
【基础算法】排序算法详述
迪丽瓦拉
2025-05-31 22:17:46
0次
系列综述:
💞目的:本系列是个人整理为了秋招算法的,整理期间苛求每个知识点,平衡理解简易度与深入程度。
🥰来源:材料主要源于代码随想录进行的,每个算法代码参考leetcode高赞回答和其他平台热门博客,其中也可能含有一些的个人思考。
🤭结语:如果有帮到你的地方,就点个赞和关注一下呗,谢谢🎈🎄🌷!!!
🌈【C++】秋招&实习面经汇总篇🌈
文章目录
- 排序算法概述
- 算法简介
- 常见排序算法
- 0.直接插入排序
- 1.冒泡排序
- 2.简单选择排序
- 3.希尔排序
- 4.快速排序
- 5.堆排序
- 6.二路归并排序
- 7.基数排序
- 待续···
- 8.桶排序
- 9.timesort排序
- 10.计数排序
- 参考博客
😊点此到文末惊喜↩︎
排序算法概述
算法简介
- 作用:将一组
无序的记录序列调整为有序的记录序列 - 类型
- 内部排序:待排序列完全
存放在内存中所进行的排序过程,适合不太大的元素序列。 - 外部排序:待排序的记录
存储在外存储器上,通常待排序的文件无法一次装入内存。
- 内部排序:待排序列完全
- 逆序对
- 一个序列中有两个数前面一个数比后面一个数大
- 排序实质就是减少逆序对的过程
- 有序无序分区思想
- 每次通过
某种算法迭代,将无序区的最值添加到有序区后面 - 每次从无序区遍历,不超过个分界线
- 优化:如果迭代一次交换都没有发生的话,是可以说明这个序列都是有序的,可以直接推出。

- 每次通过
- 常见排序算法
- 冒泡排序:属于暴力排序,对cpu的运算负载非常大
- 插入排序,希尔排序,选择排序:属于低阶排序算法,一般用于其他排序算法的辅助性工具
- 堆排序:没有用到辅助性的数组,所以它占用的空间可以忽略为待排序数组的大小,耗时较短,对栈的依赖适中
- 归并排序:用到了辅助性数组,所以占用的空间大约为两倍的待排序数组的大小,耗时最短,对栈的依赖适中(比堆排序稍差)
- 快速排序:没有用到辅助性的数组,所以占用的空间认为是待排序数组的大小,耗时偏短,但对栈的依赖最高,所以递归深度最深
- 桶排序:严格意义上说是一种策略,且桶排序的执行效率与编码人员的综合素质息息相关,是一种下限极低,上限极高的极度自由的排序算法,通常用于大数据量排序
- timeSort:是 jdk 官方默认排序算法,能被官方作为默认的排序算法,必然非常优秀;且它结合了归并排序和插入排序的优点
- 基数排序:用到了辅助性数组,所以占用的空间约为两倍的待排序数组的大小,耗时偏高,但空间复杂度极低,也比较优秀
- 计数排序:用到了模板性的辅助数组,所以占用的空间可以很小,也可以很大,取决于待排序数组的分布情况,但时间复杂度极低,也比较优秀,如果待排序数组的最大最小值较小,可以考虑
- 排序算法口诀:
直冒简希,快堆二基
| 算法种类 | 最好情况 | 平均情况 | 最坏情况 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 直接插入排序 | O(n)O(n)O(n) | O(n2)O(n^2)O(n2) | O(n2)O(n^2)O(n2) | O(1)O(1)O(1) | 是 |
| 冒泡排序 | O(n)O(n)O(n) | O(n2)O(n^2)O(n2) | O(n2)O(n^2)O(n2) | O(1)O(1)O(1) | 是 |
| 简单选择排序 | O(n2)O(n^2)O(n2) | O(n2)O(n^2)O(n2) | O(n2)O(n^2)O(n2) | O(1)O(1)O(1) | 否 |
| 希尔排序 | 适合大规模数据 | O(n1.3)O(n^{1.3})O(n1.3) | O(n2)O(n^2)O(n2) | O(1)O(1)O(1) | 否 |
| 快速排序 | O(nlog2n)O(nlog_2n)O(nlog2n) | O(nlog2n)O(nlog_2n)O(nlog2n) | O(n2)O(n^2)O(n2) | O(log2n)O(log_2n)O(log2n) | 否 |
| 堆排序 | O(nlog2n)O(nlog_2n)O(nlog2n) | O(nlog2n)O(nlog_2n)O(nlog2n) | O(nlog2n)O(nlog_2n)O(nlog2n) | O(1) | 否 |
| 2路归并排序 | O(nlog2n)O(nlog_2n)O(nlog2n) | O(nlog2n)O(nlog_2n)O(nlog2n) | O(nlog2n)O(nlog_2n)O(nlog2n) | O(n)O(n)O(n) | 是 |
| 基数排序 | O(d(n+r))O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r))O(d(n+r)) | O(d(n+r))O(d(n+r))O(d(n+r)) | O(r)O(r)O(r) | 是 |
| 待补充··· |
- 稳定性:若经过排序,记录的相对次序保持不变
- 当n比较小或关键字基本有序的时候,使用直接插入排序。
- 当n比较大,使用O(nlog2n)O(nlog_2n)O(nlog2n)的排序算法
- 快速排序,排序关键字随机分布时,性能表现最好
- 堆排序,辅助空间少,不会出现最坏情况
- 归并排序,排序稳定,不交换相等数据元素
- 数据元素本身信息量比较大,可以使用简单选择排序,减少数据元素的移动次数。或者使用链表作为存储结构。
- n很大且关键字位数少可以分解,可以采用基数排序
常见排序算法
0.直接插入排序
- 算法基本思路:每次迭代时,取无序区的首元素,插入到有序区中适当的位置
- 算法优化:可以在进行插入时,对有序区使用二分查找算法
- 基本算法
void insertSort(vector&nums){// 第一个元素认为已经排序完,共进行n-1轮for (int i = 1; i < nums.size(); ++i){int flag = nums[i]; // 将无序区第一个元素作为待排序元素// 从后向前遍历有序区,找到合适位置插入待排序元素for (int j = i; j >= 0; --j){if (nums[j - 1] > flag){nums[j] = nums[j - 1];}else{// 插入即结束本次迭代nums[j] = flag;break;}}} } 
1.冒泡排序
- 冒泡排序是一个最基础的
交换排序,每次迭代中会有一个数据元素像小气泡一样慢慢上升(下降)到有序区 - 基本算法
void bullbleSort(vector&nums){int n = nums.size();// n个数据元素只需要n-1次排序,因为排完最后一个元素已经有序for(int i = 0; i < n-1; ++i){flag = false;// 发生交换的标志// 每次将无序区间最小的数据元素放到有序区的后面for(int j = n-1; j > i; --j){if(nums[j] < nums[j-1]){swap(nums[j-1], nums[j]);flag = true;}// 本次遍历没有发生交换,说明已经有序if(flag == false)return ;}} } 
2.简单选择排序
- 基本思路: 从无序区中找最小值的下标,与有序区的后一个交换
- 基本算法
void selectSort(vector&nums){int select = 0; // 每次迭代记录无序区中最小的数的下标// 从第一个数开始迭代n-1次,最后一次末尾的两个数值一起排序完成for (int i = 0; i < nums.size() - 1; ++i){// 每次更新最小值下标为初始值select = i;// 从无序区中找到最小值的下标for (int j = i; j < nums.size() - 1; ++j){if (nums[j] < nums[select]){select = j;}}// 交换有序区的后一个和无序区中最小的那个swap(nums[i], nums[select]);} }
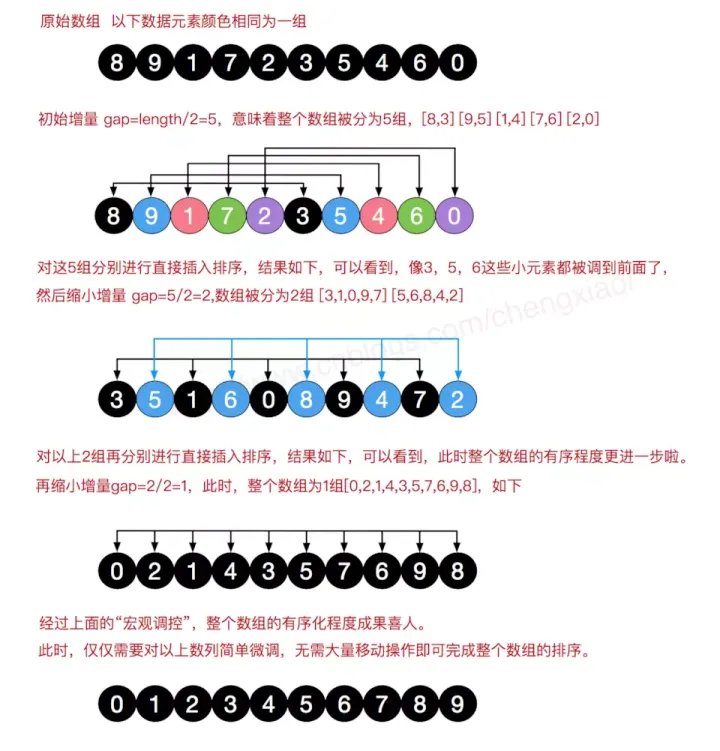
3.希尔排序
- 希尔排序(Shell’s Sort)是插入排序的一种又称“缩小增量排序”,是直接插入排序算法的改进版
- 原理
- 前提:直接插入排序在元素有序的情况下,每次插入一个元素只需要比较一次而不用移动元素,时间复杂度为O(n)
- 每次先取一个小于n的步长d1d_1d1,把表中的全部数据元素相距d1d_1d1的倍数的放在同一组,在各组内进行直接插入排序。然后取第二个步长d2d_2d2
void shell_sort(int arr[], int len) {int gap, i, j;int temp;for (gap = len >> 1; gap > 0; gap >>= 1)for (i = gap; i < len; i++) {temp = arr[i];for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap)arr[j + gap] = arr[j];arr[j + gap] = temp;} }
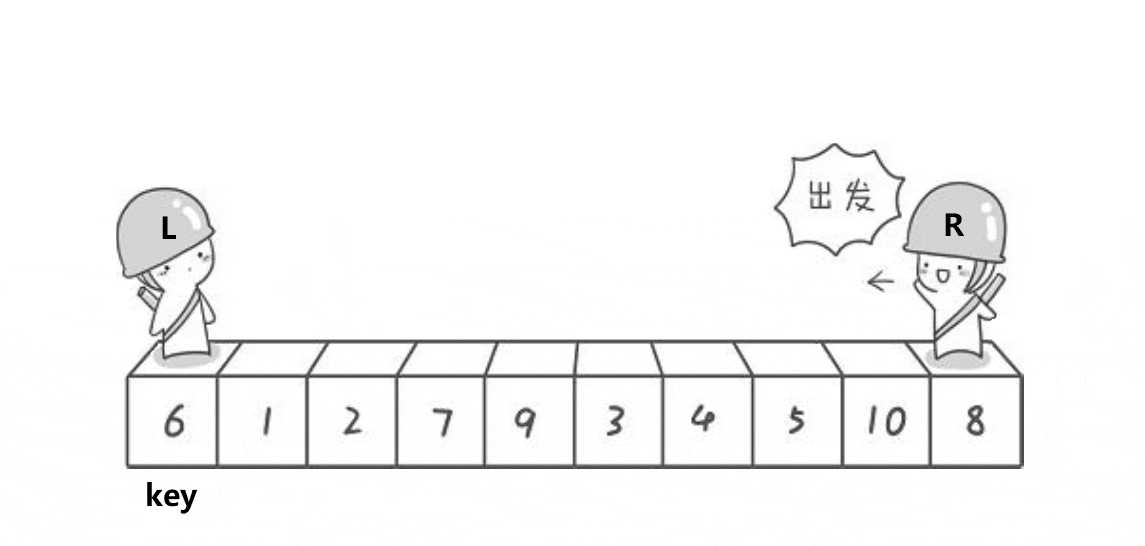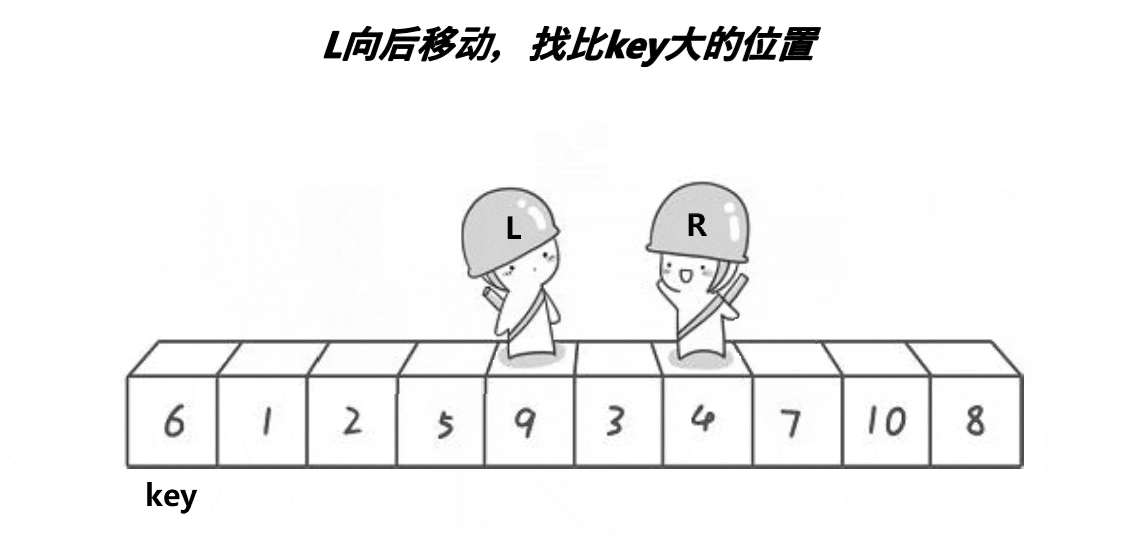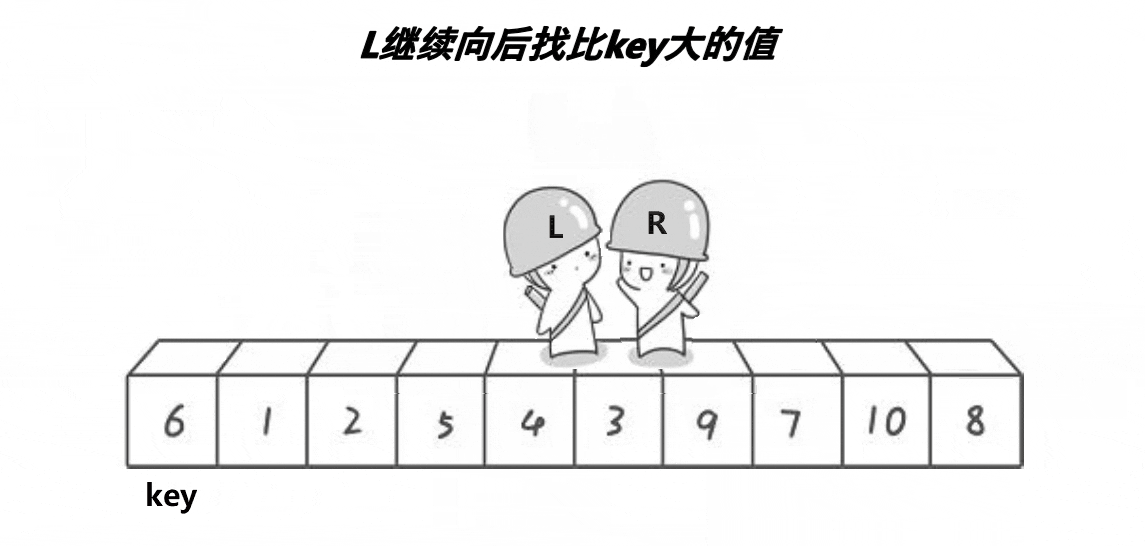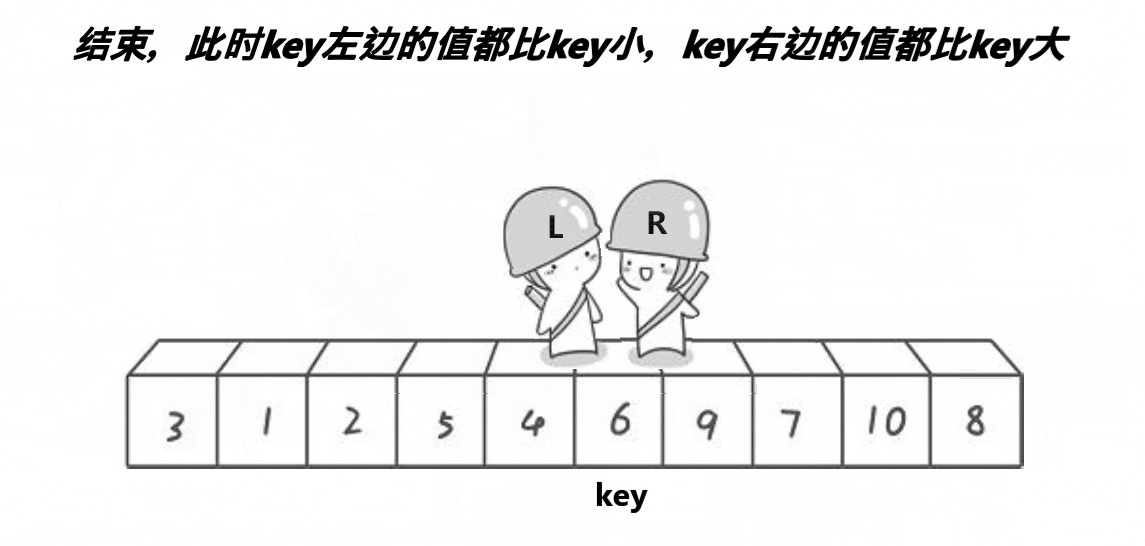
4.快速排序
- 基本思想
- 选择基准:在待排序列中,按照某种方式挑出一个元素,作为 “基准”(pivot)
- 分割操作:以该基准在序列中的实际位置,把序列分成两个子序列。此时,在基准左边的元素都比该基准小,在基准右边的元素都比基准大
- 递归地对两个序列进行快速排序,直到序列为空或者只有一个元素。
- 特点
- 不产生有序子序列,但每次排序后会将基准元素放到最终位置上
- 每次排序划分子区间越相近越能发挥快排优势
- 算法
void QuickSort(vector&nums, int left, int right){ // 递归出口 if (left >= right)return;int low = left; int high = right; // 选第一个元素为枢纽 int pivot = low; while (low < high){// 从后向前找比枢纽小的while (nums[high] >= nums[pivot] && low < high){--high;}// 从前向后找比枢纽大的while (nums[low] <= nums[pivot] && low < high){++low;}// 交换swap(nums[low], nums[high]); } swap(nums[pivot], nums[high]); pivot = high; // 分治[left, pivot+1] pivot [pivot+1, right] QuickSort(nums, left, pivot - 1); QuickSort(nums, pivot + 1, right); }
5.堆排序
- 算法的稳定性:关键字相同的两个元素在排序后顺序不变
- 定义(数组可以使用完全二叉树表示)
- 大根堆
- 在
完全二叉树中,所有根均大于左右子树的值。 - n个关键字序列L[1···n],L(i)>=L(2i)且L(i)>=L(2i+1)L(i) >= L(2i)且L(i)>=L(2i+1)L(i)>=L(2i)且L(i)>=L(2i+1)
- 在
- 小根堆
- 在
完全二叉树中,所有根均小于左右子树的值。 - n个关键字序列L[1···n],L(i)<=L(2i)且L(i)<=L(2i+1)L(i) <= L(2i)且L(i)<=L(2i+1)L(i)<=L(2i)且L(i)<=L(2i+1)
- 在
- 大根堆
- 算法
- 父亲节点为dad,则左孩子为
dad * 2 + 1,右孩子为dad * 2 + 1+1
void max_heapify(int arr[], int start, int end) {//建立父节点指标和子节点指标int dad = start;int son = dad * 2 + 1;// 从0开始计数,所以加一while (son <= end) { //若子节点指标在范围内才做比较if (son + 1 <= end && arr[son] < arr[son + 1]) //先比较两个子节点大小,选择最大的son++;if (arr[dad] > arr[son]) //如果父节点大于子节点代表调整完毕,直接跳出函数return;else { //否则交换父子内容再继续子节点和孙节点比较swap(arr[dad], arr[son]);dad = son;son = dad * 2 + 1;}} } void heap_sort(int arr[], int len) {//初始化,i从最后一个父节点开始调整for (int i = len / 2 - 1; i >= 0; i--)max_heapify(arr, i, len - 1);//先将第一个元素和已经排好的元素前一位做交换,再从新调整(刚调整的元素之前的元素),直到排序完毕for (int i = len - 1; i > 0; i--) {swap(arr[0], arr[i]);max_heapify(arr, 0, i - 1);} }
- 父亲节点为dad,则左孩子为
6.二路归并排序
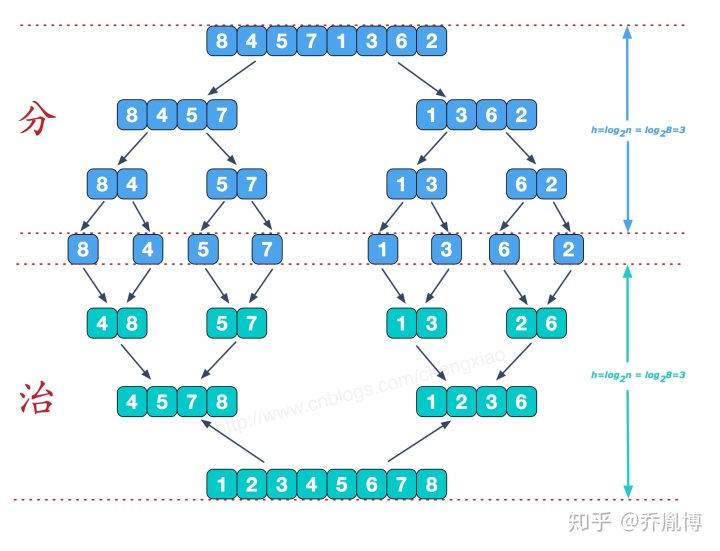
-
原理:采用分治法的思想
- 分:每次划分子序列进行直接插入排序
- 治:将已有序的
两个子序列合并,得到完全有序的新序列
-
优化思路
- 递归:消除递归,避免递归过程的时间消耗。
- 最长无逆序子序列:我们经过分析知道,归并排序的基础是两个有序子序列的合并,那么我们可以通过寻找最长无逆序子序列来优化归并排序的比较次数。例如,(4,5,6,3,7,1)这个序列,我们找到三个无逆序子序列,直接对这三个子序列进行合并即可,减少比较次数。
- 小排序问题:划分为小序列,做直接插入排序,再采用归并排序。
- 不回写:这个策略是最重点要讲述的策略。我们上面两段示例代码中都存在从B写回E的操作,这种写回操作在大排序问题时非常浪费时间,我们就思考一种不回写策略来解决这个问题。
-
算法
// 分治法:先划分后合并 void mergeSort(ElemType A[],int low,int high){// 当数组被划分成单独的元素,则low>=high时跳出递归if(low < high){ //划分规则 中点 int mid = (low + high)/2; mergeSort(A,low,mid);mergeSort(A,mid+1,high);//一次划分 一次合并merge(A,low,mid,high); } } // 合并函数:将A[low..mid] 和 A[mid+1...high]进行合并 void merge(ElemType A[],int low,int mid,int high){//B里暂存A的数据 for(int k = low ; k < high + 1 ; k++){B[k] = A[k]; } /*这里对即将合并的两个数组 *A[low..mid] 头元素 A[i]和 A[mid+1...high] 头元素 A[j] *进行一个头部的标记, 分别表示为数组片段的第一个元素 *k 是目前插入位置。 */ int i = low , j = mid + 1 , k = low; //只有在这种情况下 才不会越界 while(i < mid + 1 && j < high + 1) {//A的元素暂存在B里,因为不能再A上原地操作,会打乱数据//这也是为什么二路归并排序(合并排序)空间复杂度是O(n)的原因 //我们这里把值小的放在前面,最后排序结果就是从小到大 if(B[i] > B[j]){A[k++] = B[j++]; }else{A[k++] = B[i++]; } } //循环结束后,会有一个没有遍历结束的数组段。处理上文的情况2while(i < mid + 1) A[k++] = B[i++]; while(j < high + 1) A[k++] = B[j++]; }
7.基数排序
- 基数排序是一种非比较型整数排序算法。当待排序数据是不太大的自然数(均满足 <=m )时,把待排序数据当作数组下标处理,时间复杂度是 O(m+n)O(m+n)O(m+n),并额外有O(m)O(m)O(m)的空间复杂度。
- 原理
- 将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。
- 从最低位开始,依次进行一次排序。
- 这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
- 代码
int maxbit(int data[], int n) //辅助函数,求数据的最大位数 {int maxData = data[0]; ///< 最大数/// 先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。for (int i = 1; i < n; ++i){if (maxData < data[i])maxData = data[i];}int d = 1;int p = 10;while (maxData >= p){//p *= 10; // Maybe overflowmaxData /= 10;++d;}return d; /* int d = 1; //保存最大的位数int p = 10;for(int i = 0; i < n; ++i){while(data[i] >= p){p *= 10;++d;}}return d;*/ } void radixsort(int data[], int n) //基数排序 {int d = maxbit(data, n);int *tmp = new int[n];int *count = new int[10]; //计数器int i, j, k;int radix = 1;for(i = 1; i <= d; i++) //进行d次排序{for(j = 0; j < 10; j++)count[j] = 0; //每次分配前清空计数器for(j = 0; j < n; j++){k = (data[j] / radix) % 10; //统计每个桶中的记录数count[k]++;}for(j = 1; j < 10; j++)count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶for(j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到tmp中{k = (data[j] / radix) % 10;tmp[count[k] - 1] = data[j];count[k]--;}for(j = 0; j < n; j++) //将临时数组的内容复制到data中data[j] = tmp[j];radix = radix * 10;}delete []tmp;delete []count;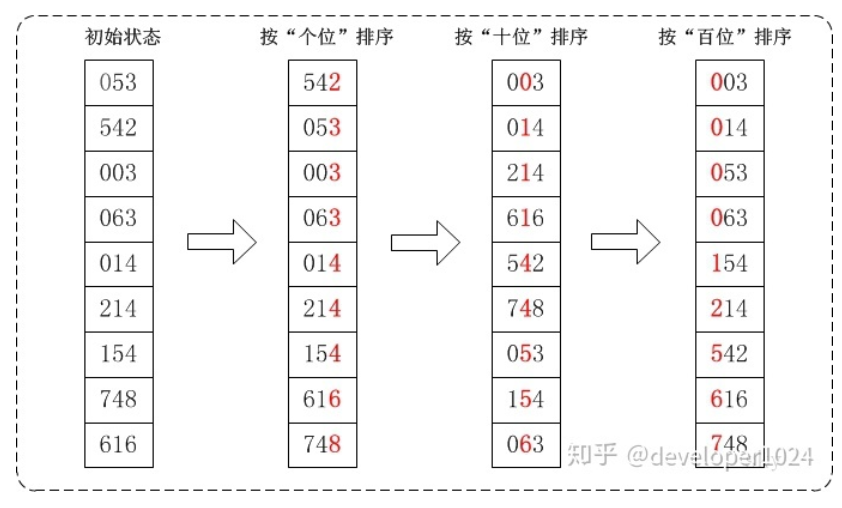
待续···
8.桶排序
9.timesort排序
10.计数排序

🚩点此跳转到首行↩︎
参考博客
- 11 种 内部排序算法 大PK(Java 语言实现),究竟谁最快?
- 百度百科-排序
- 六大排序算法:插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序
- 菜鸟教程-希尔排序
- 堆排序
- 二路归并
- 排序算法——归并排序(二路归并)
- 算法设计与分析(4)——归并排序过程、时间复杂度分析及改进
- 计数排序
上一篇:安装flume
相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
A.机器学习入门算法(三):基...
机器学习算法(三):K近邻(k-nearest neigh...
数字温湿度传感器DHT11模块...
模块实例https://blog.csdn.net/qq_38393591/article/deta...
有限元三角形单元的等效节点力
文章目录前言一、重新复习一下有限元三角形单元的理论1、三角形单元的形函数(Nÿ...
Redis 所有支持的数据结构...
Redis 是一种开源的基于键值对存储的 NoSQL 数据库,支持多种数据结构。以下是...
win下pytorch安装—c...
安装目录一、cuda安装1.1、cuda版本选择1.2、下载安装二、cudnn安装三、pytorch...
MySQL基础-多表查询
文章目录MySQL基础-多表查询一、案例及引入1、基础概念2、笛卡尔积的理解二、多表查询的分类1、等...
keil调试专题篇
调试的前提是需要连接调试器比如STLINK。 然后点击菜单或者快捷图标均可进入调试模式。 如果前面...
MATLAB | 全网最详细网...
一篇超超超长,超超超全面网络图绘制教程,本篇基本能讲清楚所有绘制要点&#...
IHome主页 - 让你的浏览...
随着互联网的发展,人们越来越离不开浏览器了。每天上班、学习、娱乐,浏览器...
TCP 协议
一、TCP 协议概念 TCP即传输控制协议(Transmission Control ...
营业执照的经营范围有哪些
营业执照的经营范围有哪些 经营范围是指企业可以从事的生产经营与服务项目,是进行公司注册...
C++ 可变体(variant...
一、可变体(variant) 基础用法 Union的问题: 无法知道当前使用的类型是什...
血压计语音芯片,电子医疗设备声...
语音电子血压计是带有语音提示功能的电子血压计,测量前至测量结果全程语音播报...
MySQL OCP888题解0...
文章目录1、原题1.1、英文原题1.2、答案2、题目解析2.1、题干解析2.2、选项解析3、知识点3...
【2023-Pytorch-检...
(肆十二想说的一些话)Yolo这个系列我们已经更新了大概一年的时间,现在基本的流程也走走通了,包含数...
实战项目:保险行业用户分类
这里写目录标题1、项目介绍1.1 行业背景1.2 数据介绍2、代码实现导入数据探索数据处理列标签名异...
记录--我在前端干工地(thr...
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前段时间接触了Th...
43 openEuler搭建A...
文章目录43 openEuler搭建Apache服务器-配置文件说明和管理模块43.1 配置文件说明...