
VMware—Ubuntu-Hadoop配置
VMware—Ubuntu-Hadoop配置
文章目录
- VMware—Ubuntu-Hadoop配置
- Hadoop安装
- 关于怎么
- 坑
- 关于为什么
- 坑:
- 关于在哪
- 关于软件
- hadoop模式的切换【伪分布/单机】
- Linux中的环境变量等级
- hdfs的定义
- source命令:
- hadoop-localhost:50070的启动
- 单机模式 & 伪分布模式
- 伪分布模式使用HDFS步骤
- DFS资源显示全为0
- **解决方法**
- export环境变量配置问题-root/hadoop权限相关
- /etc/profile
Hadoop安装
关于怎么
Linux下java和javac版本不同(设置用户默认的java版本)解决方法
cmd命令行运行java文件(javac、java)
linux 卸载jdk和安装
更改linux文件的拥有者及用户组(chown和chgrp)
linux移动文件、文件夹到另一个文件夹-mv 源文件/文件夹地址 目标地址
hadoop: hdfs:删除文件、文件夹等常用命令
坑
解决Permission denied: user=root, access=WRITE, inode=“/“:root:supergroup:drwxr-xr-x问题-现在看来配置文件有点不太好使
Hadoop 警告 : WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException 解决办法
关于为什么
windows宿主机如何SSH连接VMware的Linux虚拟机
hadoop集群搭建必须用root用户吗
坑:
hadoop为什么需要在 hadoop-env.sh 重新配置JAVA_HOME-什么守护进程的原理问题,现在搞不懂
etc/profile和~/.bashrc的区别
关于在哪
Hadoop中HDFS的文件到底存储在集群节点本地文件系统哪里
关于软件
Ubuntu20.04解决应用中心打不开的问题-卸载snap->apt-install Ubuntu store
启动hadoop报出一串警告-jdk问题-要1.8
hadoop模式的切换【伪分布/单机】
关键在于对core-site.xml文件的修改
加上以下的配置语句则是伪分布模式,不加就是非分布(单机)模式
hadoop.tmp.dir file:/usr/local/hadoop/tmp Abase for other temporary directories. fs.defaultFS hdfs://localhost:9000 Linux中的环境变量等级
Linux中环境变量包括系统级和用户级,系统级的环境变量是每个登录到系统的用户都要读取的系统变量,而用户级的环境变量则是该用户使用系统时加载的环境变量。
所以管理环境变量的文件也分为系统级和用户级的:
1.系统级:
(1)/etc/profile:该文件是用户登录时,操作系统定制用户环境时使用的第一个文件,应用于登录到系统的每一个用户。该文件一般是调用/etc/bash.bashrc文件。
/etc/bash.bashrc:系统级的bashrc文件。
(2)/etc/environment:在登录时操作系统使用的第二个文件,系统在读取你自己的profile前,设置环境文件的环境变量。
2.用户级(这些文件处于家目录下):
(1)~/.profile:每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件。这里是推荐放置个人设置的地方
(2)~/.bashrc:该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该该文件被读取。不推荐放到这儿,因为每开一个shell,这个文件会读取一次,效率肯定有影响。
etc/profile和~/.bashrc的区别
- /etc/profile: 用来设置系统环境参数,比如$PATH. 这里面的环境变量是对系统内所有用户生效的。
- /etc/bashrc: 这个文件设置系统bash shell相关的东西,对系统内所有用户生效。只要用户运行bash命令,那么这里面的东西就在起作用。
- ~/.bash_profile: 用来设置一些环境变量,功能和/etc/profile 类似,但是这个是针对用户来设定的,也就是说,你在/home/user1/.bash_profile 中设定了环境变量,那么这个环境变量只针对 user1 这个用户生效.
- ~/.bashrc: 作用类似于/etc/bashrc, 只是针对用户自己而言,不对其他用户生效。
另外/etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承/etc/profile中的变量,他们是"父子"关系.
- ~/.bash_profile 是交互式、login 方式进入 bash 运行的,意思是只有用户登录时才会生效。
- ~/.bashrc 是交互式 non-login 方式进入 bash 运行的,用户不一定登录,只要以该用户身份运行命令行就会读取该文件。
hdfs的定义
hdfs是文件系统,但本质上并没有格式化本机上的硬盘,所以其实只是硬盘上的一种特殊的文件储存格式,并且必须通过IP:PORT进行访问。实质上在配置并启动了集群之后,集群之间便会进行网络通信,并通过namenode的IP和指定端口(50070)对外提供访问。
source命令:
source命令也称为“点命令”,也就是一个点符号(.)。source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。
用法:
source filename 或 . filename
hadoop-localhost:50070的启动
- 先要
hdfs namenode -format格式化节点
hadoop之为什么不能一直格式化namenode
namenode和datanode要保持集群id的一致, 一直格式化namenode会产生新的集群id, 导致namenode和datanode的集群id不一致,集群找不到以往数据所以,格式化NameNode前,先关闭掉NameNode和DataNode,然后一定要删除data数据和log日志。最后再进行格式化。
在hadoop-2.9.2/data/tmp/dfs/name/current/VERSION中可查到NameNode标识id
在hadoop-2.9.2/data/tmp/dfs/data/current/VERSION中可查到DataNode标识id
-
然后在
/usr/local/hadoop/sbin/下启动start-dfs.sh进行NameNode 和 DataNode 守护进程的开启. -
然后用
jps来展示相关的启动进行, 从而判断是否启动成功, 要有以下四个进程才算启动成功- Jps
- SecondaryNameNode
- NameNode
- DataNode
-
最后登录
localhost:50070查看NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
单机模式 & 伪分布模式
单机模式读取的是本地数据,伪分布式读取的则是 HDFS 上的数据
伪分布模式使用HDFS步骤
hdfs/hadoop这些指令都在hadoop/bin里面
core-site.xml这种配置文件在hadoop/etc/hadoop里面
start-dfs.sh这种启动命令在hadoop/sbin里面
-
要使用 HDFS,首先需要在 HDFS 中创建用户目录:
./hadoop fs -mkdir -p /user/hadoop这时候我用root是可以正常执行的
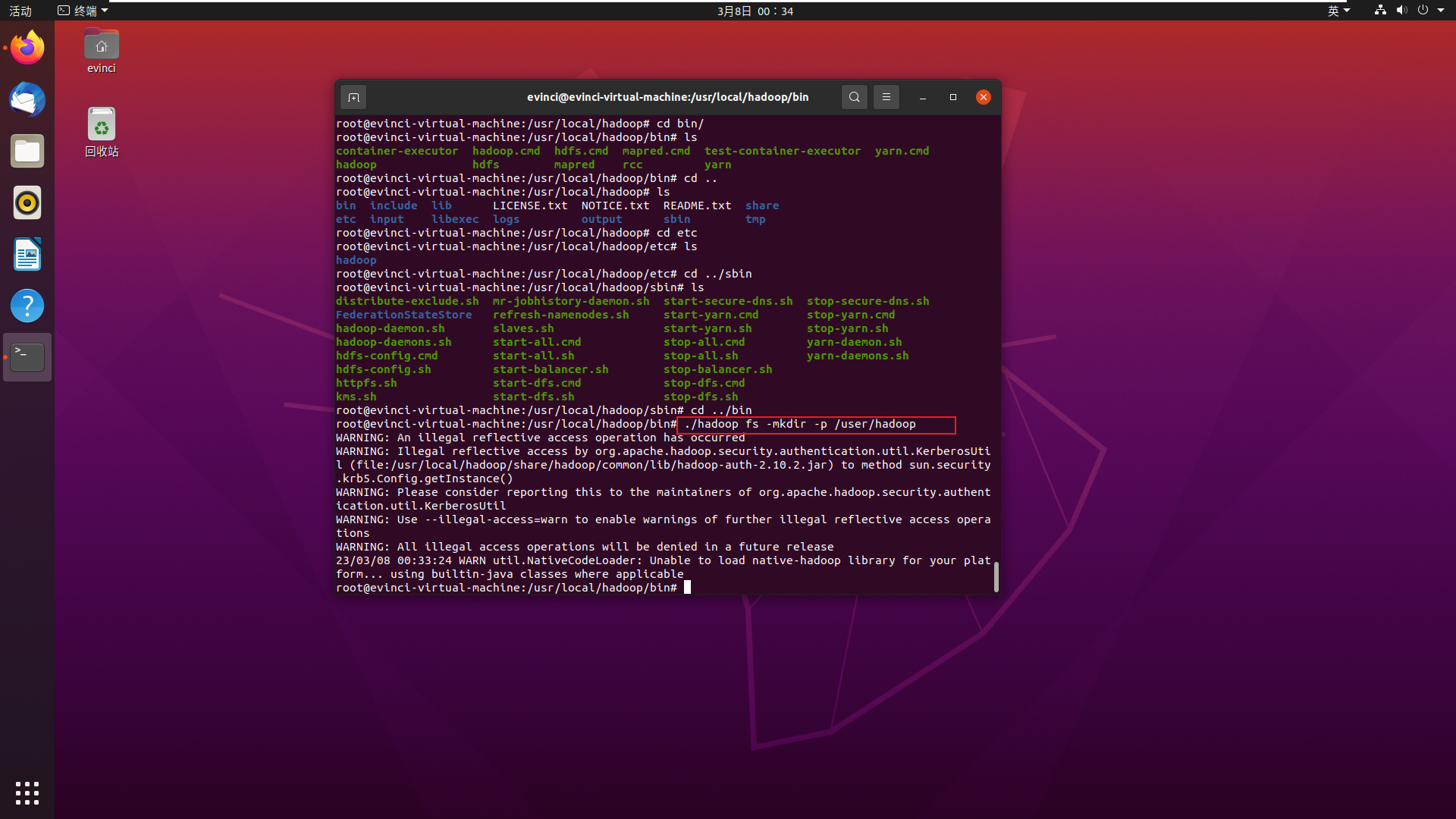
-
接下来我切换到hadoop用户进行下面的操作
-
接着将./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input ./bin/hdfs dfs -put ./etc/hadoop/*.xml inputDFS资源显示全为0
产生以下报错:
WARN hdfs.DataStreamer: DataStreamer Exception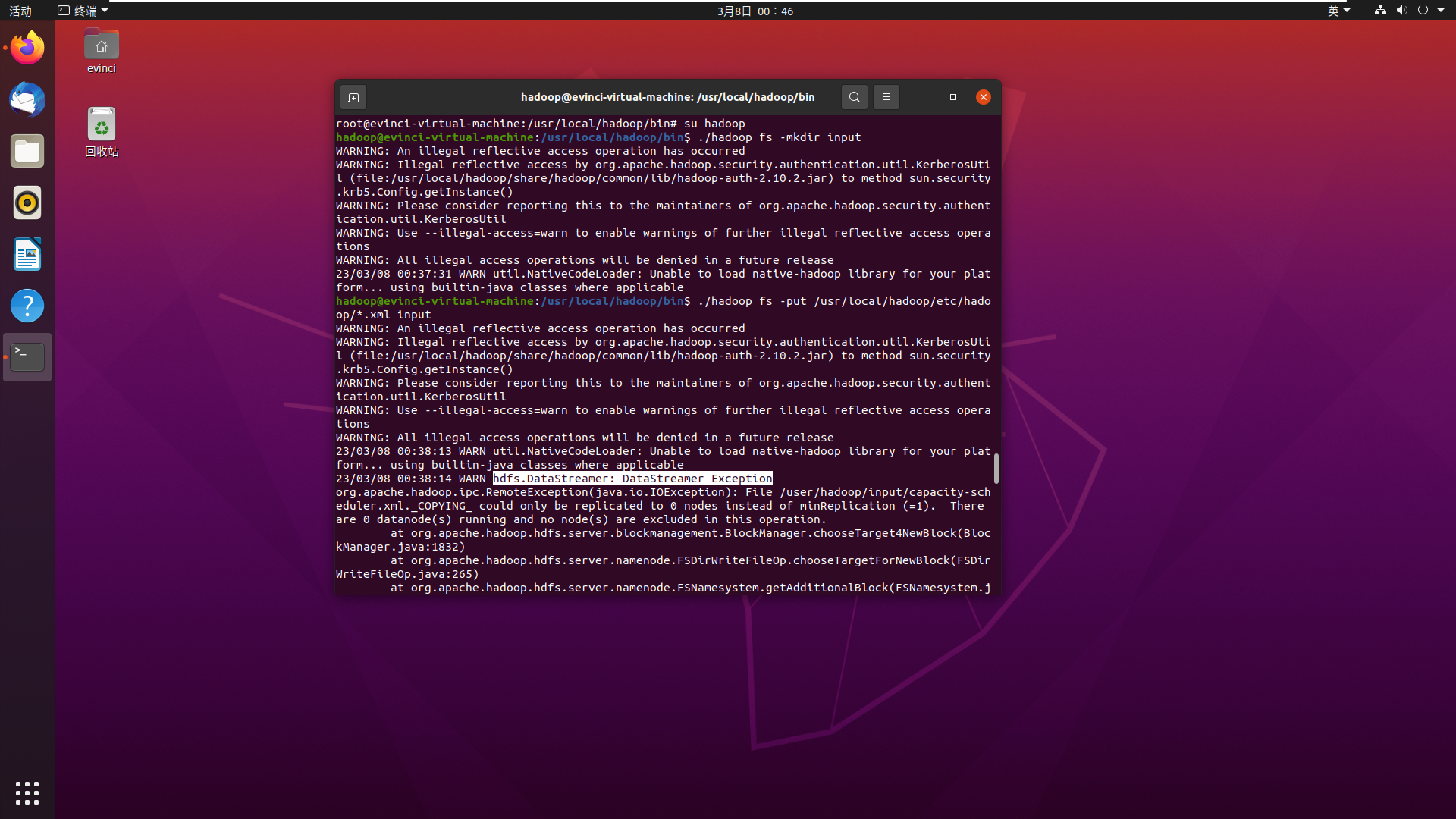
查询原因后发现:
Hadoop 警告 : WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException 解决办法
可能是第二次进行namenode格式化的时候与datanode的集群id不一致了, 所以要删除所有的临时文件然后从新格式化
- 要先停止集群**
stop-all.sh** - 然后删除在hdfs中配置的data目录(就是在
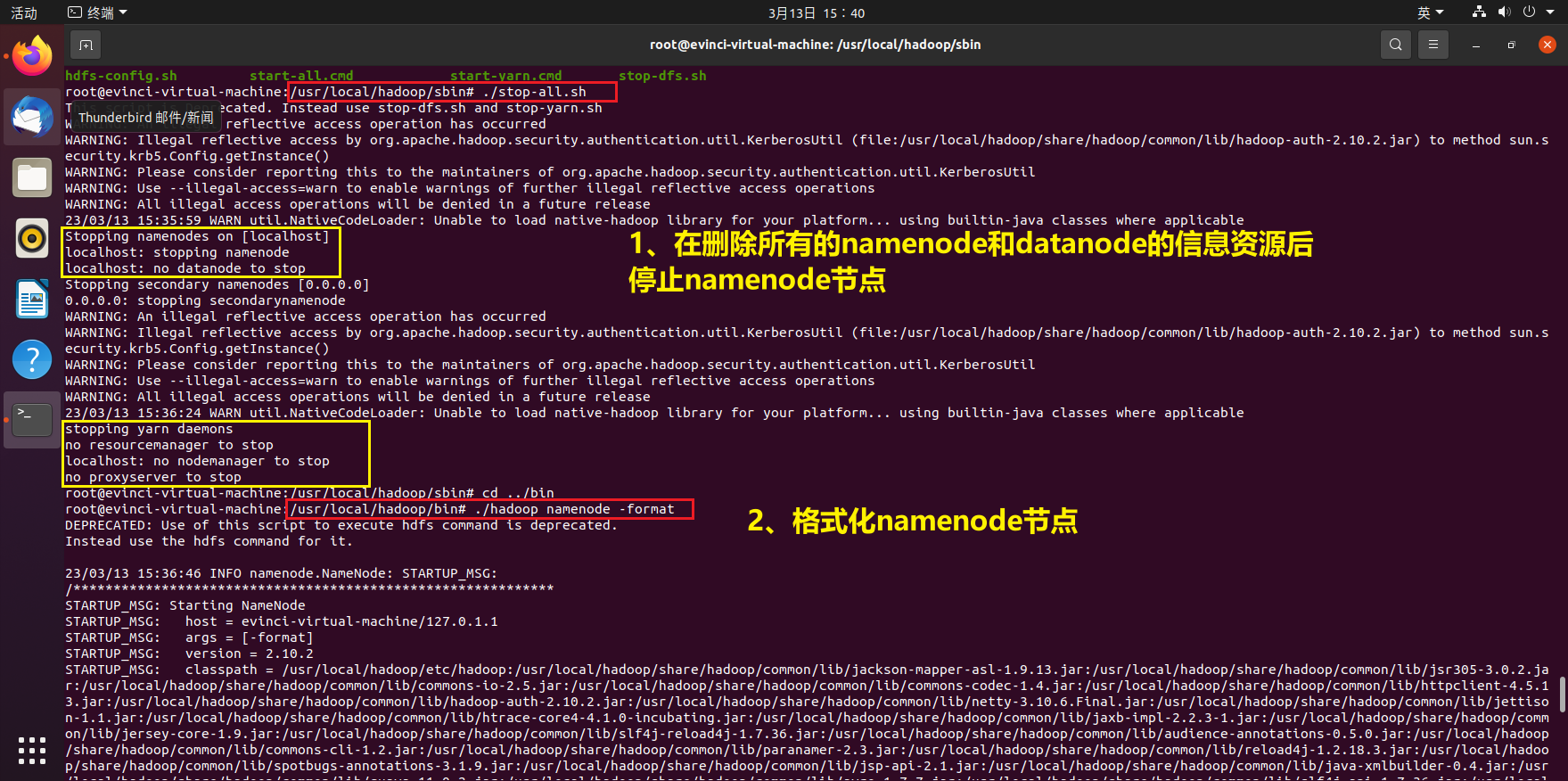
core-site.xml中配置的hadoop.tmp.dir对应的文件)下面的所有数据**rm -rf /home/user1/hadoop2.7/hadoopdata/***(注意这里的目录就是你core-site.xml中配置的hadoop.tmp.dir对应的目录) - 接着重新格式化namenode(需要切换到bin目录)
./hadoop namenode -format - 最后重新启动hadoop集群
看了以下
localhost:50070, 发现确实不对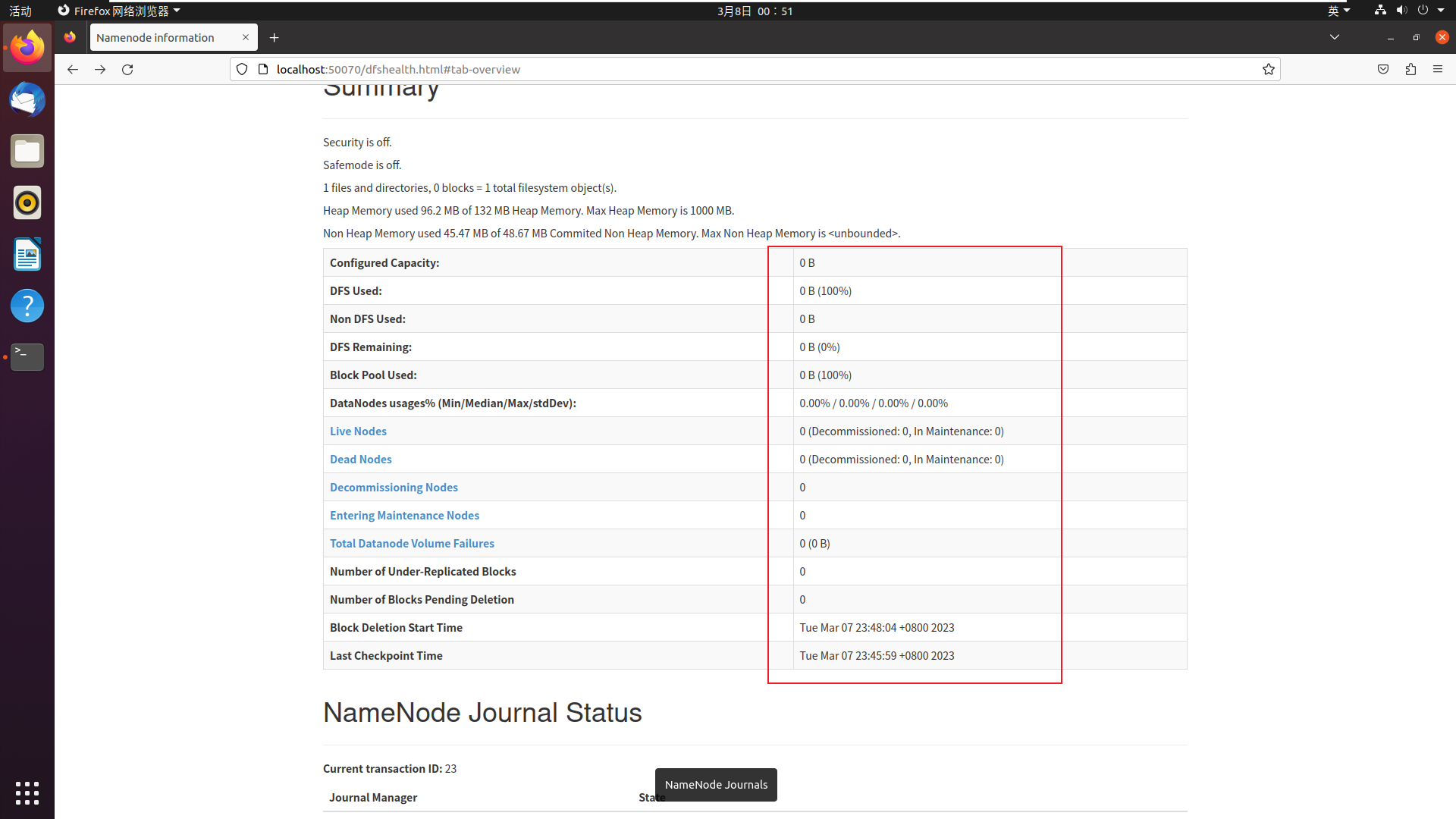
- 要先停止集群**
-
-
查看下**/usr/local/hadoop/tmp/dfs/data/current下VERSION的clusterID**
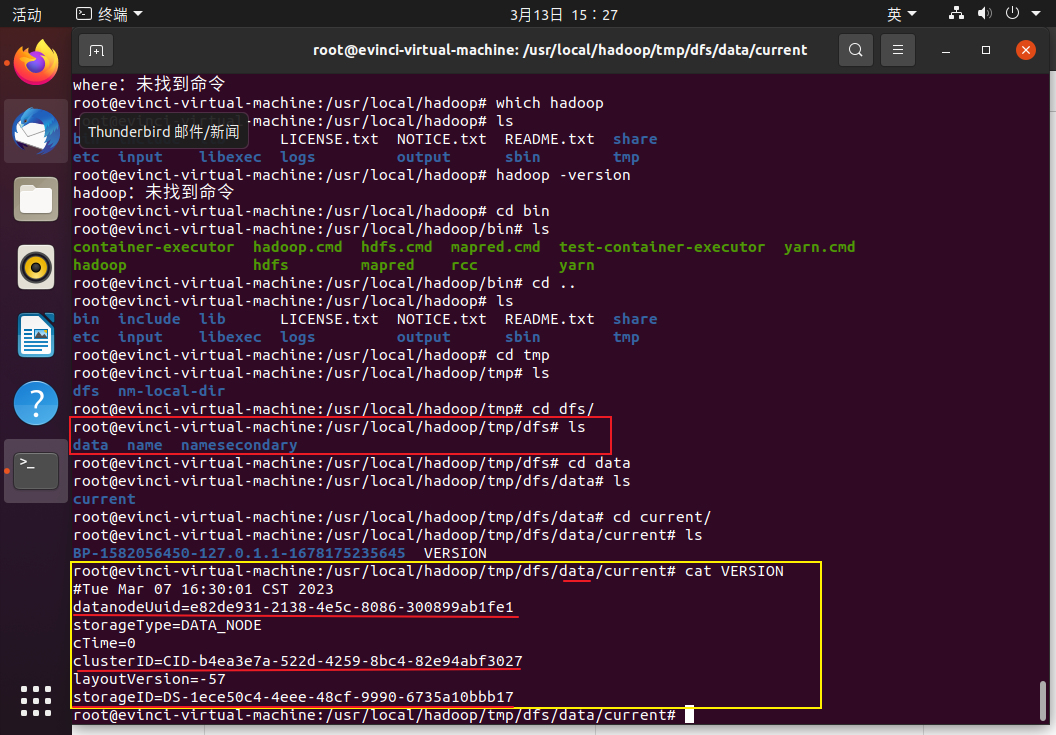
-
查看namenode节点的集群号
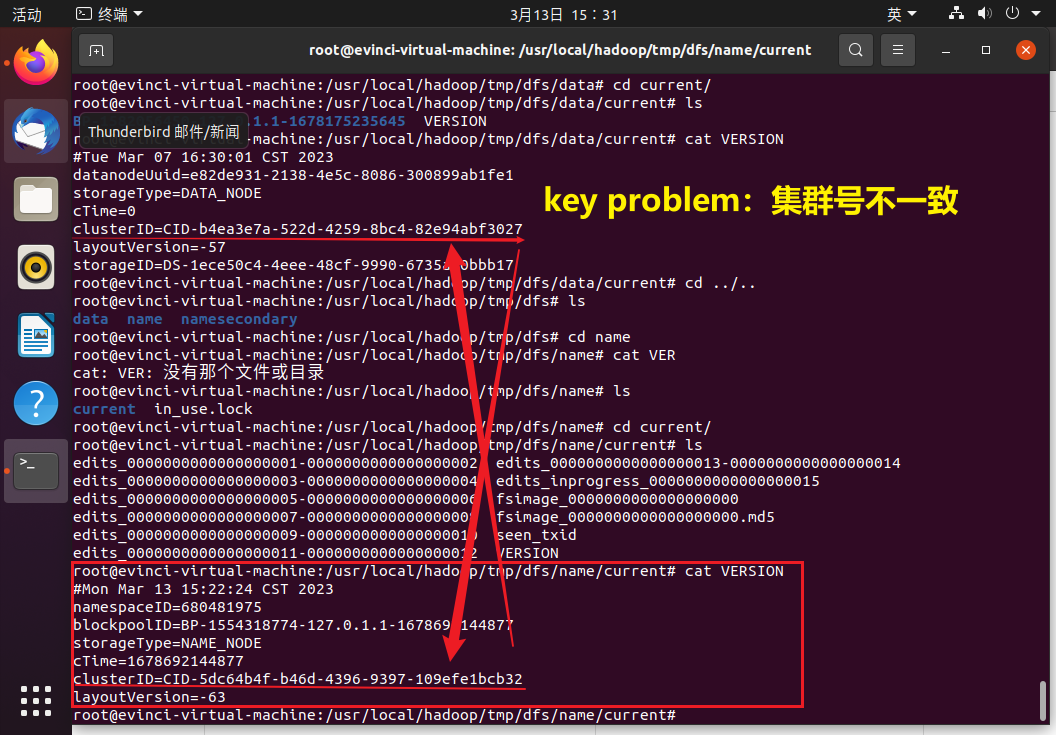
发现两个clusterID的确不同
解决方法
-
根据上述步骤删除所有节点资源信息,然后格式化namenode节点
-
格式化namenode节点过程中的配置信息显示如下:
我虽然看不懂,但是感觉还是很有信息意义的
-
查看下新的clusterID,并重新执行
./start-dfs.sh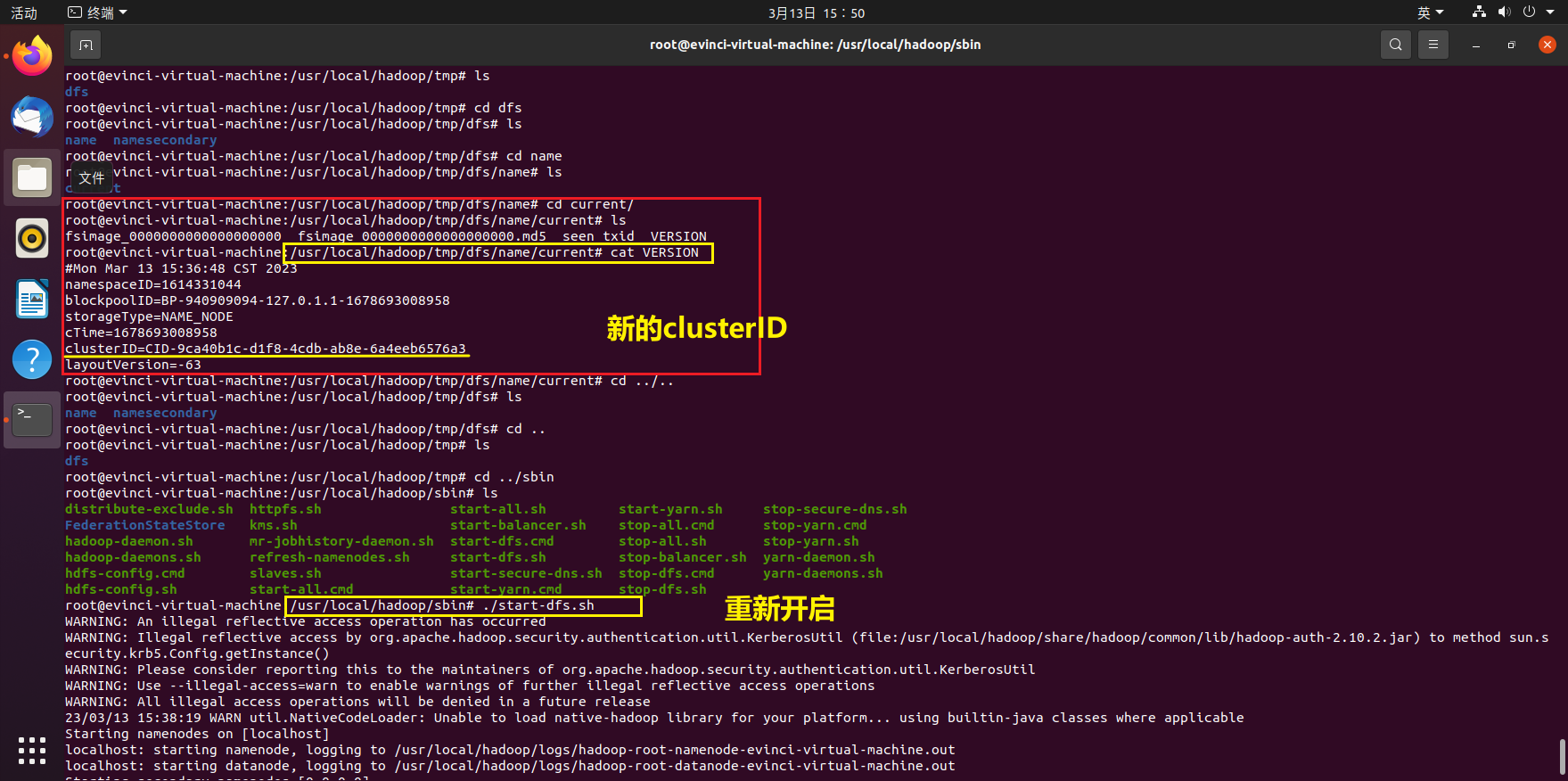
-
打开localhost:50070
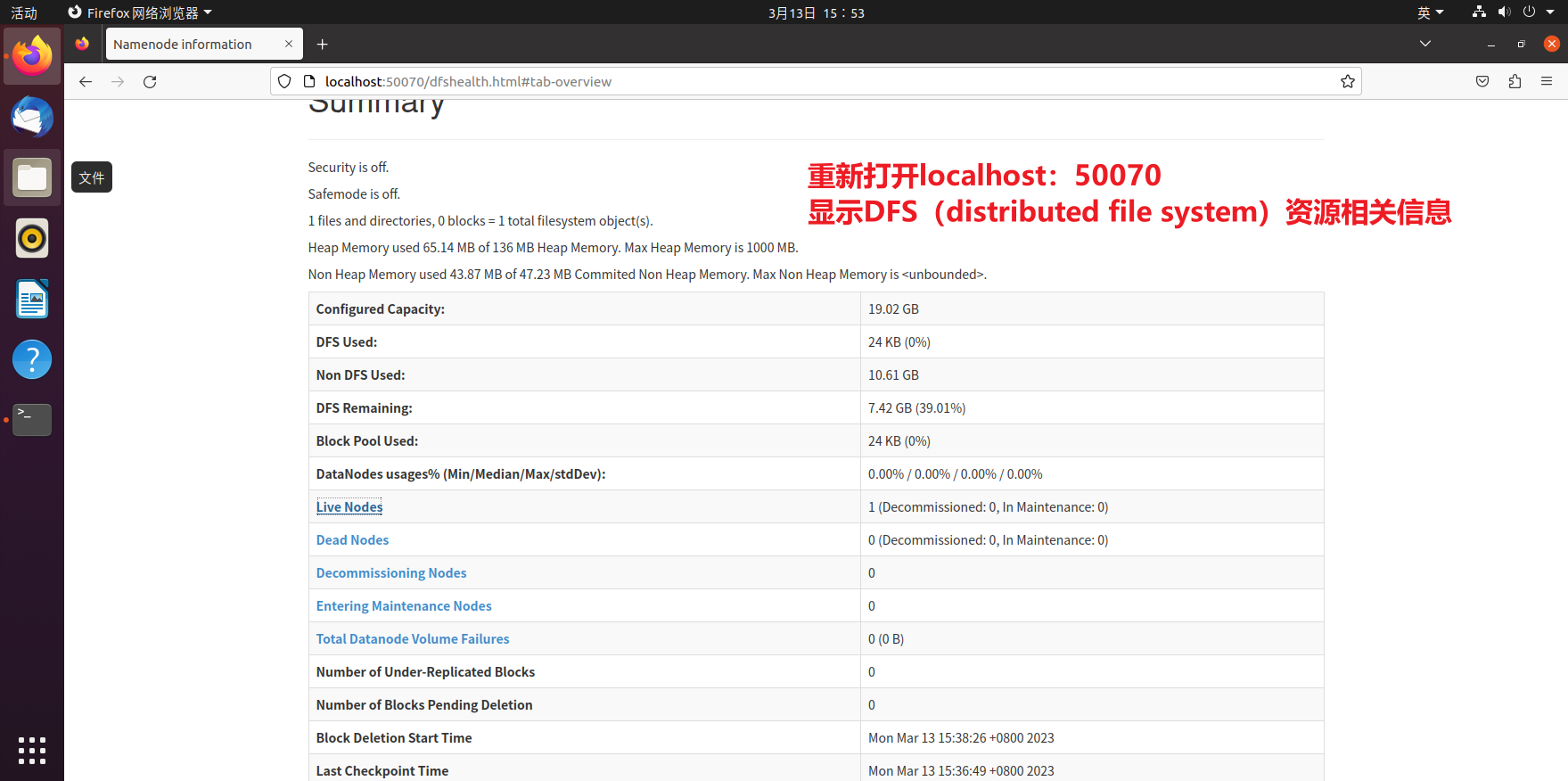
-
-
我用hadoop无法进行
stop-all.sh命令, 只有用root才可以, 这令我怀疑hadoop到底有没有管理员权限? 还是说这个服务只有root才能开启关闭? 还是说我开启的时候用的是root, 所以关闭也必须是root?显然这里有一个用户权限的问题
-
hadoop执行情况
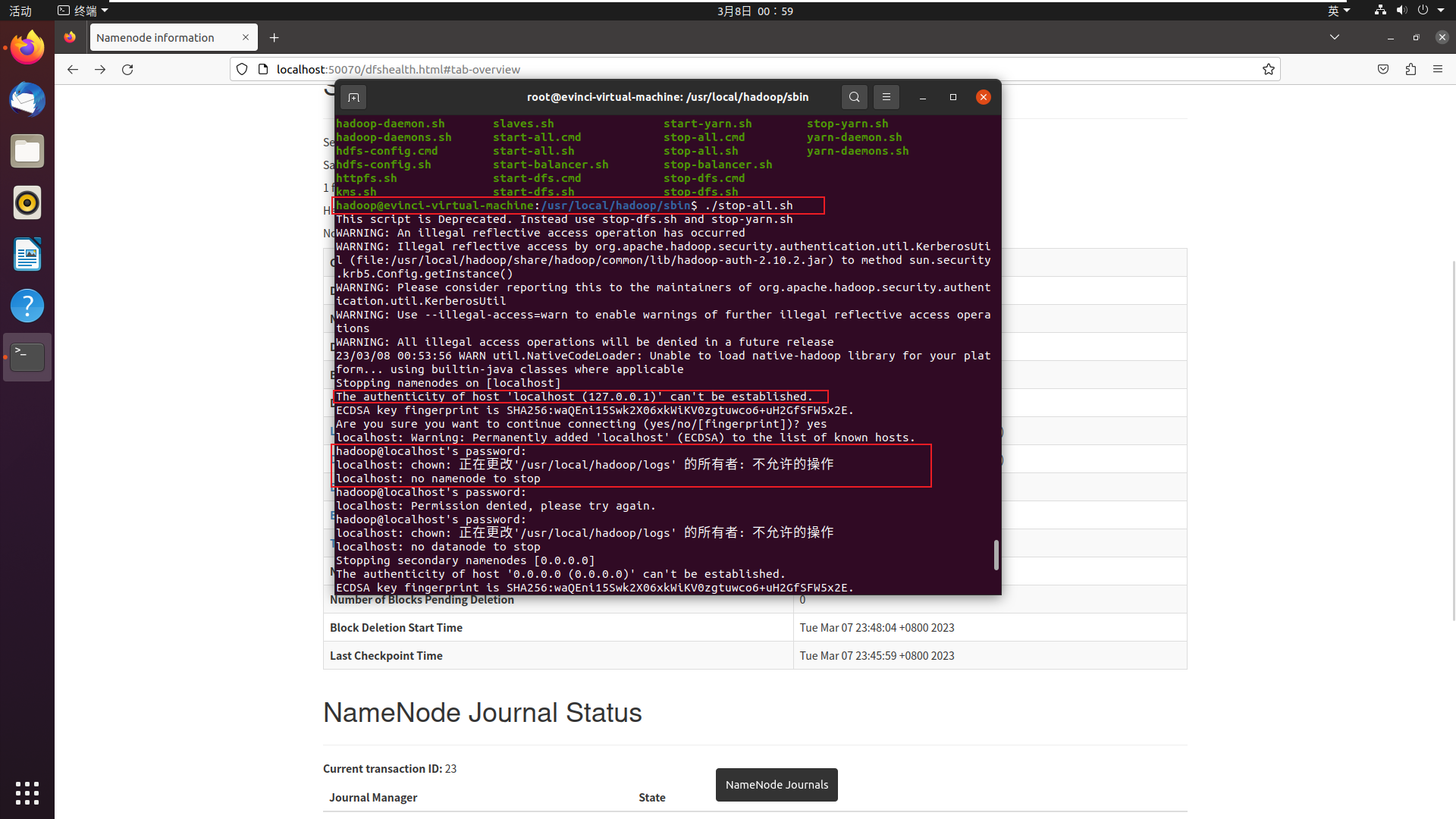
-
root执行情况
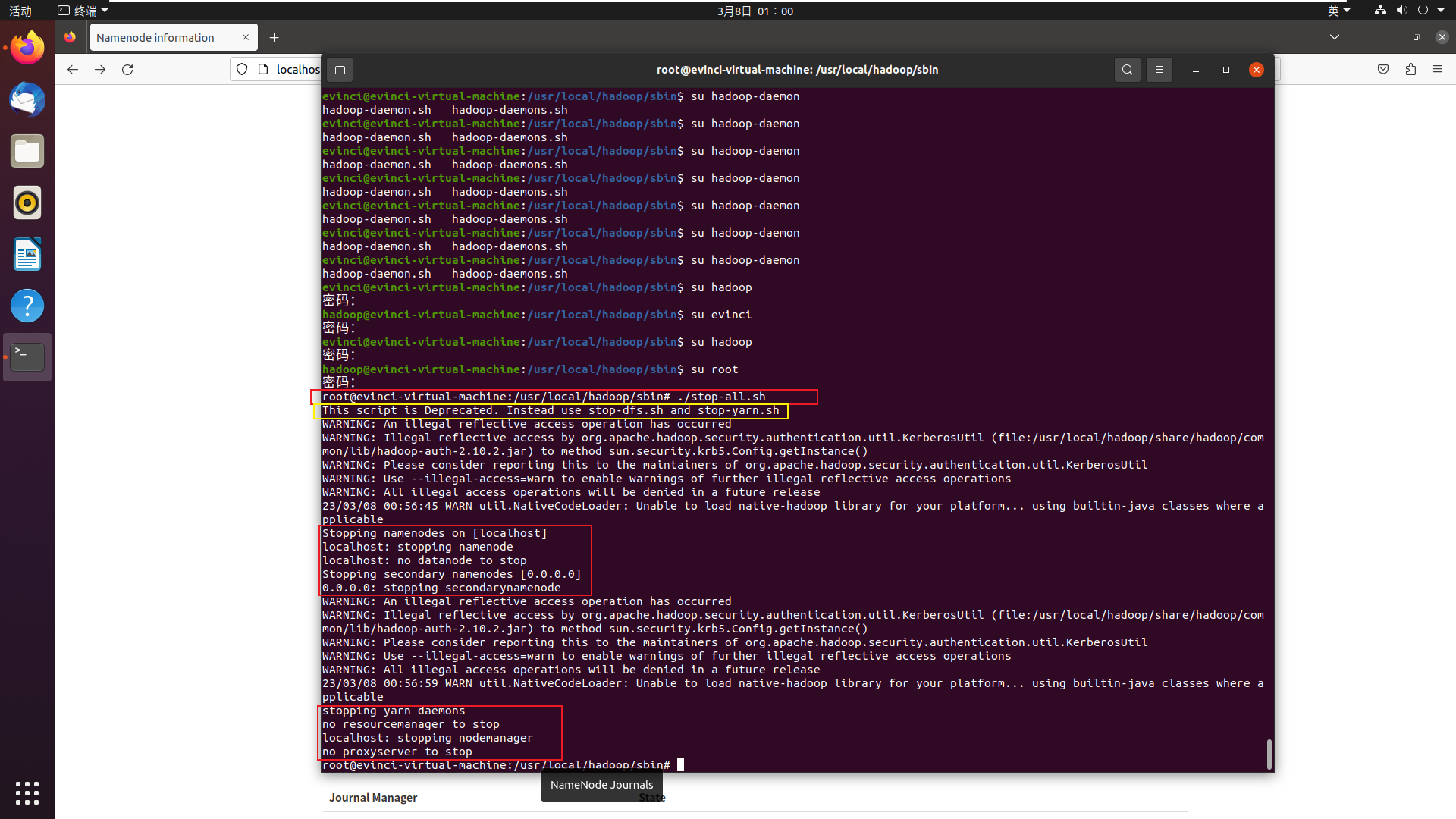
先是说
stop-all.sh已经废弃, 要使用stop-dfs.sh, 所以试一下可以看到只输出了一段连续的话, 比较简介, ok就用你了
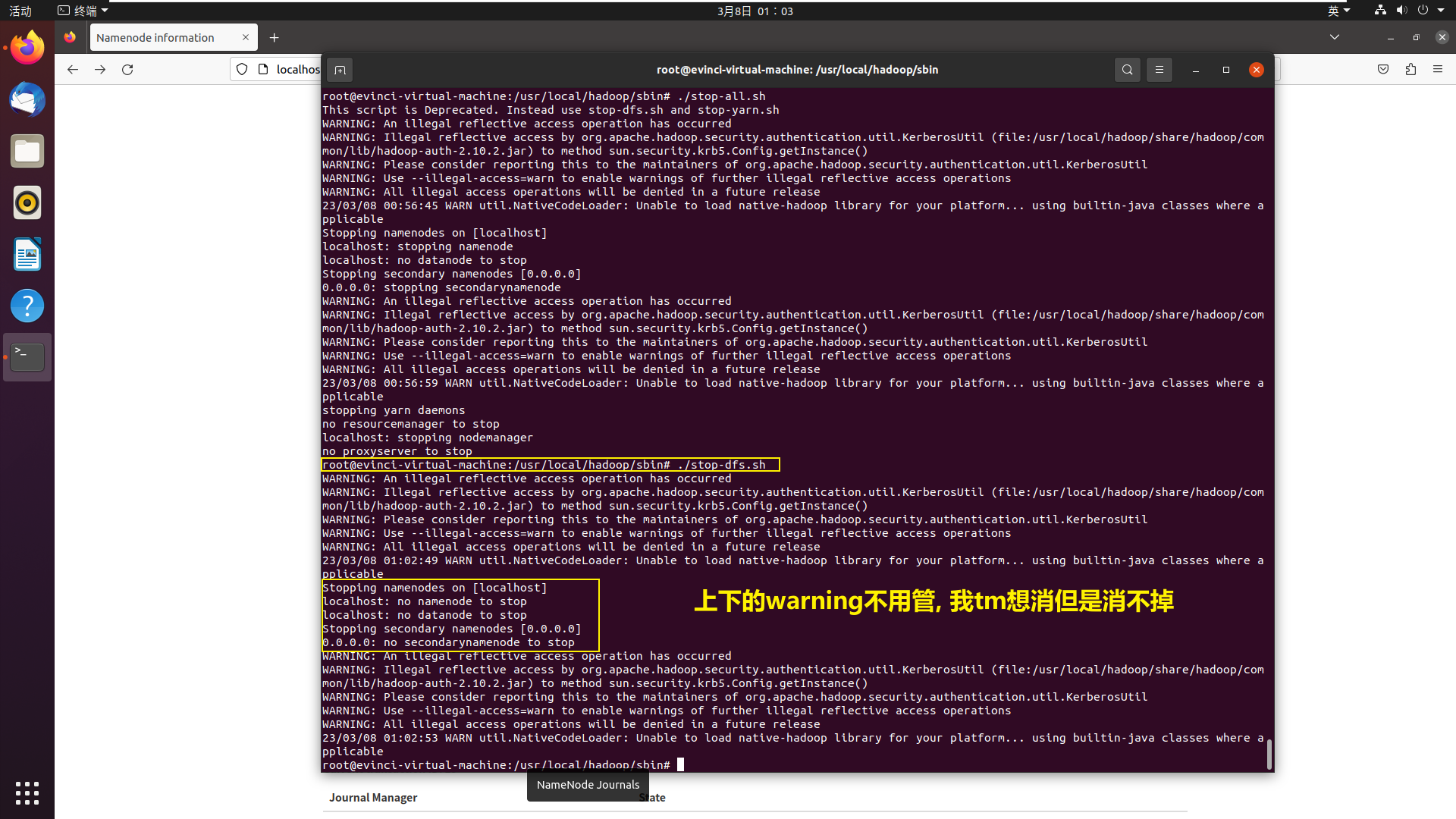
这时集群已经停止, 接下来就是删除data
-
现在的问题就是root和hadoop用户的权限问题, 待验证的就是HDFS的启动过程了
-
export环境变量配置问题-root/hadoop权限相关
VMWare启动虚拟机出现错误“该虚拟机似乎正在使用中,请按“获取所有权(T)”按钮获取它的所有权。”
I have encountered the following problems:
I use the Ubuntu system, and there are root administrator user and evinci common user. When I log in to the evinci user, the color of the command prompt is green, and when I log in to root, the color of the command prompt is white. But when I execute source /etc/profile as an ordinary user of evinci, the command prompt turns white. Why?
/etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_361/ #jdk的安装路径
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATHexport HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin