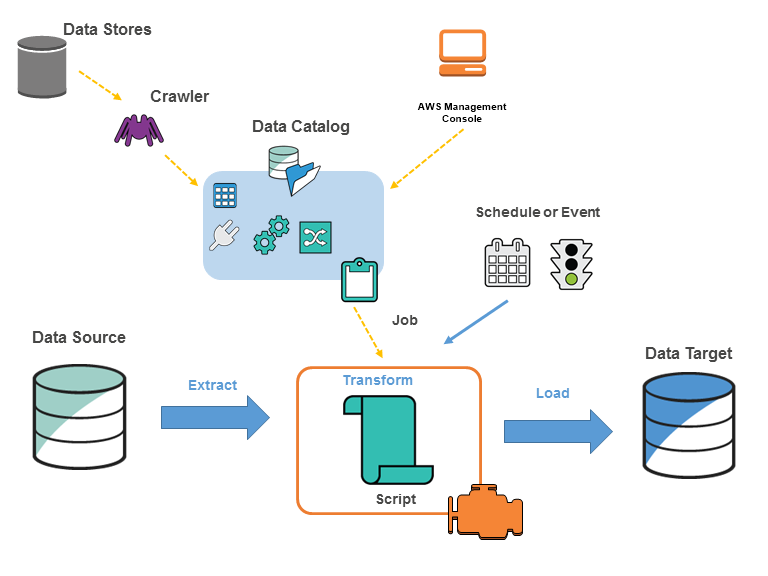
可以在 AWS Glue 中定义作业以完成所需的工作从数据源提取、转换和加载 (ETL) 数据到数据目标。通常 执行以下操作:
对于数据存储源,可以定义一个爬网程序来填充 包含元数据表定义的 AWS Glue 数据目录。将爬网程序指向数据存储, 爬网程序在数据目录中创建表定义。对于流式传输源,手动定义数据目录表并指定数据流属性。
除了表定义之外,AWS Glue 数据目录还包含其他元数据,这些元数据是需要定义 ETL 作业。在将作业定义为 转换数据。
AWS Glue 可以生成脚本来转换您的数据。或者,可以提供 AWS Glue 控制台或 API 中的脚本。
可以按需运行作业,也可以将其设置为在发生指定触发器时启动。触发器可以是基于时间的计划,也可以是 一个事件。
作业运行时,脚本会从数据源中提取数据,转换数据,并将其加载到数据目标。该脚本在Apache Spark中运行 AWS Glue 中的环境。
三、AWS Glue 功能
发现和整理数据
转换、准备和清理数据以进行分析
构建和监控数据管道
发现和整理数据
跨多个数据存储的统一和搜索 – 通过对 AWS 中的所有数据进行编目,跨多个数据来源和接收器进行存储、索引和搜索。
自动发现数据 – 使用 AWS Glue 爬网程序自动推断架构信息并将其集成到 AWS Glue Data Catalog。
管理架构和权限 – 验证和控制对数据库和表的访问。
连接到各种数据来源 – 利用本地和 AWS 的多个数据来源,使用 AWS Glue 连接构建您的数据湖,从而了解多个数据源。
转换、准备和清理数据以进行分析
使用拖放界面直观地转换数据 – 在拖放式任务编辑器中定义 ETL 流程,并自动生成用于提取、转换和加载数据的代码。
通过简单的任务计划构建复杂的 ETL 管道 – 按计划、按需或按事件调用 AWS Glue 任务。
清理和转换传输中流数据 – 支持持续性的数据使用,并在传输过程中对其进行清理和转换。这样便可在数秒内在目标数据存储中完成分析。
通过内置的机器学习去除重复数据和清理数据 – 使用 FindMatches 功能,您无需成为机器学习专家也能轻松清理和准备数据以进行分析。此功能可去除重复项并查找彼此不完全匹配的记录。
内置任务笔记本 – 仅需在 AWS Glue Studio 中进行最少设置,AWS Glue Studio 任务笔记本即可提供无服务器笔记本,以便于您快速开始使用。
编辑、调试和测试 ETL 代码 – 通过 AWS Glue 交互式会话,您能够以交互方式探索和准备数据。您可以使用 IDE 或自己选择的笔记本以交互方式探索数据、对数据进行试验以及处理数据。
定义、检测和修复敏感数据 – AWS Glue 的敏感数据检测功能可让您定义、识别和处理数据管道和数据湖中的敏感数据。
构建和监控数据管道
根据工作负载自动扩展 – 根据工作负载动态扩展和缩减资源。仅在需要时才为工作人员分配任务。
使用基于事件的触发器自动处理任务 – 使用基于事件的触发器启动爬网程序或 AWS Glue 任务,并设计相互依赖的任务与爬网程序链。
运行和监控任务 – 运行 AWS Glue 任务,然后使用自动监控工具 Apache Spark UI、AWS Glue 任务运行洞察和 AWS CloudTrail 来监控任务。
定义 ETL 和集成活动的工作流程 – 为多个爬网程序、任务和触发器定义 ETL 和集成活动的工作流程。
四、使用AWS Glue进行ETL工作
数据湖
数据湖的产生是为了存储各种各样原始数据的大型仓库。这些数据根据需求,进行存取、处理、分析等。对于存储部分来说,开源版本常见的就是 hdfs。而各大云厂商也提供了各自的存储服务,如 Amazon S3,Azure Blob 等。
而由于数据湖中存储的数据全部为原始数据,一般需要对数据做ETL(Extract-Transform-Load)。对于大型数据集,常用的框架是 Spark、pyspark。在数据做完 ETL 后,再次将清洗后的数据存储到存储系统中(如hdfs、s3)。基于这部分清洗后的数据,数据分析师或是机器学习工程师等,可可以基于这些数据进行数据分析或是训练模型。在这些过程中,还有非常重要的一点是:如何对数据进行元数据管理?
在 AWS 中,Glue 服务不仅提供了 ETL 服务,还提供的元数据的管理。下面我们会使用 S3+Glue +EMR 来展示一个数据湖+ETL+数据分析的一个简单过程。
准备数据
此次使用的是GDELT数据,地址为:
https://registry.opendata.aws/gdelt/
此数据集中,每个文件名均显示了此文件的日期。作为原始数据,我们首先将2015年的数据放在一个year=2015 的s3目录下:
aws s3 cp s3://xxx/data/20151231.export.csv s3://xxxx/gdelt/year=2015/20151231.export.csv
使用Glue爬取数据定义
通过glue 创建一个爬网程序,爬取此文件中的数据格式,指定的数据源路径为s3://xxxx/gdelt/ 。
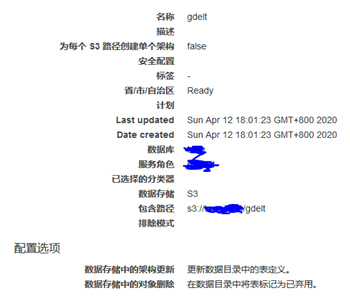
爬网程序结束后,在Glue 的数据目录中,即可看到新创建的 gdelt 表:
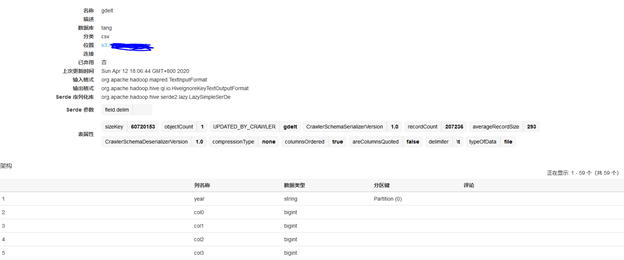
原数据为csv格式,由于没有header,所以列名分别为col0、col1…、col57。其中由于s3下的目录结构为year=2015,所以爬网程序自动将year 识别为分区列。
至此,这部分原数据的元数据即保存在了Glue。在做ETL 之前,我们可以使用AWS EMR 先验证一下它对元数据的管理。
AWS EMR
AWS EMR 是 AWS 提供的大数据集群,可以一键启动带Hive、HBase、Presto、Spark 等常用框架的集群。启动AWS EMR,勾选 Hive、Spark,并使用Glue作为它们表的元数据。EMR 启动后,登录到主节点可以看到在 hive 中已经可以看到此表,执行查询:
> select * from gdelt where year=2015 limit 3;OK498318487 20060102 200601 2006 2006.0055 CVL COMMUNITY CVL 1 53 53 5 1 3.8 3 1 3 -2.42718446601942 1 United States US US 38.0 -97.0 US 0 NULL NULL 1 United States US US 38.0 -97.0 US 20151231 http://www.inlander.com/spokane/after-dolezal/Content?oid=2646896 2015498318488 20060102 200601 2006 2006.0055 CVL COMMUNITY CVL USA UNITED STATES USA 1 51 51 5 1 3.4 3 1 3 -2.42718446601942 1 United States US US 38.0 -97.0 US 1 United States US US 38.0 -97.0 US 1 United States US US 38.0 -97.0 US 20151231 http://www.inlander.com/spokane/after-dolezal/Content?oid=2646896 2015498318489 20060102 200601 2006 2006.0055 CVL COMMUNITY 可以看到原始数据的列非常多,假设我们所需要的仅有4列:事件ID、国家代码、日期、以及网址,并基于这些数据做分析。那我们下一步就是做ETL。
GLUE ETL
Glue 服务也提供了 ETL 的工具,可以编写基于spark 或是 python 的脚本,提交给 glue etl 执行。在这个例子中,我们会抽取col0、col52、col56、col57、以及year这些列,并给它们重命名。然后从中抽取仅包含“UK”的记录,最终以date=current_day 的格式写入到最终s3 目录,存储格式为parquet。可以通过 python 或是 scala 语言调用 GLUE 编程接口,在本文中使用的是 scala:
import com.amazonaws.services.glue.ChoiceOption
import com.amazonaws.services.glue.GlueContext
import com.amazonaws.services.glue.DynamicFrame
import com.amazonaws.services.glue.MappingSpec
import com.amazonaws.services.glue.ResolveSpec
import com.amazonaws.services.glue.errors.CallSite
import com.amazonaws.services.glue.util.GlueArgParser
import com.amazonaws.services.glue.util.Job
import com.amazonaws.services.glue.util.JsonOptions
import org.apache.spark.SparkContext
import scala.collection.JavaConverters._
import java.text.SimpleDateFormat
import java.util.Dateobject Gdelt_etl {def main(sysArgs: Array[String]) {val sc: SparkContext = new SparkContext()val glueContext: GlueContext = new GlueContext(sc)val spark = glueContext.getSparkSession// @params: [JOB_NAME]val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray)Job.init(args("JOB_NAME"), glueContext, args.asJava)// db and tableval dbName = "default"val tblName = "gdelt"// s3 location for outputval format = new SimpleDateFormat("yyyy-MM-dd")val curdate = format.format(new Date())val outputDir = "s3://xxx-xxx-xxx/cleaned-gdelt/cur_date=" + curdate + "/"// Read data into DynamicFrameval raw_data = glueContext.getCatalogSource(database=dbName, tableName=tblName).getDynamicFrame()// Re-Mapping Dataval cleanedDyF = raw_data.applyMapping(Seq(("col0", "long", "EventID", "string"), ("col52", "string", "CountryCode", "string"), ("col56", "long", "Date", "String"), ("col57", "string", "url", "string"), ("year", "string", "year", "string")))// Spark SQL on a Spark DataFrameval cleanedDF = cleanedDyF.toDF()cleanedDF.createOrReplaceTempView("gdlttable")// Get Only UK dataval only_uk_sqlDF = spark.sql("select * from gdlttable where CountryCode = 'UK'")val cleanedSQLDyF = DynamicFrame(only_uk_sqlDF, glueContext).withName("only_uk_sqlDF") // Write it out in ParquetglueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions(Map("path" -> outputDir)), format = "parquet").writeDynamicFrame(cleanedSQLDyF) Job.commit()}
}将此脚本保存为gdelt.scala 文件,并提交给 GLUE ETL作业执行。等待执行完毕后,我们可以在s3看到生成了输出文件:
> aws s3 ls s3://xxxx-xxx-xxx/cleaned-gdelt/ date=2020-04-12/
part-00000-d25201b8-2d9c-49a0-95c8-f5e8cbb52b5b-c000.snappy.parquet
然后我们再对此/cleaned-gdelt/目录执行一个新的 GLUE 网爬程序:
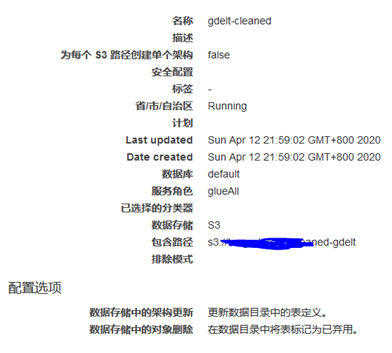
执行完成后,可以在GLUE 看到生成了新表,此表结构为:
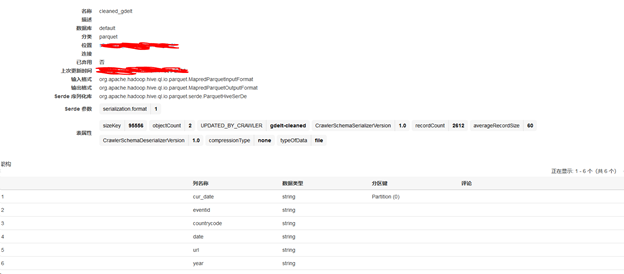
可以看到输入输出格式均为parquet,分区键为cur_date,且仅包含了我们所需的列。
再次进入到 EMR Hive 中,可以看到新表已出现:
hive> describe cleaned_gdelt;
OK
eventid string
countrycode string
date string
url string
year string
date string# Partition Information
# col_name data_type comment
cur_date string查询此表
hive> select * from cleaned_gdelt limit 10;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
498318821 UK 20151231 http://wmpoweruser.com/microsoft-denies-lumia-950-xl-withdrawn-due-issues-says-stock-due-strong-demand/ 2015
498319466 UK 20151231 http://www.princegeorgecitizen.com/news/police-say-woman-man-mauled-by-2-dogs-in-home-in-british-columbia-1.2142296 2015
498319777 UK 20151231 http://www.catchnews.com/life-society-news/happy-women-do-not-live-any-longer-than-sad-women-1451420391.html 2015
498319915 UK 20151231 http://www.nationalinterest.org/feature/the-perils-eu-army-14770 2015
…
Time taken: 0.394 seconds, Fetched: 10 row(s)达到我们的目标。
自动化
下面是将 GLUE 网爬 + ETL 进行自动化。在GLUE ETL 的工作流程中,创建一个工作流,创建完后如下所示:

如图所示,此工作流的过程为:
每晚11点40开始触发工作流
触发 gdelt 的网爬作业,爬取原始数据的元数据
触发gdelt的ETL作业
触发gdelt-cleaned 网爬程序,爬取清洗后的数据的元数据
五、排除 AWS Glue 的故障
如果在 AWS Glue 中遇到错误或意外行为,并且需要与 AWS Support 联系,则应首先收集与失败操作关联的名称、ID 和日志的信息。有了这些信息,AWS Support 可以帮助您解决您遇到的问题。
除了您的 account ID,还收集以下每种故障类型的信息:
当爬网程序失败时,请收集以下信息:
爬网程序名称
爬网程序运行的日志位于 CloudWatch Logs 中的 /aws-glue/crawlers 下面。
当测试连接失败时,请收集以下信息:
连接名称
连接 ID
采用 jdbc:protocol://host:port/database-name 形式的 JDBC 连接字符串。
测试连接的日志位于 CloudWatch Logs 中的 /aws-glue/testconnection 下面。
当作业失败时,请收集以下信息:
任务名称
采用 jr_xxxxx 形式的作业运行 ID。
任务运行的日志位于 CloudWatch Logs 中的 /aws-glue/jobs 下面。
六、AWS Glue 中的日志记录和监控
可以自动运行ETL(提取、转换和加载)作业。AWS Glue 提供了有关爬网程序和作业的指标,可以监控这些指标。使用所需元数据设置 AWS Glue Data Catalog后,AWS Glue 会提供有关环境运行状况的统计数据。可以基于 cron 使用基于时间的计划自动调用爬网程序和作业。您也可以在基于事件的触发器触发时触发作业。
AWS Glue 与 AWS CloudTrail 集成,后者是在 AWS Glue 中记录用户、角色或 AWS 服务所执行操作的服务。如果创建跟踪,则可以使 CloudTrail 事件持续传送到 Amazon Simple Storage Service(Amazon S3)存储桶、Amazon CloudWatch Logs 和 Amazon CloudWatch Events。每个事件或日志条目都包含有关生成请求的人员信息。
使用 Amazon CloudWatch Events 自动化的 AWS 服务,以自动响应系统事件,例如应用程序可用性问题或资源更改。AWS 服务中的事件近乎实时地传输到 CloudWatch Events 。可以编写简单规则来指示所关注的事件,并指示要在事件匹配规则时执行的自动化操作。