
Mysql之函数
一、函数
字符串函数
数学函数
日期函数
日期-字符串转换函数
流程函数
1.1 字符串函数
函数 | 解释 |
CHARSET(str) | 返回字串字符集 |
CONCAT (string2 [,... ]) | 连接字串 |
INSTR (string ,substring ) | 返回substring在string中出现的位置,没有返回0 |
UCASE (string2 ) | 转换成大写 |
LCASE (string2 ) | 转换成小写 |
LEFT (string2 ,length ) | 从string2中的左边起取length个字符 |
LENGTH (string ) | string长度 |
REPLACE (str ,search_str ,replace_str ) | 在str中用replace_str替换search_str |
STRCMP (string1 ,string2 ) | 逐字符比较两字串大小, |
SUBSTRING (str , position [,length ]) | 从str的position开始,取length个字符 |
LTRIM (string2 ) RTRIM (string2 ) trim | 去除前端空格或后端空格 |
-- =========== 字符串函数 =========
-- ============编码=============
select charset('abc') from stu limit 1;
-- 为了演示效果,可以不使用表
select charset('abc');
-- 为了好看,提供了一个哑表 dual
select charset('abc') from dual;-- 查询学生表姓名字段的编码格式
select sname,charset(sname) from stu;-- =============拼接================
-- concat 字符串拼接 (标准的只能写两个参数,mysql扩展了)
select concat('a','b','c');
-- 将学生信息 以自我介绍拼接出来
-- 我叫张三,今年18岁
select concat('我叫',sname,',今年',age,"岁") 自我介绍 from stu;
-- 模糊查询 like '%keyword%'
select * from stu where sname like concat('%','keyword','%');-- instr
select instr('java','av');
select if(instr('java','big')>0,'存在','不存在');
-- 查询学生姓名,含有三的
select sname,
if(instr(sname,'三')>0,'是','否')
from stu;-- left-- 转大小写
select ucase('aaa'),lcase('ABC');
-- left
select left('java',2);
-- right
select right('java',2);
-- 取名字第一个字
select left(sname,1) from stu;-- length()
select length('a'); -- 英文占1个字符
select length('我'); -- 中文占3个字符(不同编码占位不同)
select length(sname) from stu;-- 替换 replace
-- REPLACE (str ,search_str ,replace_str ) 在 str 中
-- 用 replace_str 替换 search_str
select replace('j9ava','9',''); -- 把9 换为 空
select replace('java','av','AV');
-- strcmp
select strcmp('a','b');
select strcmp('d','c');
select strcmp('text','c');-- substring
select substring('abcdefg',2);
select substring('abcdefg',2,4);-- ltrim rtrim
select ltrim(' aaa ');
select rtrim(' aaa ');1.2 数学函数
函数 | 解释 |
ABS (number2 ) | 绝对值 |
BIN (decimal_number ) | 进制转二进制 |
CEILING (number2 ) | 向上取整 |
CONV(number2,from_base,to_base) | 进制转换 |
FLOOR (number2 ) | 向下取整 |
FORMAT (number,decimal_places ) | 保留小数位数 |
HEX (DecimalNumber ) | 转十六进制 |
LEAST (number , number2 [,..]) | 求最小值 |
MOD (numerator ,denominator ) | 求余 |
RAND([seed]) | RAND([seed]),seed是种子,可不写.写了随机数固定 |
ROUND(x,[d]) | 将x四舍五入,d是保留的位数,可不写 |
TRUNCATE(X, D) | 截取 |
-- =========== 数学函数 ============
-- 绝对值
select abs(-1);
select abs(1);
-- 向上取整,向下取整
select ceiling(10.1),floor(10.1);
-- format 保留指定位数小数(会四舍五入)
select format(1.126456,2);
-- 随机数,0-1之间
select rand();
insert into stu (sid) values (rand() * 1000)
-- 小数四舍五入,可以指定小数点保留的位数
select round(5.12645,2);
-- truncate() 截取数据,后面指定保留的小数点位数(不四舍五入)
select truncate(5.12645,2);1.3 日期函数【重要】
函数 | 解释 |
SYSDATE() | 当前时间 |
ADDTIME (date2 ,time_interval ) | 将time_interval加到date2 |
CURRENT_DATE ( ) | 当前日期 |
CURRENT_TIME ( ) | 当前时间 |
CURRENT_TIMESTAMP ( ) | 当前时间戳 |
DATE (datetime ) | 返回datetime的日期部分 |
DATE_ADD (date2 , INTERVAL d_value d_type ) | 在date2中加上日期或时间 |
DATE_SUB (date2 , INTERVAL d_value d_type ) | 在date2上减去一个时间 |
DATEDIFF (date1 ,date2 ) | 两个日期差 |
NOW ( ) | 当前时间 |
YEAR|MONTH|DATE (datetime ) | 年月日 |
-- =================日期函数================
-- 获得当前时间
select sysdate();
select current_date();
select current_time();
select current_timestamp();
select now();-- 日期加减
-- 加日期(时分秒)
select addtime(now(),'03:00:00');
select addtime(now(),'30:00:00');
-- 加日期,加天数
select adddate(now(),10);
-- 加日期,加指定单位(year|month|day)的指定日期 (interval 必须加上)
select date_add(now(),interval 1 month);
select date_add(now(),interval 1 year);
select date_add(now(),interval -1 year);-- 减去日期
select date_sub(now(),interval 1 day);
-- 得到相差天数 前减去后
select datediff(now(),'2022-03-17');
select datediff('2022-03-17',now()); -- 获得当前的年或月或日
select year(now());
select year('1980-01-01');
select month('1980-01-01');
select day('1980-01-01');-- 获得5月生日的人数
select * from stu1 where month(sbirthday) = 5;
-- 获得当月生日的人数
select * from stu1 where month(sbirthday) = month(now());
-- 获得当天生日
select date_format(now(),'%m-%d');
select * from stu1
where date_format(now(),'%m-%d') = date_format(sbirthday,'%m-%d');1.4 日期字符串转换函数【重要】
函数 | 解释 |
date_format(日期,模板) | 日期 --> 字符串 |
str_to_date(字符串,模板) | 字符串 --> 日期 |
%Y:代表4位的年份 %y:代表2为的年份 %m:代表月, 格式为(01……12) %c:代表月, 格式为(1……12) %d:代表月份中的天数,格式为(00……31) %e:代表月份中的天数, 格式为(0……31) %H:代表小时,格式为(00……23) %k:代表 小时,格式为(0……23) %h: 代表小时,格式为(01……12) %I: 代表小时,格式为(01……12) %l :代表小时,格式为(1……12) %i: 代表分钟, 格式为(00……59) %r:代表 时间,格式为12 小时(hh:mm:ss [AP]M) %T:代表 时间,格式为24 小时(hh:mm:ss) %S:代表 秒,格式为(00……59) %s:代表 秒,格式为(00……59) |
-- =========== 日期/字符串转换函数 ============
/*日期 --> 字符串 date_format(date,'%Y-%m-%d')字符串 --> 日期 str_to_date('datestr','%Y-%m-%d') ---------------------日期模板%Y年 %m月 %d日%H时 %i分钟 %S秒
*/
insert into t10 (id,birthday) value (1,str_to_date('2020-01-01','%Y-%m-%d'))
-- ==================日期转换=====================
-- 日期格式化(日期-->字符串)
select date_format(now(),'%Y-%m-%d');
select date_format(now(),'%Y年%m月%d日');-- 日期解析(字符串-->日期)
select str_to_date('1980-01-02','%Y-%m-%d');
select str_to_date('2022年11月18日','%Y年%m月%d日')-- 插入
insert into stu1 (sid,sbirthday)
values (29,str_to_date('1980/01/02','%Y/%m/%d'));
1.5 流程函数【重要!!】
函数 | 解释 |
IF(expr1,expr2,expr3) | 如果expr1为真,则返回expr2,否则返回expr3 |
IFNULL(expr1,expr2) | 如果 expr1不是NULL,则返回expr1,否则返回expr2; 一般用来替换NULL值,因为NULL值是不能参加运算的 |
CASE WHEN [expr1] THEN [result1]… ELSE [default] END | 如果expr是真, 返回result1,否则返回default |
CASE [value] WHEN [value1] THEN[result1]… ELSE[default] END | 如果value等于value1, 返回result1,否则返回default |
-- 范围判断
-- CASE WHEN [expr1] THEN [result1]… ELSE [default] END
-- 如果expr是真, 返回result1,否则返回default-- ================流程函数=============
-- if 函数
select if(1>0,'true','false') from dual;-- 获得所有人的平均分
select sum(score)/count(sid) from stu;
select avg(if(score is null,0,score)) from stu;
-- 查询学生学号,成绩,以及是否及格(>=60)
select sid,score,if(score >= 60,'及格','不及格') 是否及格 from stu;
-- 查询学生学号,成绩,没有成绩则为缺考
select sid,score,if(score is null,'缺考',score) 分数 from stu;-- 计算年龄大于50的人数
select count(sid) from stu where age > 50;
select count(if(age < 50,null,sid)) from stu;-- ifnull 函数
-- 查询学生学号,成绩,没有成绩则为缺考
select sid,score,ifnull(score,'缺考') from stu;select case 1
when 1 then '一'
when 2 then '二'
when 3 then '三'
else -1
end as 结果;select sid,sname,age, case
when age < 15 then '少年'
when age < 18 then '青年'
when age < 60 then '成年'
else '老年'
end 结果
from stu;-- 查询学生学号,姓名,成绩,等级(60以下不合格,60-80良好,80以上优秀)
select sid,sname,score,case
when score < 60 then '不合格'
when score >= 60 and score <= 80 then '良好'
when score > 80 then '优秀'
else '缺考'
end '等级'
from stu;二、事务 (transaction tx)
2.1什么是事务?
事务是一个原子操作。是一个最小执行单元。可以由一个或多个SQL语句组成,在同一个事务当中,所有的SQL语句都成功执行时,整个事务成功,有一个SQL语句执行失败,整个事务都执行失败。
有错则错。
2.2 mysql中事务
目前使用的mysql支持事务操作
mysql默认是自动提交事务的,每个sql语句都是单独事务
通过命令查询当前事务的提交方式 SHOW VARIABLES like 'autocommit'
通过命令设置自动提交关闭 set autocommit = off / 或者= 0 关
set autocommit = on / 或者= 1 开
事务的操作
开启事务 start transaction 或者 begin
提交事务 commit
回滚事务 rollback
2.3 演示事务
CREATE TABLE `account` (`id` int(50) NOT NULL,`name` varchar(50) NOT NULL,`money` int(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO account VALUES(1,'张三',1000);
INSERT INTO account VALUES(2,'李四',1000);-- 开启事务
start transaction;
-- 开始转账
update account set money = money - 100 where id = 1
-- 出大事了,后面执行不了
update account set money = money + 100 where id = 2
-- 如果一切正常,提交事务
commit;
-- 服务器出现异常,要回滚
rollback;-- 查询当前事务提交方式
SHOW VARIABLES like 'autocommit';
-- 手动控制事务,自动提交关闭
set autocommit = off;-- ============= java 伪代码 ==================
try{conn.setAutocommit(false); -- 自动提交,开启手动事务conn.execute("update ....")System.out.print(1/0)conn.execute("update ....")conn.commit(); -- 提交
}catch(Exception e) { -- 如果有异常conn.rollback(); -- 回滚
}-- 框架里,只需要配置一下就ok2.4 事务特性
事务的特性(ACID)
原子性(Atomicity):指事务的整个操作是一个整体,要么都成功,要么都失败
一致性(Consistency):事务必须使数据库从一个一致性状态变换到另外一个一致 性状态。转账前和转账后的总金额不变。
隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一 个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
讲解:一个事务 A 开始事务,修改 a 表数据,自己查询数据,已经修改,并提交
另外开启一个事务 B:操作同一个表-> 修改 a 表其他列数据,自己查看已经修改
但是在事务提交前, A事务再查表数据,并未看见 B事务做出的修改.同样 B 事务也看不见 A 事务做出的修改.
持久性(Durability):指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
2.5 事务的隔离机制
数据库有不同的隔离机制/隔离级别(从低到高)
读未提交-READ UNCOMMITTED: 赃读、不可重复读、虚读都有可能发生。
读已提交-READ COMMITTED: 避免赃读。不可重复读、虚读都有可能发生。
(oracle 默认的)
可重复读-REPEATABLE READ:避免赃读、不可重复读。虚读有可能发生。
(mysql 默认)行锁
串行化-SERIALIZABLE: 避免赃读、不可重复读、虚读。
串行化,其实是表锁
查看当前数据库的隔离级别: SELECT @@TX_ISOLATION;
更改当前的事务隔离级别:
SET [glogbal | session] TRANSACTION ISOLATION LEVEL 四个级别之一
赃读:
指一个事务读取了另一个事务未提交的数据。
对于两个事物 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的.
不可重复读:
在一个事务内读取表中的某一行数据,多次读取结果不同。一个事务读取到了另一个事务提交后的数据。(update)
对于两个事物 T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
虚读(幻读):
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。 (insert)
对于两个事物 T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中 插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行.
三、 索引
索引是一种数据结构,可以更方便查询数据.
3.1索引的分类
主键索引:在数据表的主键字段创建的索引,这个字段必须被 primary key 修饰, 每张表只能有一个主键
唯一索引:在数据表中的唯一列创建的索引(unique),此列的所有值只能出现一次, 可以为 NULL
普通索引:在普通字段上创建的索引,没有唯一性的限制
复合索引:两个及以上字段联合起来创建的索引
全文索引
3.2索引的使用
创建
create index 索引名 on 表名(列);
ps: 如果表中已经有大量数据,再创建索引,也很耗时
命中索引, select 语句中 where条件得使用索引列
删除 drop index 索引名 on 表名;
3.3索引优缺点
优点: 根据索引查数据很快
缺点: 索引建立,删除,更新很慢. 如果对索引列经常增删改,也会效率很慢
索引本身也是一种数据结构,也会占磁盘空间
四、存储引擎
存储引擎是数据库存储数据的一种格式.
引擎分类
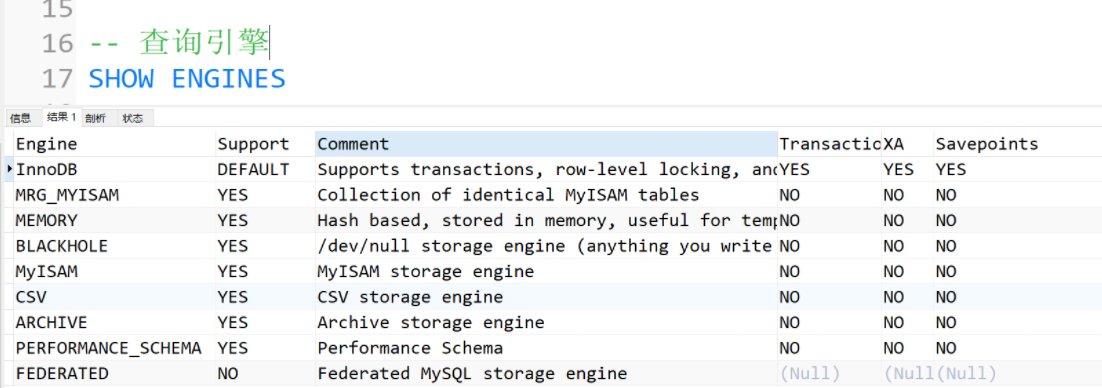
MyISAM 和 InnoDB 的区别有哪些:
InnoDB 支持事务,MyISAM 不支持
InnoDB 支持外键,而 MyISAM 不支持
InnoDB 行锁,而 MyISAM 表锁
InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高;MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是独立的。
Innodb 不支持全文索引,而 MyISAM 支持全文索引,查询效率上 MyISAM 要高;
InnoDB 不保存表的具体行数,MyISAM 用一个变量保存了整个表的行数。
MyISAM 采用表级锁(table-level locking);InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
五、数据库设计三范式
第一范式:
要求数据表中的字段(列)不可再分(原子性)
错误示例:

第二范式:
不存在非关键字段对关键字段(主键)的部分依赖
ps: 主要是针对联合主键,非主键不能只依赖联合主键的一部分
联合主键,即多个列组成的主键
第三范式:
不存在非关键字段之间的传递依赖