Transformer代码分析
目录
- 0 词向量
- 1 模型的思想
- 2 模型的架构
- Encoder部分
- 1、输入
- 2、注意力机制:关注该关注的
- 3、Add&Norm
- 4、feed forward:全连接
- 5、d_model
- max_len
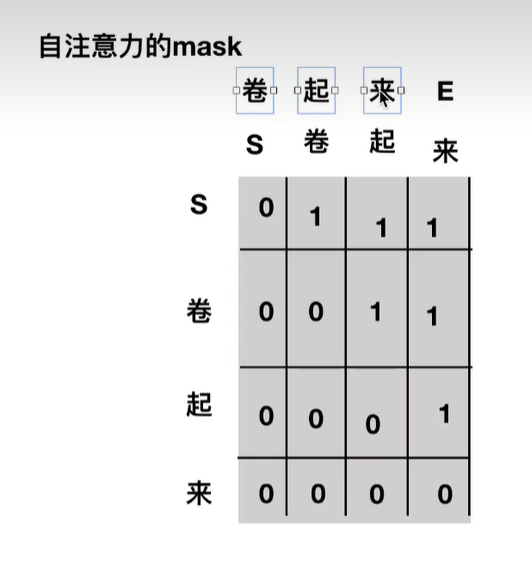
- 自注意力机制层的mask
初学者出没,请大家不吝赐教,不胜感激!
https://cloud.tencent.com/developer/article/1526327
0 词向量
1、[https://zhuanlan.zhihu.com/p/47787947] (参考)
2、 帮助理解词向量如果实现
3、https://zhuanlan.zhihu.com/p/89637281
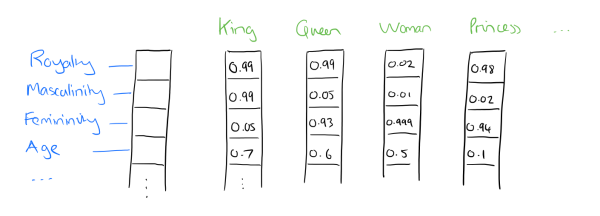
词如何编码? 使用的是霍夫曼树。
这样就可以将词语进行编码表示,放到向量里面
向量的维数是什么?
用词向量来表示词并不是word2vec的首创,在很久之前就出现了。最早的词向量是很冗长的,它使用是词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0)。这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation.
那么one-hot编码有什么缺点呢?
维度灾难
一般情况下,常用英语单词约8000个,如果使用one-hot编码,每个词向量就是8000维;对应的如果有100000个词,那么每个词向量就是100000维。在实际应用中,词向量维度太大,会造成网络参数量大、网络推理速度慢、网络运行占用内存高等问题。

编码过于稀疏
在one-hot编码的词向量中,数值几乎全部是0,非常稀疏,很可能导致实际中网络难以收敛。
无法表示词间的关系
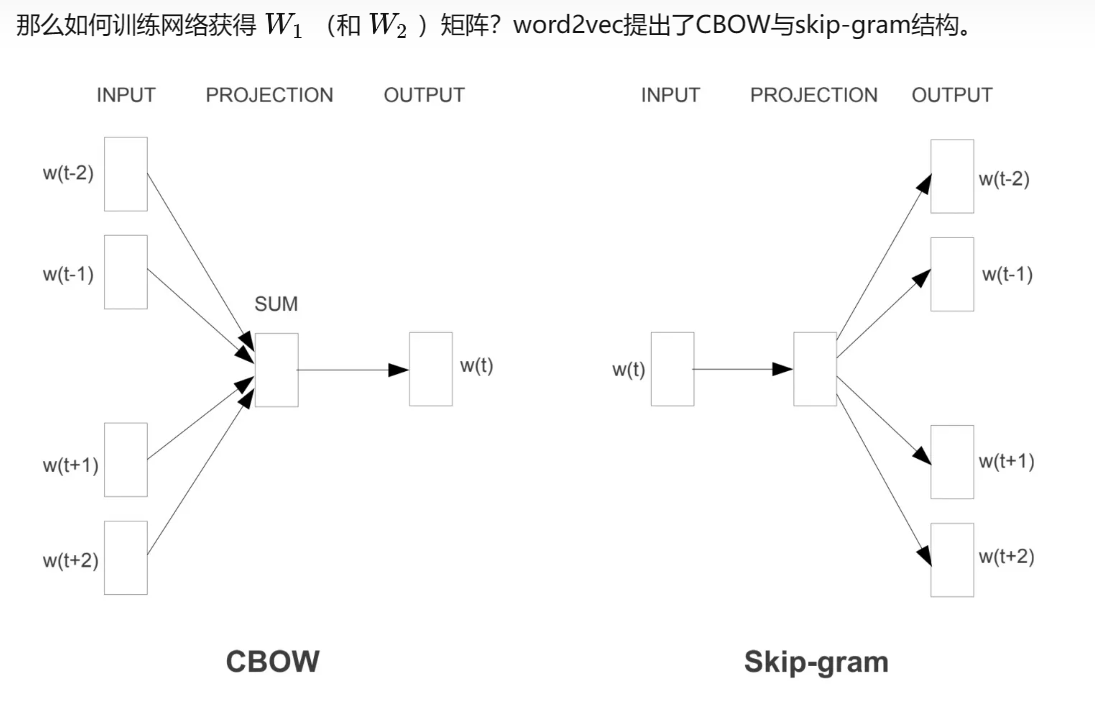
那么不禁要问:有没有一种神经网络,输入每个词的one-hot编码,就可以输出符合上述要求的词向量?有,就是word2vec!
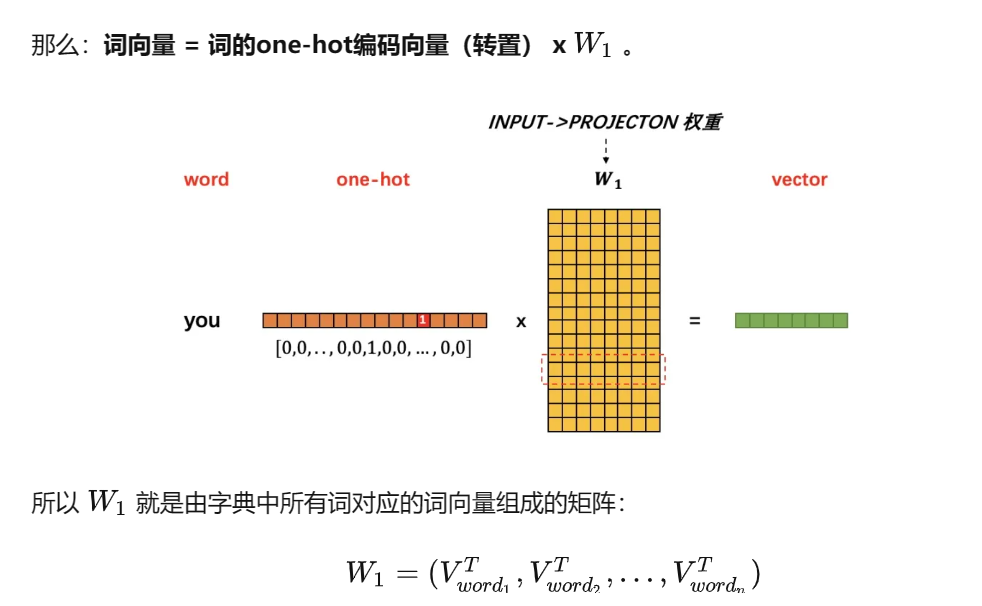
word2vec是一个典型的3层全连接网络:INPUT->PROJECTION->OUTPUT,假设:
INPUT层->PROJECTION层权重为W1 矩阵
PROJECTION层->OUTPUT层权重为 W2 矩阵
W1和W2通过训练得到
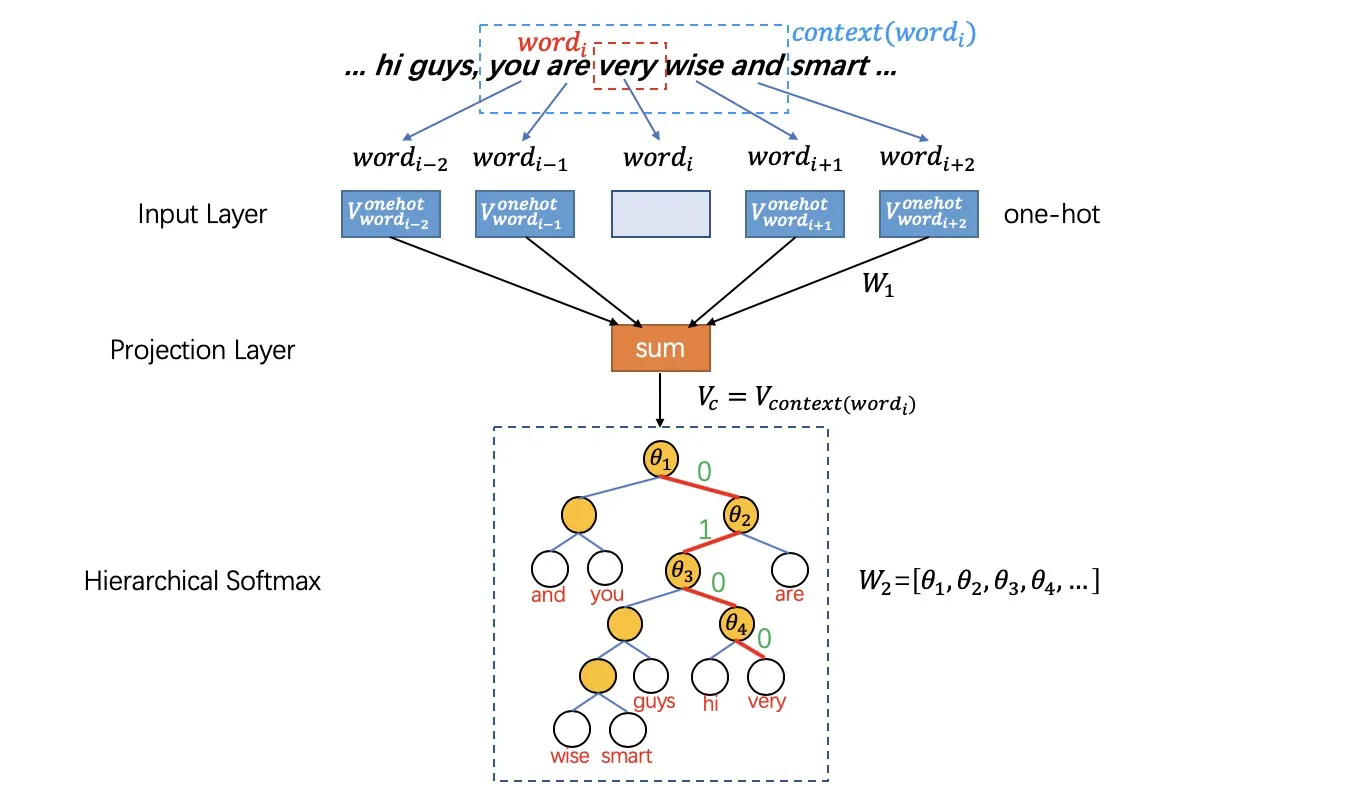
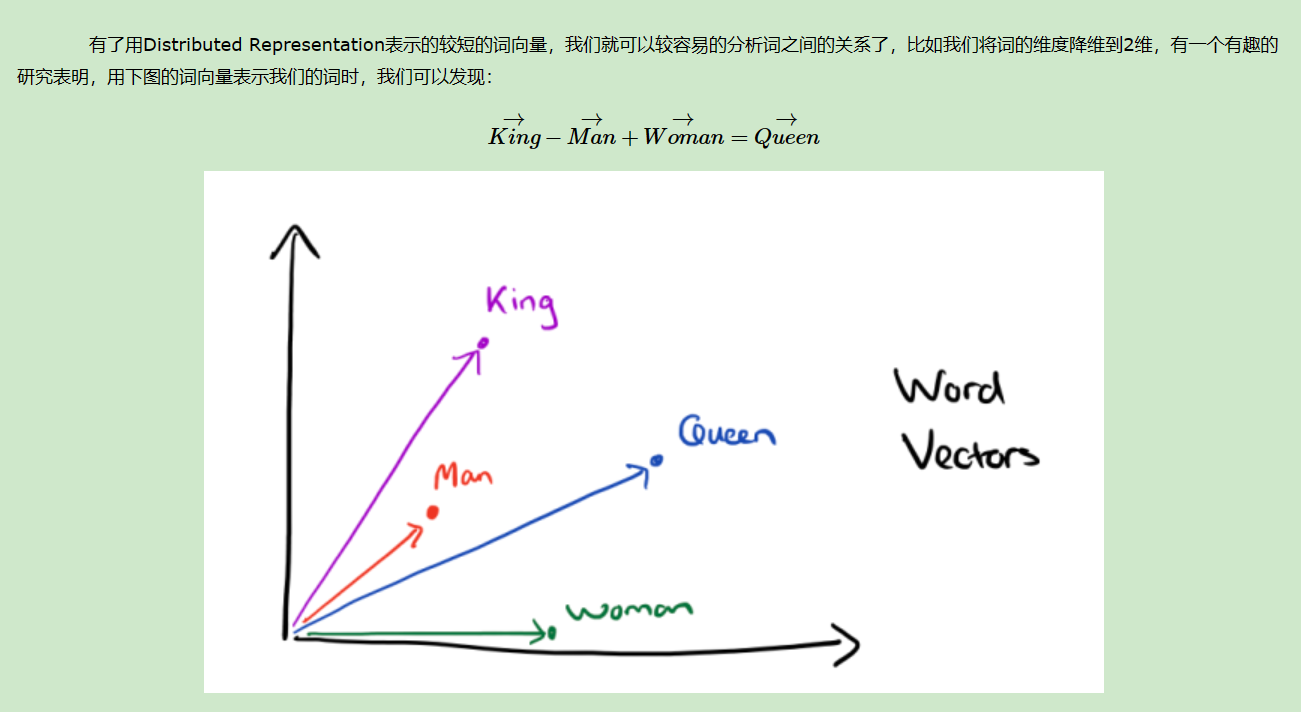
比如下图我们将词汇表里的词用"Royalty",“Masculinity”, "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
1 模型的思想
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。 作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题。
Transformer的提出解决了两个问题:
(1) 首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;
(2) 其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
2 模型的架构
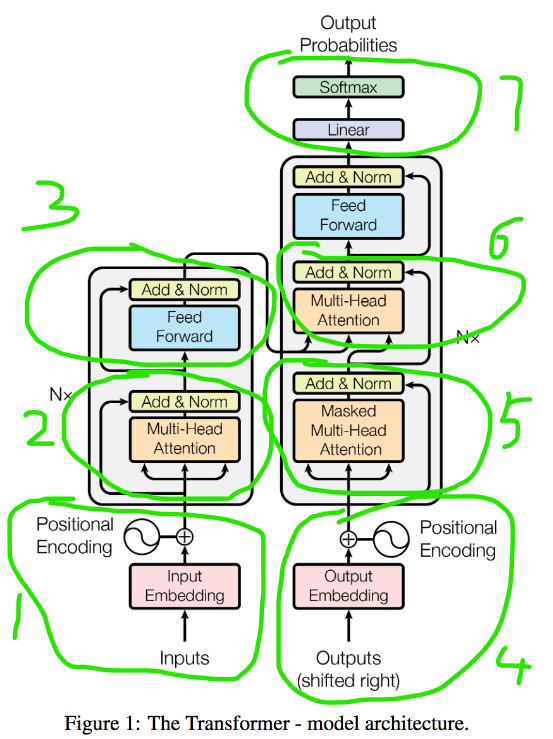
N*指的是所有的encoder和decoder有多个
Encoder部分
1、输入
输入有两部分input Embedding + Position Embedding
input Embedding :word2vec,就是用一个数值向量来表示一个对象的方法
Position Embedding: 使用三角函数sin,cos来进行位置编码
2、注意力机制:关注该关注的
https://zhuanlan.zhihu.com/p/455066289
由h个Self Attention 层并行组成,原文中h=8
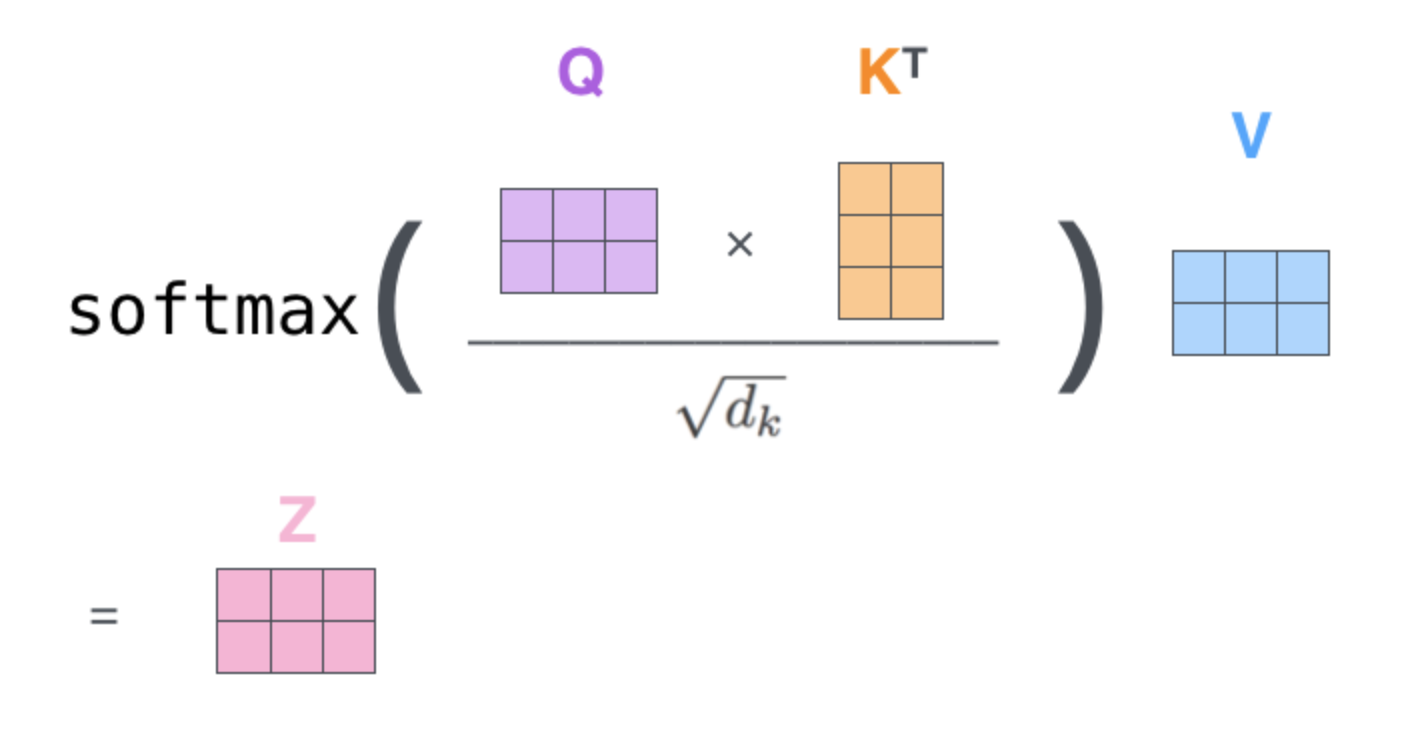
softmax之后值都介于0到1之间,可以理解成得到了 attention weights。然后基于这个 attention weights 对 V 求 weighted sum 值 Attention(Q, K, V)。
3、Add&Norm
add指的是残差
normalize:指的是归一化
4、feed forward:全连接
Feed-Forward Network可以细分为有两层,第一层是一个线性激活函数,第二层是激活函数是ReLU
5、d_model
词嵌入中的维数是指这些向量的长度,
https://zhuanlan.zhihu.com/p/53958685

max_len
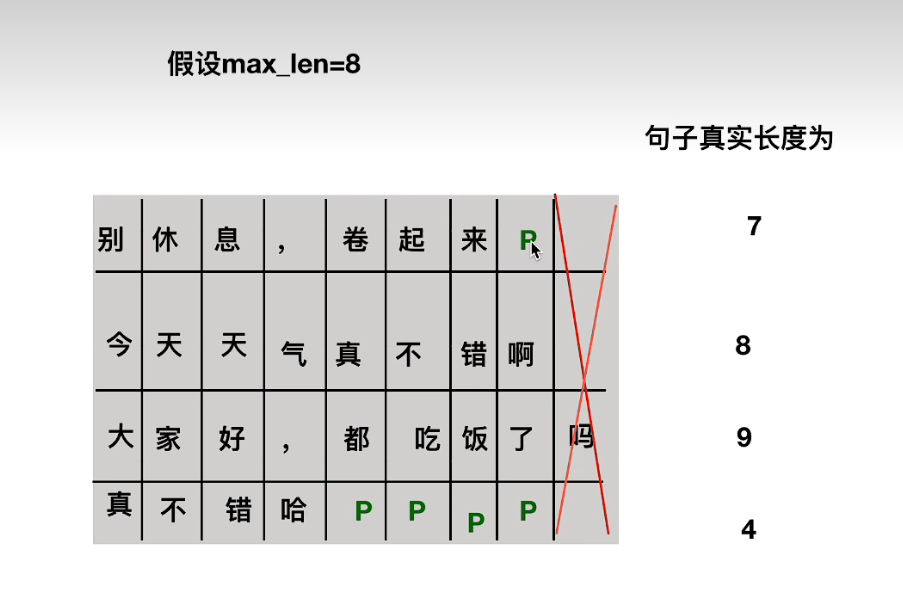
自注意力机制层的mask