
20230319文献阅读——《OPV2V:一个用于车与车通信感知的开放基准数据集和融合管道》
- 论文标题:
OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with Vehicle-to-Vehicle Communication - 发表期刊/会议:
arXiv 2021(Accepted by ICRA2022) - 下载地址:
https://arxiv.org/abs/2109.07644v5 - OPV2V官网
https://mobility-lab.seas.ucla.edu/opv2v/ - OPV2V数据集(需要科学上网)
https://drive.google.com/drive/folders/1dkDeHlwOVbmgXcDazZvO6TFEZ6V_7WUu?usp=sharing - OpenCOOD代码框架
https://github.com/DerrickXuNu/OpenCOOD
目录
- 个人理解
- 阅读前知识准备
- 1.什么是IoU(Intersection over Union)?
- 2.什么是pipeline?
- 3.什么是backbone?
- 4.什么是baseline?
- 5.什么是AP、mAP
- 文章翻译与精读
- 一 引言
- 二 相关工作
- 三 OPV2V 数据集
- A 数据采集
- B 数据分析
- 四 注意力中间融合框架
- 五 实验
- A 基准模型(Benchmark models)
- B 指标
- C 实验细节
- D 基准分析
- E CAV数量的影响
- F 压缩率的影响
- 六 结论
个人理解
本篇文章的意义在于提出了第一个用于车对车感知的大规模开放模拟数据集,使得协同感知可以更方便的进行仿真测试,加速代码的迭代过程(因为在实际环境中测试,通信是一大痛点,且组织过程需要耗费大量的人力物力)
阅读前知识准备
1.什么是IoU(Intersection over Union)?
IoU也叫交并比,通常是指目标检测中某一帧的检测框与ground-truth的交集除以并集。
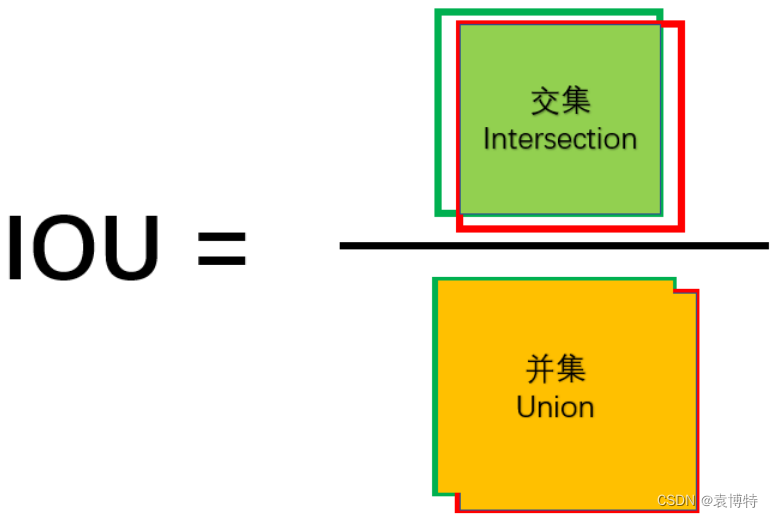
深度学习中的IoU概念理解
2.什么是pipeline?
pipeline,原意为管线,在深度学习中可以理解为流水线,或者翻译成框架。
深度学习的pipeline就是模型实现步骤的总称。深度学习现在的pipeline一般都比较强调模型的组件构成流程。
通常在深度学习中见到的pipeline主要包含以下步骤:

深度学习pipeline和baseline是什么意思?
3.什么是backbone?
backbone翻译为主干网络,通常情况下是指特征提取部分的网络。
深度学习网络中backbone是什么意思?
4.什么是baseline?
baseline意思是基线,这个概念是作为算法提升的参照物而存在的,相当于一个基础模型,可以以此为基准来比较对模型的改进是否有效。
baseline没有明确的指代,不一定必须是最原始的模型,改进后的模型也可以作为后续模型的baseline。
深度学习pipeline和baseline是什么意思?
5.什么是AP、mAP
AP,Average Precision,即 平均精确度 。
mAP,Mean Average Precision,即平均AP值 。
【深度学习中常见评价指标汇总】TP、FN、FP、TN, Precision(精确率)、Recall(召回率)、Accuracy(准确率) 和 AP(平均精确度), mAP(平均AP值)
文章翻译与精读
数据集中包含超过70个有趣的场景,11,464帧,和232,913个标注3D车辆包围框,收集自卡拉的8个城镇和洛杉矶卡尔弗城的一个数字城镇。
构建了一个全面的基准,共有16个实现模型,以评估几种信息融合策略(即早期、晚期和中期融合)与最先进的激光雷达检测算法。
提出了一种新的专注的中间融合通道来聚合来自多个互联车辆的信息。实验表明,所提出的管道可以很容易地与现有的三维激光雷达探测器集成,即使在较大的压缩率下也能实现出色的性能。
一 引言
二 相关工作
一开始是采用将单车数据集中的不同帧处的车辆视为协同感知车辆,这显然具有局限性。后来在高保真LiDAR模拟器上生成大规模V2V数据集,或在CARLA模拟器上进行测试,但这些都是不公开的。也有一些公开数据集,例如T&J数据集,但是数据量很小(只有100Mb)且只有雷达数据。
这就是本文的研究背景,也是作者写这篇文章的目的所在。
三 OPV2V 数据集
A 数据采集
模拟器选择:选择CARLA作为模拟器来收集数据集,但是CARLA本身默认不具备V2V通信和协同驾驶功能。因此,采用集成了CARLA和SUMO[25]的联合仿真工具OpenCDA[18]来生成数据集。OpenCDA具有易于控制多辆汽车、嵌入式车辆网络通信协议、更方便、更现实的交通管理等特点。
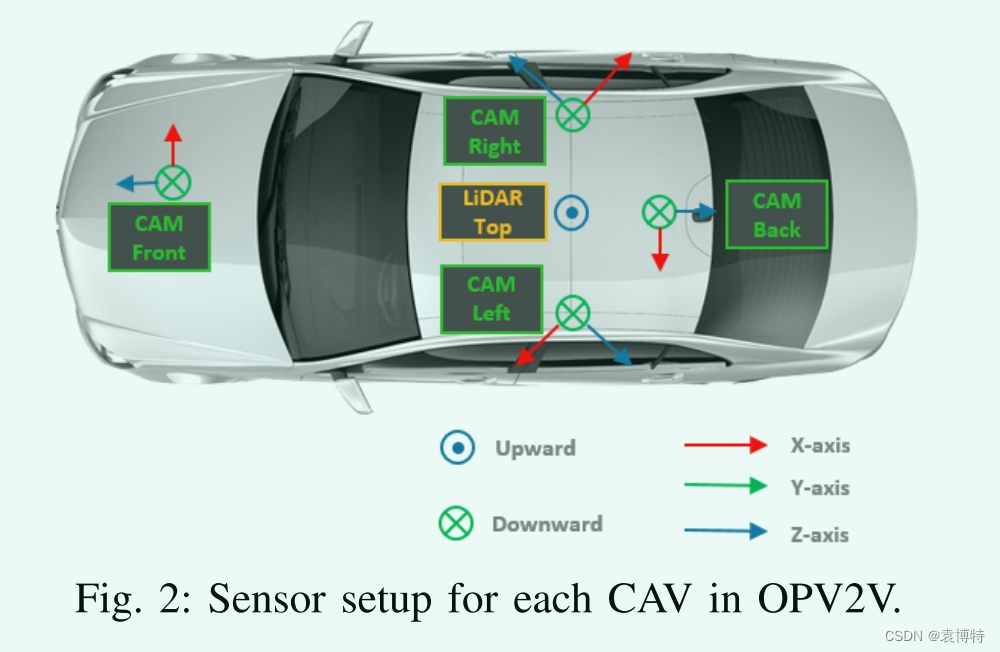
传感器配置:大部分数据来自卡拉提供的八个默认城镇。数据集中平均大约有3辆联网车辆,每帧中至少有2辆,最多有7辆。如图2所示,每辆CAV配备4个摄像头,可同时覆盖360◦视图,64通道LiDAR和GPS/IMU传感器。传感器数据以20 Hz的频率流化,以10 Hz的频率记录。表I中描述了对传感器配置的更详细描述。
卡尔弗城数字小镇:为了整合能够更好地模拟现实世界具有挑战性的驾驶环境的场景,并评估模型的领域适应能力,我们进一步收集了几个模拟现实配置的场景。在交通高峰时段,一辆配备了32线激光雷达和两个摄像头的自动车辆被送往卡尔弗城收集传感数据。然后,我们通过RoadRunner[26]填充数字城镇的道路拓扑,根据收集到的数据的一致性选择建筑,然后在OpenCDA的支持下模拟真实交通流生成汽车。我们在Culver City收集了4个场景,共约600帧(见图4)。这些场景将用于验证纯粹在CARLA中生成的模拟数据集训练的模型。计划未来从真实环境中添加数据,并可以添加到模型训练集。
数据大小:总的来说,我们收集了11,464帧(即时间步长)的LiDAR点云(见图1)和RGB图像(见图3),文件大小为249.4 GB。此外,我们还在每一帧中为每个CAV生成了Bird Eye View (BEV)图,以方便基本的BEV语义分割任务。
下游任务:默认情况下,OPV2V支持协同3D目标检测、BEV语义分割、跟踪和预测,可以使用摄像机或激光雷达。为了使用户能够扩展初始数据,我们还提供了一个驱动日志回放工具。通过使用该工具,用户可以定义自己的任务(如深度估计、传感器融合),并在不改变任何原始驾驶事件的情况下设置额外的传感器(如深度相机)。注意,在本文中,我们只报告了基于3D lidar的目标检测的基准测试结果。
B 数据分析
如表III所示,我们的数据集包含了六种不同的道路类型,用于模拟现实生活中最常见的驾驶场景。为了最小化数据冗余,我们试图避免过长的剪辑,并为每个场景分配平均长度为16.4秒的自我车辆短行程、不同的位置和不同的机动。我们还将收集到的73个不同交通配置和CAV配置的场景进行分配,以扩大数据集的方差。
通过对于车辆周围的边界框进行对比统计分析,证明了协同感知能够大幅增加感知范围,并提供遮挡补偿。
四 注意力中间融合框架
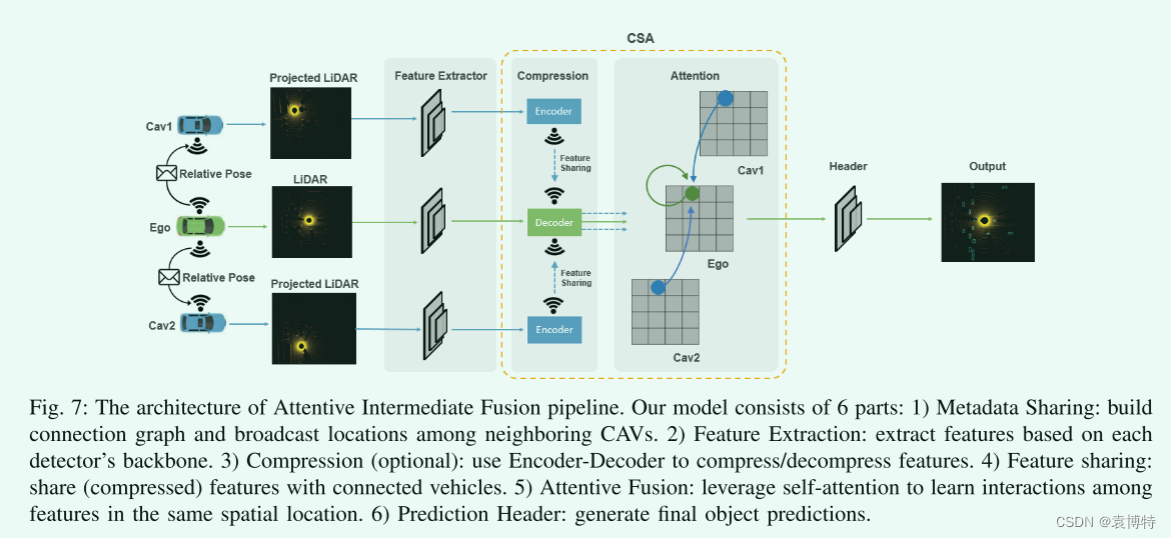
由于来自不同连接车辆的传感器观测值可能携带不同的噪声级别(例如,由于车辆之间的距离),为了协同感知具有更加鲁棒的性能,提出一种能够关注重要观测值而忽略中断观测值的方法,取名为注意力中间融合框架。包括6个模块:元数据共享、特征提取、压缩、特征共享、专注融合和预测。该框架可以很容易地与现有的基于深度学习的激光雷达探测器集成。
元数据共享和特征提取:首先广播每个CAV的相对姿态和外部特征,构建空间图,其中每个节点是通信范围内的一个CAV,每条边代表一对节点之间的通信通道。在构建完空间图后,将在群体中选择一个自我车。邻近的所有CAVs都将自己的点云投影到自我车的LiDAR框架上,并根据投影的点云提取特征。这里的特征提取器可以是现有3D对象探测器的主干网络。
压缩和特性共享:V2V通信的一个基本因素是硬件对传输带宽的限制。原始高维特征图的传输通常需要较大的带宽,因此需要压缩。与共享原始点云相比,中间融合的一个关键优势是压缩[15]后的边缘精度损失。这里我们部署了一个Encoder-Decoder体系结构来压缩共享消息。编码器由一系列2D卷积层和最大池化层组成,bottleneck中的feature map会广播给自我车。在自我车中包含多个解卷积层[27]的解码器将恢复压缩后的信息,并将其发送给注意力融合模块。
注意融合:解压缩后的特征采用[28]自注意模型进行融合。同一特征图内的每个特征向量(图7中绿/蓝圈)对应原始点云中的某个空间区域。因此,简单地扁平化特征地图和计算特征的加权和将打破空间相关性。相反,我们为特征图中的每个特征向量构建一个局部图,其中,对于来自不同连接车辆的相同空间位置的特征向量构建边缘。一个这样的局部图如图7所示,自我注意会对图进行操作来推理交互,以便更好地捕捉代表性特征。
预测报头:融合的特征将被反馈到预测报头,以生成边界框proposals和相关的置信度评分。
五 实验
A 基准模型(Benchmark models)
在数据集上实现了四种基于激光雷达的最先进的3D目标检测器,并将这些检测器与三种不同的融合策略进行集成,即早期融合、晚期融合和中期融合。还研究了单车环境下的模型性能,称为无融合,忽略了V2V通信。因此,共有16个模型将在基准中进行评估。所有的模型都是在一个统一的代码框架中实现的,代码和开发教程可以在项目网站上找到。
选定的3D目标检测器:我们选择SECOND [29], VoxelNet [4], PIXOR[30]和PointPillar[5]作为我们的3D LiDAR目标探测器进行基准分析。
早期融合基线(baseline):根据车辆共享的位置信息,将所有激光雷达点云投影到自我车的坐标系中,然后自我车将所有接收到的点云进行聚合,并将其反馈给检测器。
晚期融合基线:每个CAV将独立进行目标检测,输出带有置信度的边界框,并将这些输出广播给自我车。非最大抑制(Non-maximum suppression, NMS)将随后应用于这些proposals中,从而生成最终的目标检测结果。
中间融合:带有注意力融合的pipeline是灵活的,可以很容易地推广到其他目标检测网络。为了评估本文提出的pipeline,我们只需要将压缩、共享和关注(CSA)模块添加到现有的网络体系结构中。由于4个不同的探测器以相似的方式添加CSA模块,这里我们只展示了中间融合与PIXOR模型的架构,如图8所示。在PIXOR的2D主干上增加了三个CSA模块,以聚合多尺度的特征,而网络的其他部分保持不变。

B 指标
对于测试和验证集中的每个场景,我们在所有生成的CAVs中选择一辆固定车辆作为自我车。在x∈[−140,140]m, y∈[−40,40]m的范围内,在自我车附近评估检测性能。在[15]之后,我们将CAVs之间的广播范围设置为70米。感知到这个沟通范围之外的信息将被自我车忽略。对不同的模型分别采用0.5和0.7的IoU (Intersection-over-Union)阈值的平均精度(AP)进行评估。由于PIXOR忽略了边界框的z坐标,我们只在x-y平面上计算IoU,以保证比较的公平性。对于评估目标,我们包括被任何互联车辆至少一个激光雷达点击中的车辆。
C 实验细节
训练/验证/测试分片是6764/1981/2719帧。测试框架包含所有道路类型,并进一步分为两部分- carla默认地图和卡尔弗城数字城镇。对于每一帧,我们保证CAVs的最小和最大值分别为2和7。我们使用Adam Optizer[31]和early stop来训练所有的模型,我们花了14天在4个RTX 3090 gpu上完成所有的训练。
D 基准分析
通过试验验证了,融合方法优于非融合方法,其中,早期融合方法优于晚期融合方法,带有注意力融合的中期融合方法优于早期融合方法。
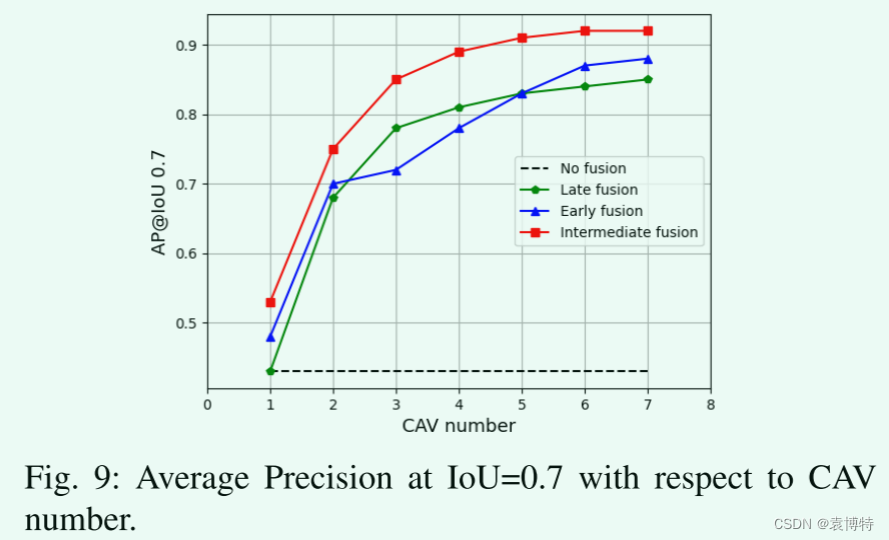
E CAV数量的影响
研究了在复杂的交叉场景中,在周边地区产生150辆车的情况下,CAVs数量对检测性能的影响。其中一部分将转化为可以共享信息的CAVs。我们逐渐将CAVs的数量增加到7个,并采用不同融合方法的VoxelNet进行目标检测。如图9所示,平均精度与CAVs数量呈正相关。但是,当数量达到4时,增长速度变慢。这可能是因为CAVs分布在交叉口的不同侧面,其中4个已经能够提供足够的视点来覆盖大部分盲点。5辆或更多车的额外增强来自于对同一物体更密集的测量。
F 压缩率的影响
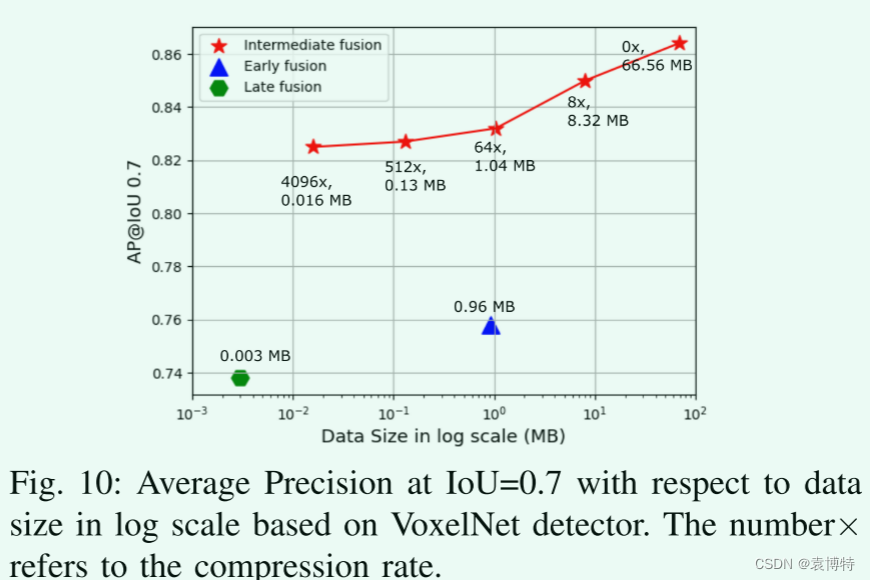
图10展示了在CARLA城镇的测试集中,所有融合方法在一对车辆和相应平均精度之间单次传输所需的数据量。我们在这里为所有的融合方法选择VoxelNet,并通过修改编码器-解码器的层数来模拟不同的压缩率。通过应用一个简单的编码器-解码器架构来压缩数据,带有注意力融合的中期融合方法在精度和带宽之间获得了一个杰出的平衡。即使在4096倍的压缩率下,性能虽略微下降(约3%),但仍然超过早期和晚期融合。基于V2V通信协议[32],300 m范围的数据广播可以达到27mbps。这表示以4096倍压缩率传递消息的时间延迟仅为5 ms左右。
六 结论
在本文中,我们提出了第一个用于V2V感知的公开数据集和基准融合策略。并且进一步提出了带有注意力融合的中期融合方法,实验结果表明,该方法在大压缩比下也能达到最优性能。
未来,我们计划将数据集扩展为更多任务和传感器套件,并在V2V和V2I (vehicle -to - infrastructure, V2I)设置中研究更多多模态传感器融合方法。我们希望我们的开源努力能够为V2V概念的标准化进程迈出一步,并鼓励更多的研究人员去研究这个新的方向。
上一篇:第一周web