
基于 Apache Flink 的实时计算数据流业务引擎在京东零售的实践和落地
摘要:本文整理自京东零售-技术研发与数据中心张颖&闫莉刚在 ApacheCon Asia 2022 的分享。内容主要包括五个方面:
- 京东零售实时计算的现状
- 实时计算框架
- 场景优化:TopN
- 场景优化:动线分析
- 场景优化:FLINK 一站式机器学习
点击查看更多技术内容
一、京东零售实时计算的现状
1.1 现状
- 技术门槛高、学习成本大、开发周期长。行业内实时开发能力只有少数人能够掌握的现状;
- 数据开发迭代效率比较低,重复逻辑反复的开发缺少复用;
- 测试运维难,复杂业务逻辑难以局部测试。
1.2 动力
- 降本增效、节省人力,助力高效开发;
- 多角色数据开发,不同角色对应不同的开发方式,非数据人员也能做数据开发的工作。
1.3 目标
- 降低数据开发门槛,通过标准化积木式的开发,实现低代码配置化数据加工,进一步实现图形化清晰表达数据流转;
- 通过算子库组件的沉淀,提升开发效率,提高复用性,一站式加工;
- 通过单元测试以及沉淀用例,提高开发质量。
二、实时计算框架
2.1 为什么做数据流框架
- 数据流框架:9N-Tamias/9N-Combustor,数据流框架基于计算引擎之上,提供一种易用高效的数据开发方式,包括:tamias,是基于 Flink 的引擎的开发框架;combustor:基于 Spark 引擎的开发框架。基于 9N-Tamias 和 9N-Combustor 提供数据流开发工具;
- 支持实时离线统一的表达;
- 多种使用方式:图形化、配置化、SDK 等;
- 算子、组件复用:数据流算子、转换算子、自定义算子、目标源算子,灵活的组合,沉淀常用的算子组合,组件化包括数据流组件和自定义组件,通过数据流开发沉淀数据流组件,同时也开放自主开发自定义组件方式,通过算子、组件的复用,提高开发效率。
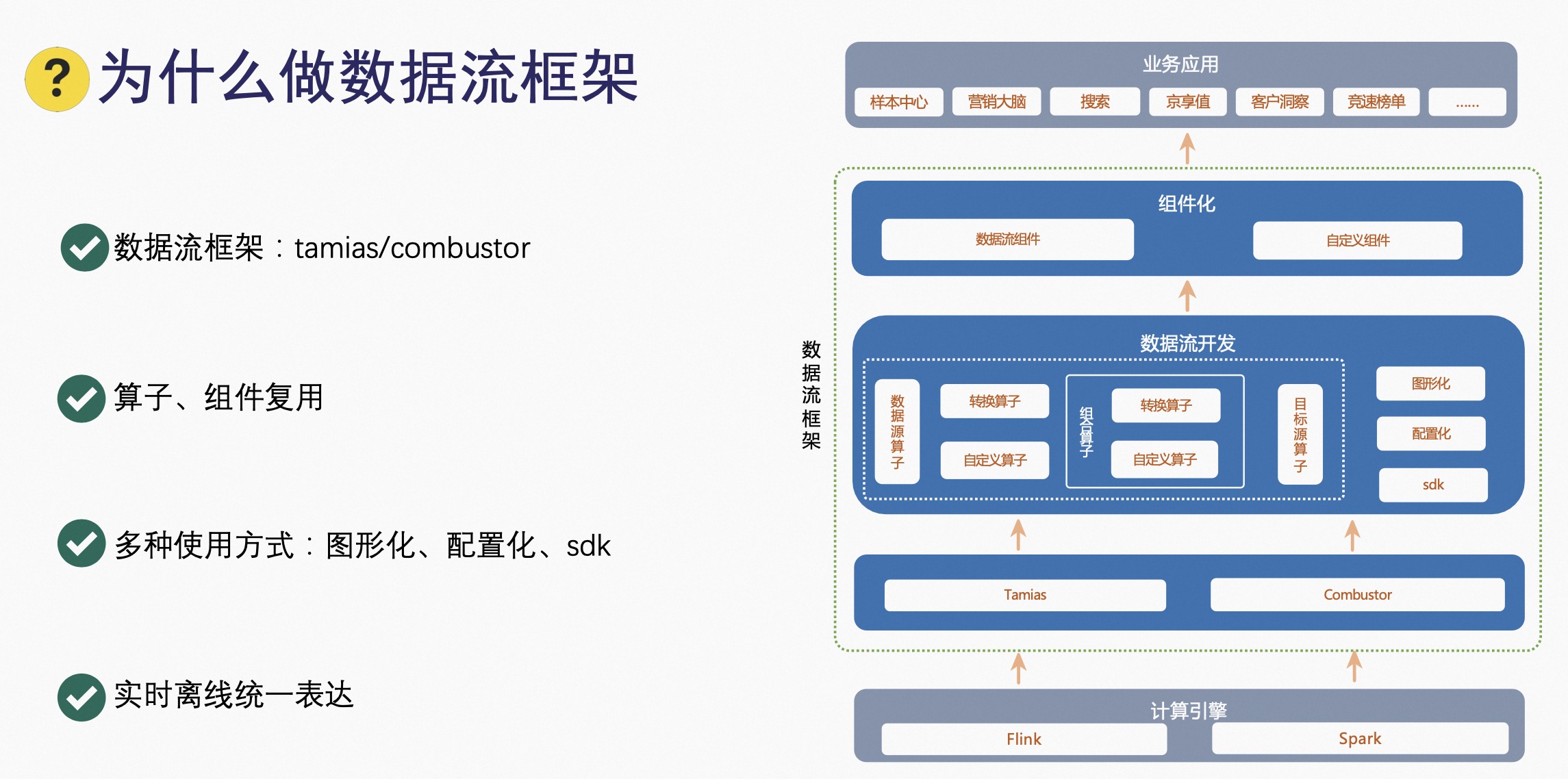
数据流框架上层各业务场景基于数据流组件化,实现业务数据的加工,包括样本中心、京享值、搜索等一些业务。
2.2 怎么做实时计算框架?
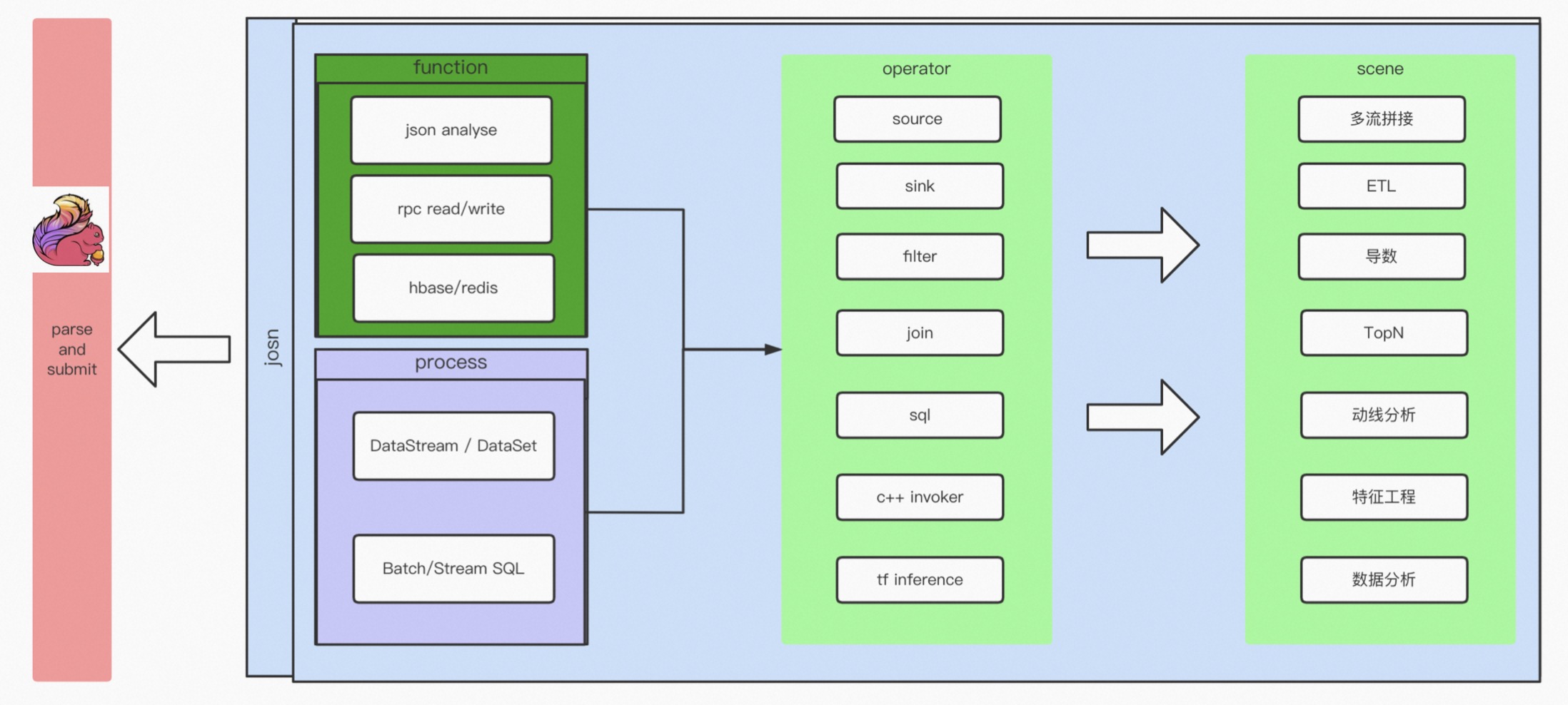
实时计算框架分成四层:
- Function 层:实现比如 Json 解析、RPC 调用、以及数据流的链接;
- Process 层:对 Flink 引擎、Data Stream、Data Set、SQL 等 API 进行封装;
- Function 和 Process 组合生成 Operator,对具体的处理逻辑进行封装,比如实现 Source、Sink、Filter、Join 等常用的算子;
- 一个或者多个 Operator 构成不同的场景,比如多流拼接导数的 Top N、动线分析,这些构成了 JSON 的配置文件,然后再通过通用的引擎解析配置文件提交任务。
2.3 实时框架:公用 Ops 和 Function
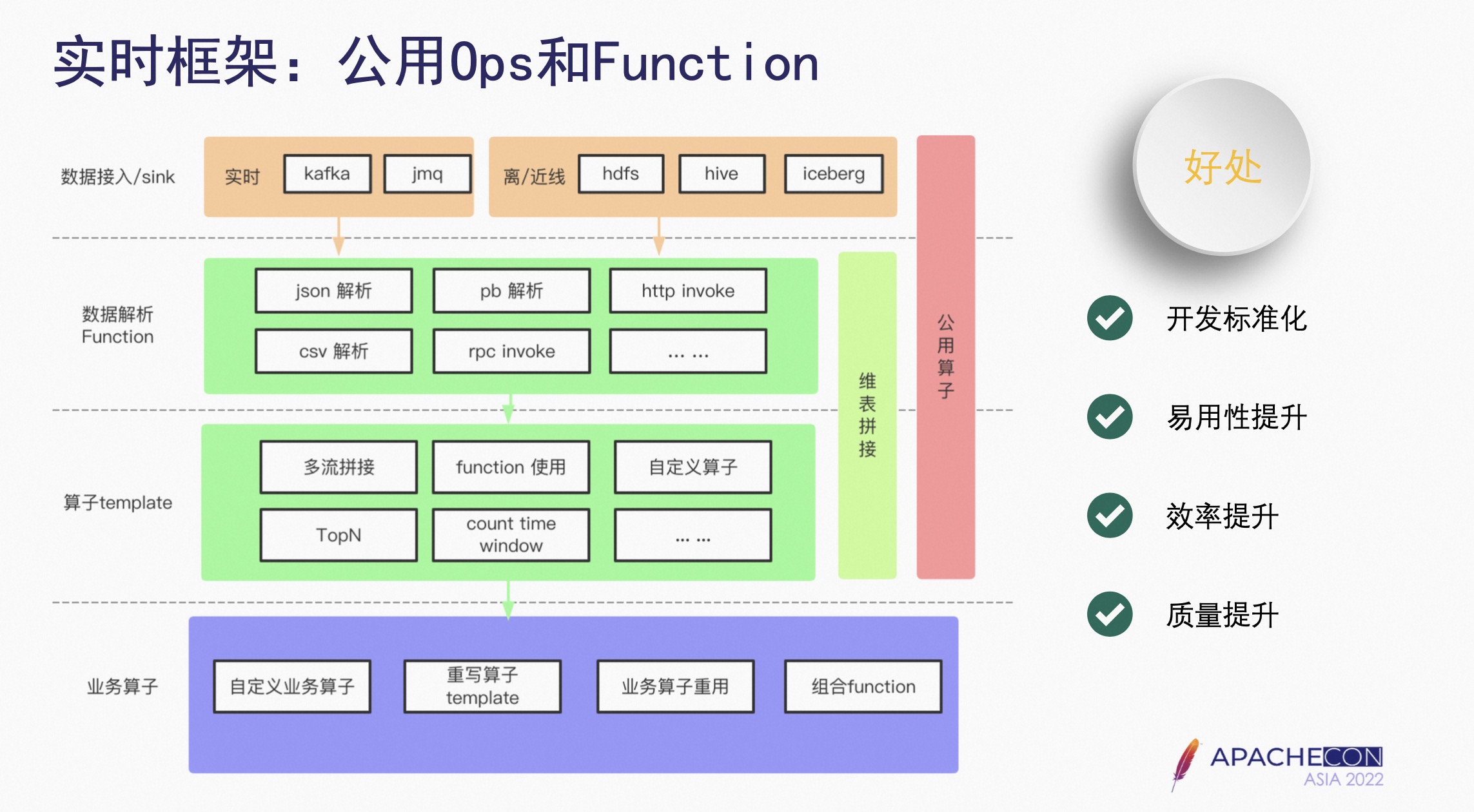
数据接入 Source 和 Sink 层:实现了实时离线、近线常用的数据源;
数据解析 Function:是为了将公用的计算逻辑进一步细化,在算子里封装多个 Function,进行灵活实现业务的逻辑;
算子 Template:如多流拼接、TopN、Count Time Window,业务自己实现会比较复杂,因此框架提供了这些算子的 Template,业务只需要在 Template 的基础上增加业务代码即可,不需要再对这些通用的算子进行学习、开发、调试等工作;
业务算子:可以基于 Template 已有的业务算子,重写得到新的业务算子,也可以自定义组合 Function,形成业务算子。
优点如下:
- 开发标准化:基于框架提供的公用算子,组合完成业务标准化的开发;
- 易用性提升:框架提供一些常用且难以实现的算子,使业务的开发变得简单;
- 开发迭代效率提升:业务只需要关注业务逻辑,从而提高开发迭代效率质量的提升;
- 质量提升:框架提供的公共算子都是经过严格的测试,并经过长期的业务验证,从而提高开发质量。
三、场景优化:TopN
3.1 复用算子
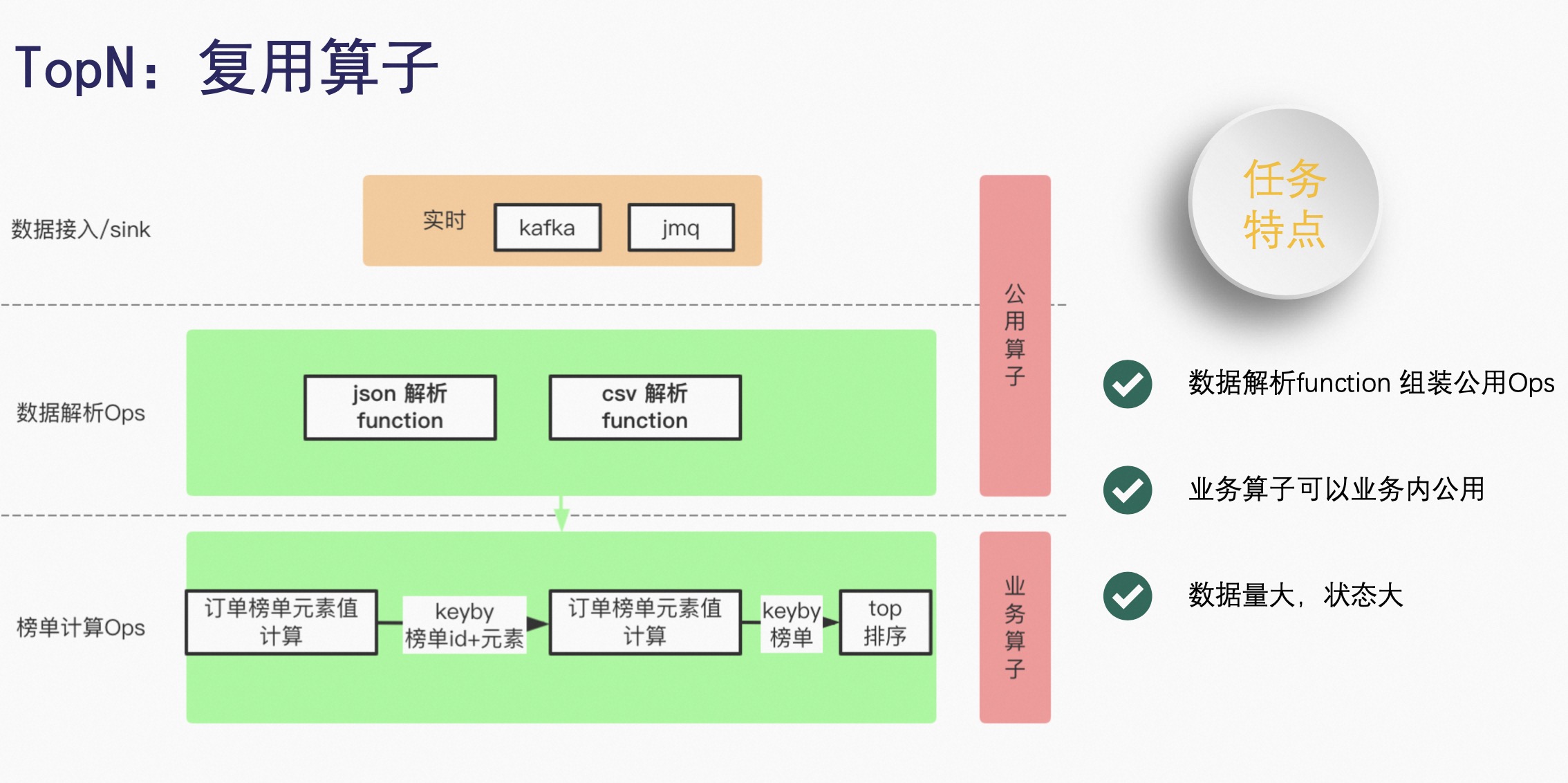
首先不仅仅是 TopN,包括所有业务场景,数据接入和数据写出都是可以共用的,比如针对流计算,像 Kafka 或 JMQ 的接入和写出,都是可以复用的。
然后是数据解析的算子,包括 JSON 解析、CSV 解析都是可以复用的,但是如果每一个 JSON 解析和 CSV 解析都抽象成一个 Operator,会需要很多的 Operator,因此抽象了 Function 概念,然后 Function 可以组合成公用的算子。
【案例】以榜单计算为例,首先用订单榜单的一个元素值作为一个计算,然后 KeyBy 时用榜单 ID 加元素,接下来再进行一次订单榜单元素值的计算,把榜单 ID 和元素值进行一次 KeyBy,产生的 TopN 的排序。
在这里需要 KeyBy 两次,因为在京东的固有的场景下,有业务上的数据倾斜,只能采用多次聚合,或者是多次排序的方式来解决问题。
3.2 任务优化
HDFS 小文件的问题:因为数据量非常大,因此在写 HDFS 时,如果 Rolling 策略设置不合理,会导致 HDFS 产生很多的小文件,可能会把 HDFS Name Node 的 RPC 请求队列打满。通过源码及其任务机制发现,HDFS 的文件 Rolling 的策略与 Checkpoint 的时间以及 Sink 的并行度相关,因此合理设置 Checkpoint 的时间和 Sink 的并行度,可以有效解决 Sink HDFS 的小文件的问题。
RocksDB 优化:通过查看官方文档可以发现,针对 RocksDB 相关的优化有很多,但是如何有效优化 RocksDB 的设置,核心就在于合理地设置 BlockCache 和 WriteBuffer 的大小,还可以添加 BloomFilter,相应调整这些参数,具体采用哪些配置都可以。
Checkpoint 优化:主要是超时时间、间隔时间、最小停顿时间。比如超时时间是半个小时,这个任务产生了 Fail 了,假如它是在 29 分钟的时候,进行 Failover 的时候,需要从上个 Checkpoint 开始恢复,需要很快消费前 29 分钟的数据。这种情况下如果数据量非常大,对任务是一个不小的冲击。但是如果把 Checkpoint 的时间设置为更合适的 5 分钟或者 10 分钟,这个冲击量会少很多。
数据倾斜:造成数据的倾斜的情况有很多种,比较难解决的是数据源中引发的数据倾斜问题,因此可以采用多次聚合或者多次排序模式解决;另外一个是机器问题,是由于某台机器问题造成的数据倾斜,通常的表现是这台机器上所有的 Subtask 或者 TM 都会产生问题。
四、场景优化:动线分析
4.1 什么是动线
用户点击以及页面展现的浏览路径称之为是动线;以搜索词举例,在京东平台首先搜索台灯,然后又搜索台灯学习,最后搜索儿童学习护眼台灯,从台灯到台灯学习,到儿童学习护眼台灯,这样搜索词的线称为搜索词动线。
动线分析的作用:寻找决定转化的关键路径点以理解用户决策习惯;经常相邻查询的搜索词通过导流工具串联,发现趋势动线;同一个用户对不同排序策略的接受程度,最终从细分的用户类型,提出个性化的导购布局和策略建议;
4.2 数据建模
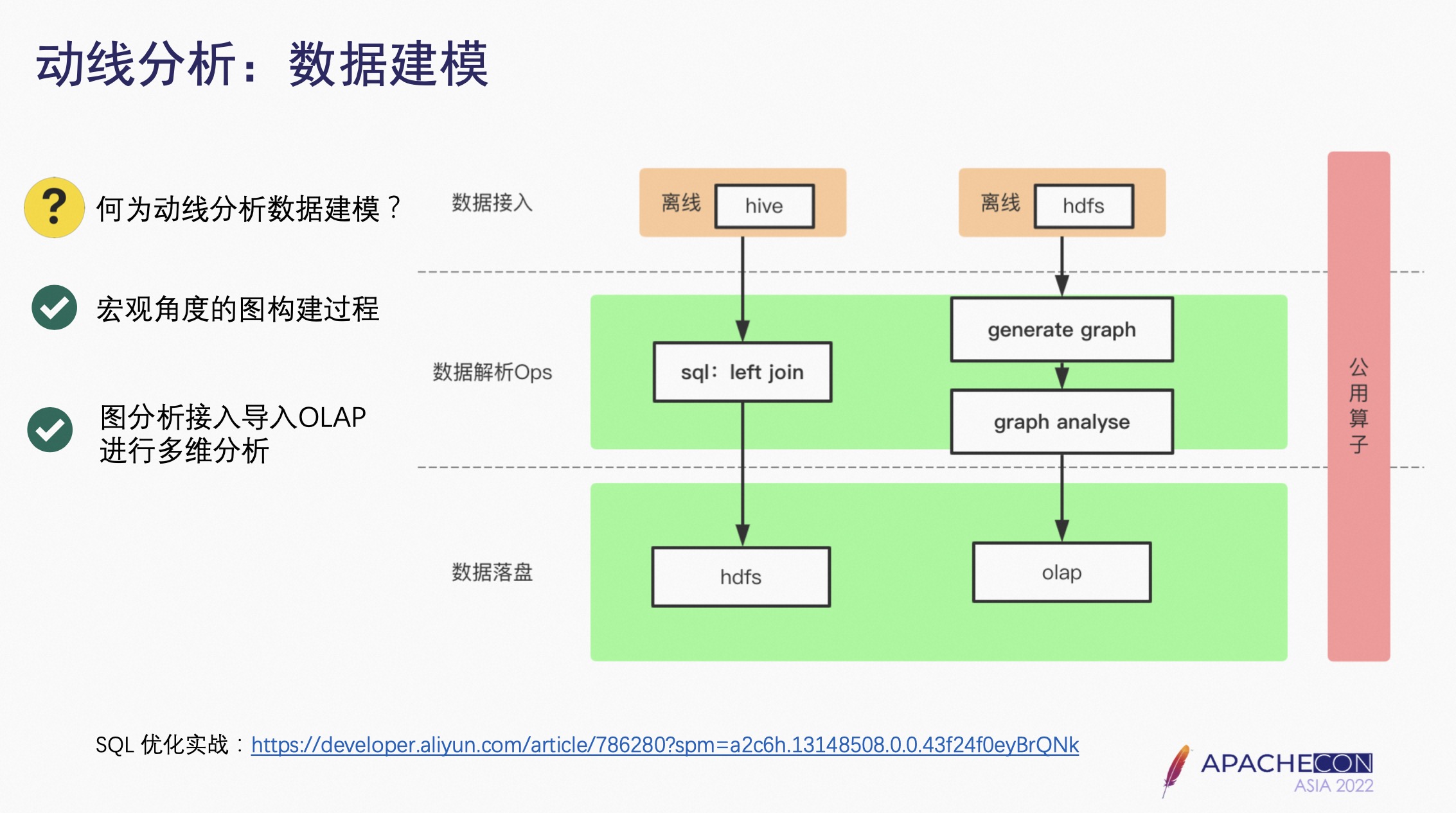
涉及到串联相邻的搜索词问题,需要从宏观的角度进行数据建模。
首先在京东每天 PB 数据量的动线数据分析下,现有的图结构是没有办法解决这个问题。目前最常用的一个分析方法,是把大批量的这种数据全部同时灌到数据库里,然后等离线数据运行一段时间,拿到分析的结果从结果上去分析。
当前业界在线图数据库进行这种大数据量的图分析,会严重地影响数据库的运行和对外提供服务,因此引入 Flink Gelly 技术栈,通过类似 MySQL 与 Hive 的模式,解决这种大规模图分析问题。
解决方案:首先是把图的源数据通过 Flink SQL 从 Hive 里取出数据,通过 Left Join 把每个 Session ID 下面的 Query 链连起来,然后导入到 HDFS 里;从 HDFS 里读动线的数据,并且把动线的数据生成一个 Graph,根据数据科学家提出的分析条件,将图的分析的结果,直接灌到 OLAP 里进行多维的分析;数据流实时计算的框架,从 Hive 或者 HDFS 里读数据,然后通过数据的 Join,包括写 HDFS、Graph Generate、Graph Analyse 等以可配置化的形式,生成公用算子放到算子库里,对于搜索、推荐或者是广告等所有涉及到动线分析的部门,都可以用到。
4.3 模型建模
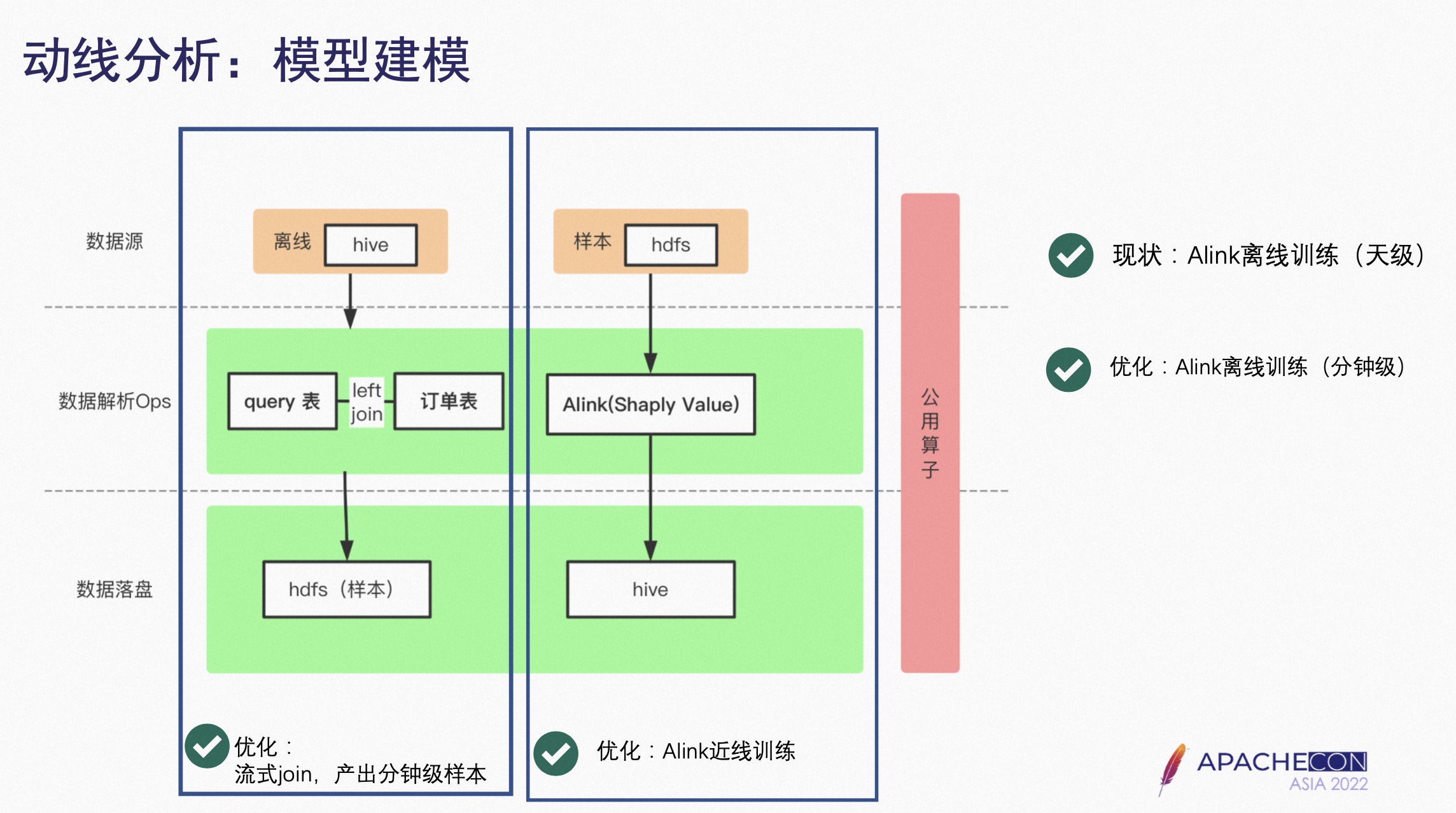
如果要对用户进行细分和个性化的分析,就涉及到模型建模。
首先是样本生产的过程,需要把数据从 Hive 里拿到,针对搜索词动线分析需要拿到用户搜索词的表,然后和相应的订单表里决定下单的 Query 进行左连接,生成样本放到 HDFS 里。
训练任务是从 HDFS 里把这些数据灌到 Alink 里进行 Shaply Value 建模,最终的 Query 重要度写到 Hive 里。
全链路是以公用算子的方式提供,目前京东采用这种离线训练的方式,相当于是天级,之后希望天级训练的模式实时化,做成分钟级的或者流式的 Join。
五、场景优化:FLINK 一站式机器学习
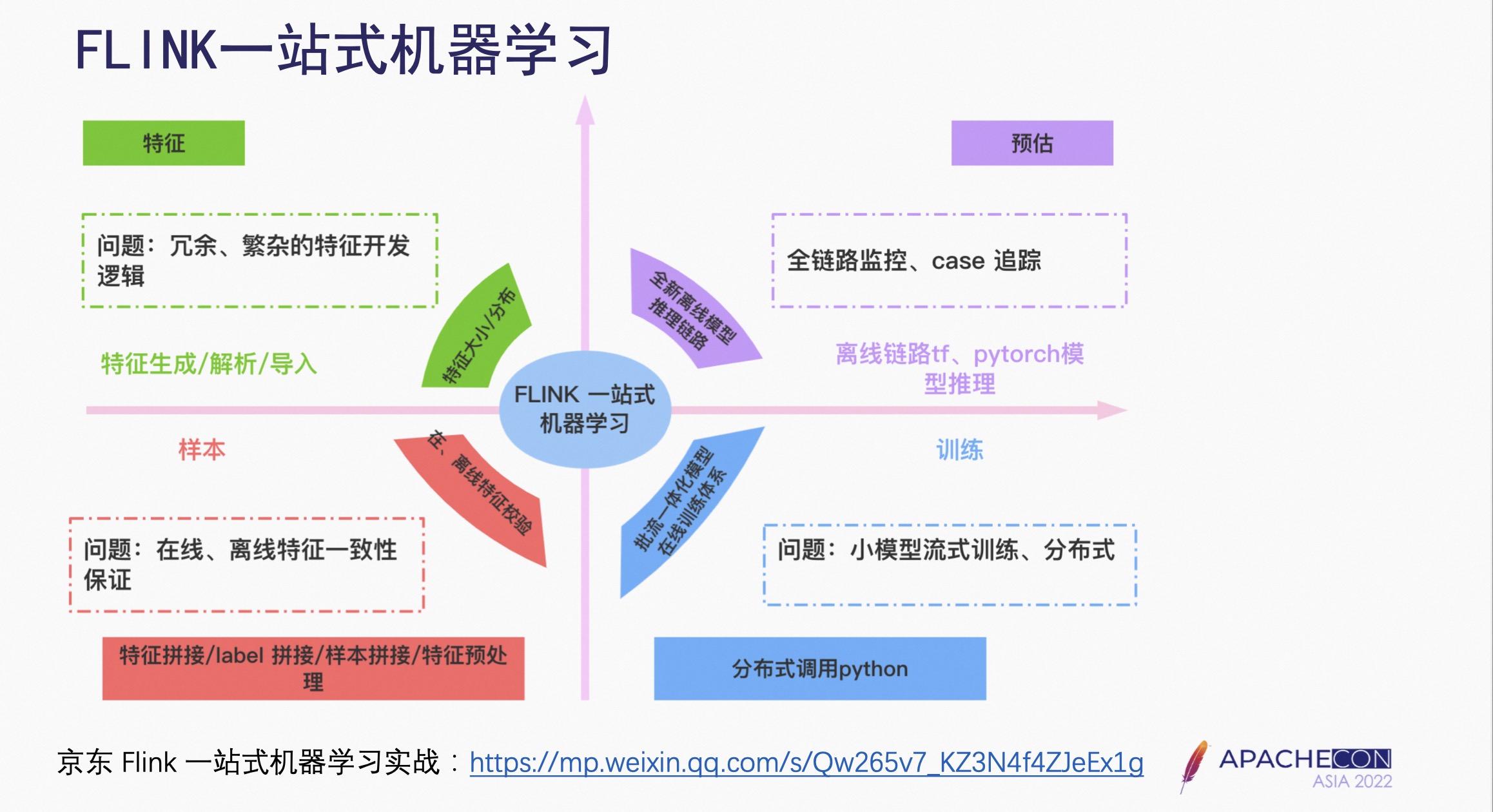
机器学习可以从四个方面来描述:特征、样本、训练、预估,而每个方面都有相应的问题(如上图)。
5.1 特征
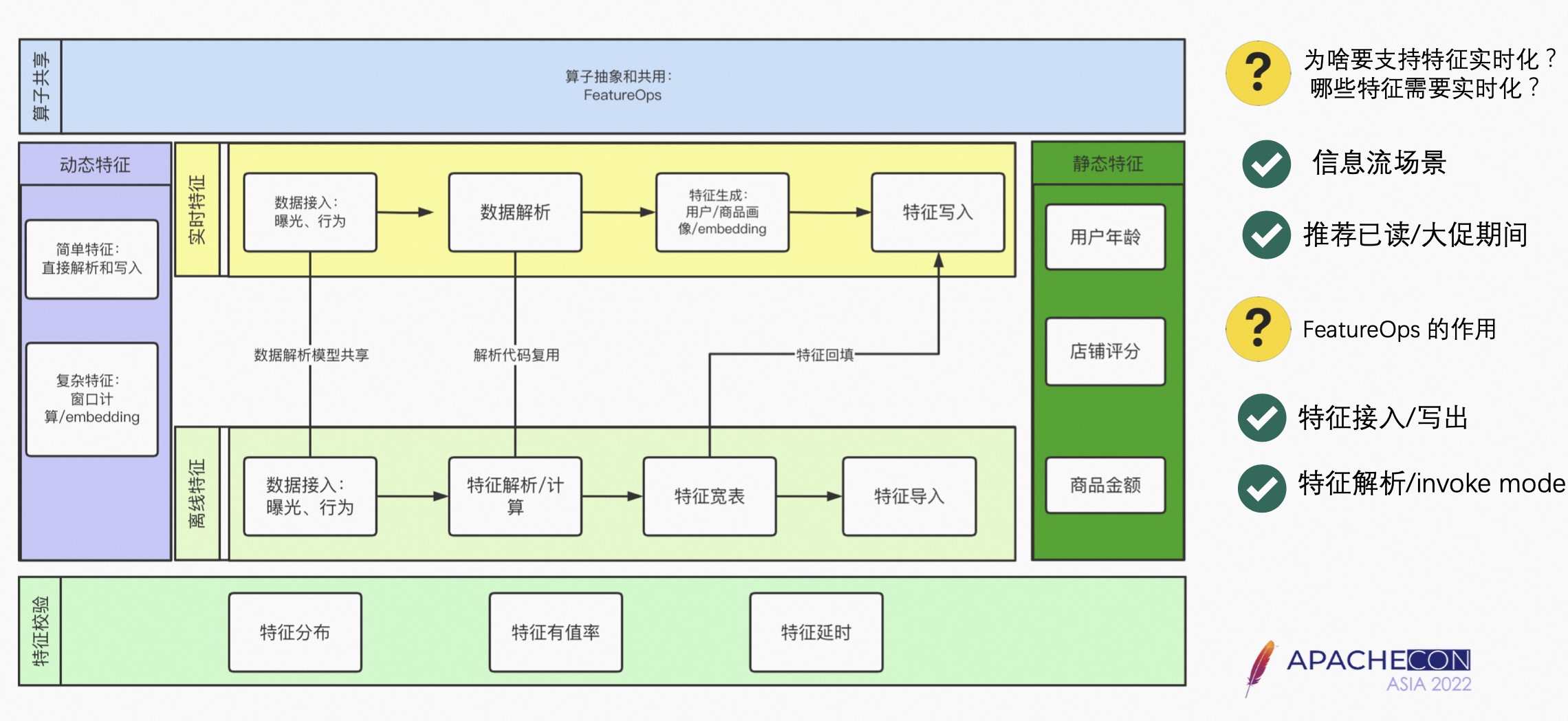
从生成的角度,特征分为实时特征和离线特征;从特征的特性分为静态特征和动态特征。
- 静态特征是相对变化不太大的特征,比如用户的年龄、店铺评分、商品金额,可以把静态特征和离线特征相对应;
- 动态特征比如近一个小时内的点赞量,或者近一个小时内的点击量,动态特征和实时特征相对应。
离线特征可以分为特征的整体生成过程。
- 特征一般是放到 Hive 里,会涉及到一些特征的解析以及计算,最终生成一个特征的大宽表,然后把这些特征放到 Redis 里,如果是实时特征,涉及到数据接入以及数据解析行为。
- 特征生成可以认为是业务化的过程,特征写入可以直接写入 Redis 里。
- FeatureOPS 主要是专注于特征生成,如果特征解析涉及到业务算子,也可以用 FeatureOPS 来做。
5.2 样本
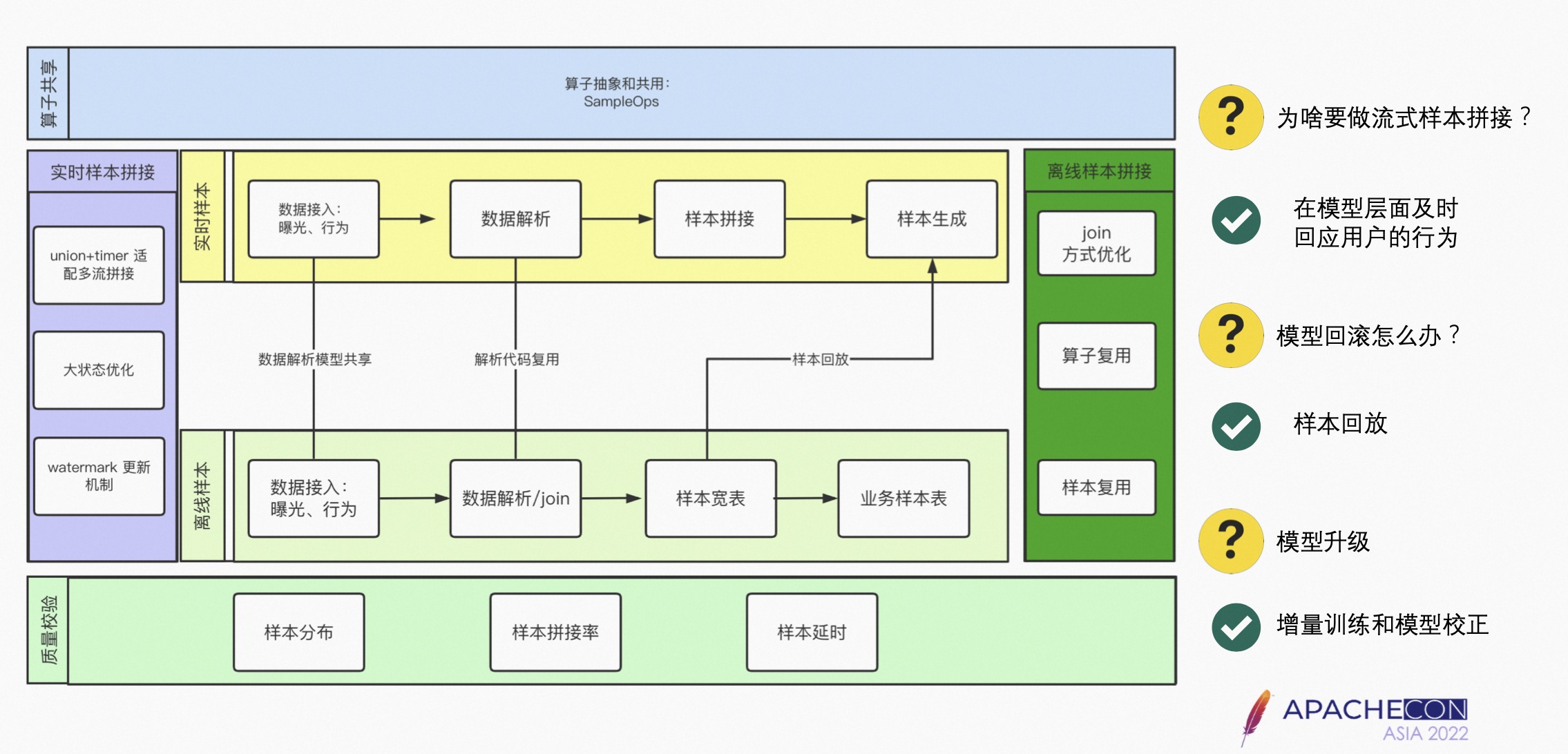
样本分为实时样本拼接和离线样本拼接两个链路;针对样本的特性,有离线的样本和实时的样本两个链路。
- 离线的样本拼接:通过 Join 存到数仓里,从数仓里拿取用户的曝光以及行为日志后,通过一系列的 Join 操作,形成样本的宽表,每个业务可以从样本宽表拿到属于自己的样本进行模型的训练。
- 实时的链路拼接也是相同的,区别是样本拼接为实时的。Flink 样本基本上都是双流的,采用 Unit 和 Timer 模式,适配多流的样本拼接,会涉及到大状态的优化,大状态目前用的 State Backend 是 Roll SDB。Watermark 更新机制是采用最慢的时间作为更新的机制,如果某一个行为流的数据量比较少,则会导致 Watermark 不更新的问题。
- 实时样本拼接针相对离线的样本拼接更加困难,包括一个窗口的选择、一些业务上的样本拼接等。
Sample OPS 做样本质量的校验:首先在样本生成的阶段,需要做样本的分布,如正负样本的分布;其次在做实时样本或者是离线样本拼接时,需要对拼接率做监测;观察任务的延时率,即每一条样本的延时情况。
模型升级定义为只有模型进行模型校正时,才会认为它升级了,而增量训练不是模型升级。
5.3 模型 online learning
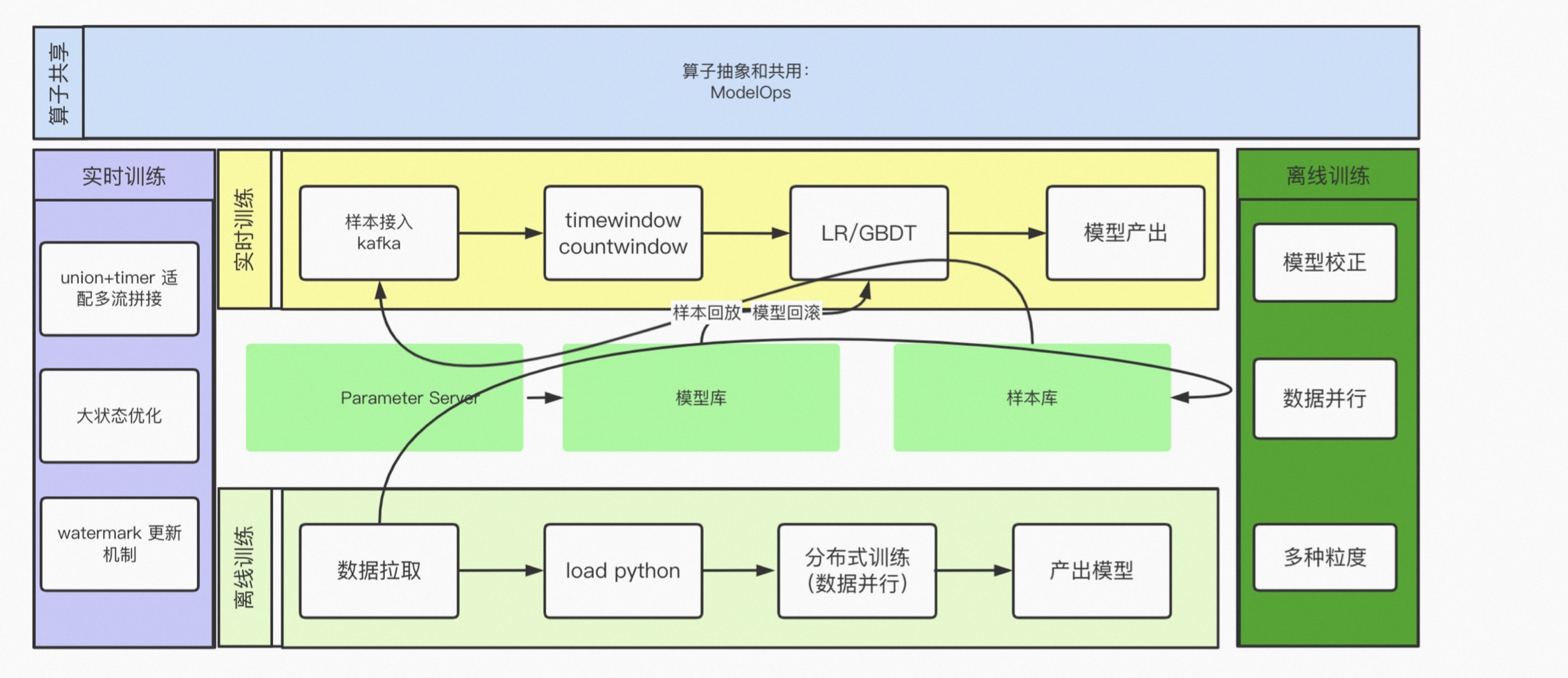
模型 online learning 是指数据科学方向,并非大模型的方向。按照特征和样本实时离线的 Template,把模型分为实时和离线两种。
实时训练涉及到模型实时参数的更新,但并非每一条数据训练一次,由超时时间 CountWindow 解决这个问题,比如 Count 达到 1 万条或者超时时间 5 分钟,来解决 Mini Batch 的问题。
针对 Online Learning,目前没有办法离线地做 AB,因此当一批数据进来时,可以先训练出一个模型,同样用这一批数据做 AB,以达到训练和 AB 的一体化。同时用离线的大数据量训练出来的模型,去及时校正实时训练出来的模型,防止模型训偏了;然后任务内部采用 Keyby 方式实现数据并行,解决模型分布式的问题。
举例,如 Profit 模型,是采用报警维度指标来设置,同时在模型产出时将模型推到模型库,然后 Parameter Server 会不停地在模型库里面把当前的模型的参数快照打到模型库里。
5.4 预估
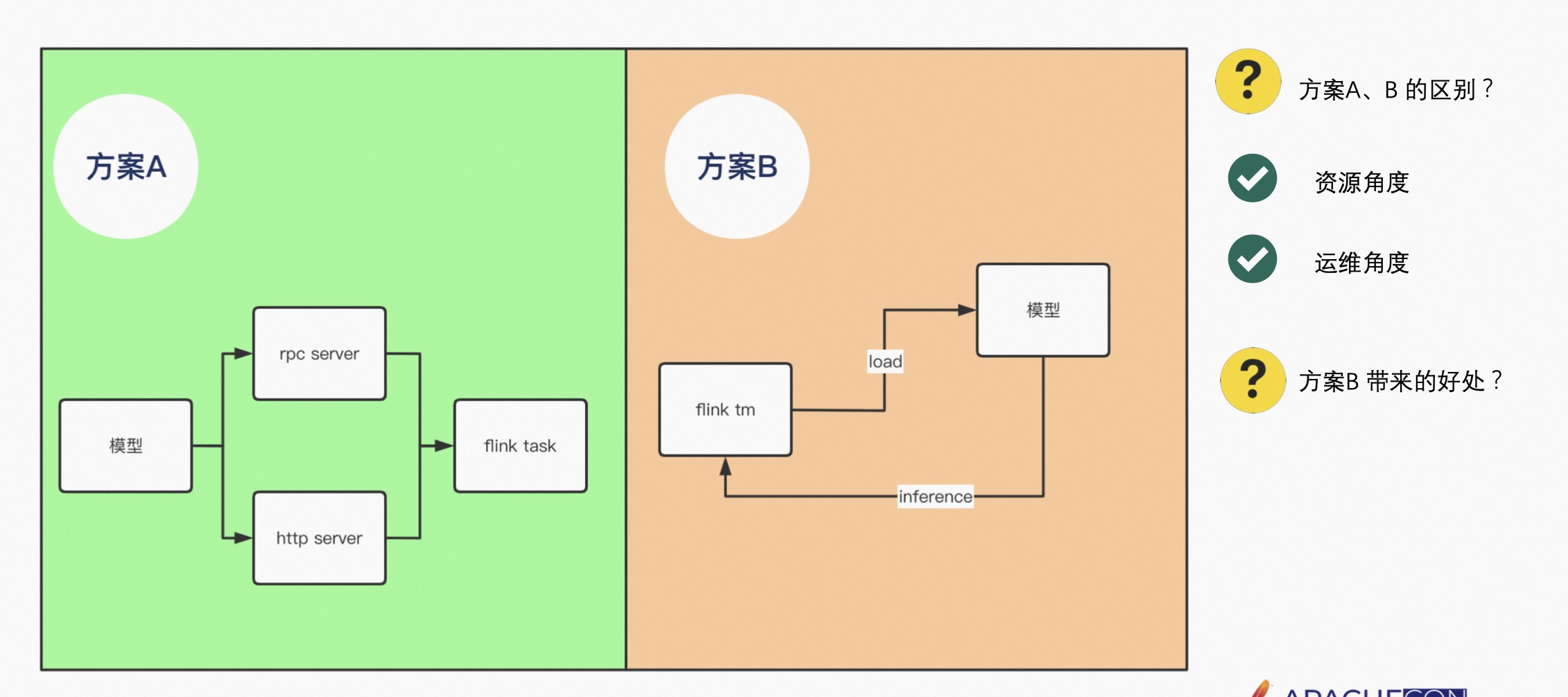
Flink 做预估目前有两种方案:
方案 A 是将模型如 Tensorflow 或者 PyTorch 模型,通过 RPC 的方式或者 HTTP 的方式部署 Server,由 Flink Task 去远程 Invoke RPC 或者 HTTP,会有网络的开销。因为 Flink Task 可能是实时的,也有可能是离线的,所以在 invoke RPC 时,不可能让它随着 Flink 任务的启动而启动,或者随着 Flink 任务的停止而停止,需要有人来运维该 Server。
方案 B 是将模型 Load 到 Flink TM 内部,即在 Flink TM 内部 Inference 该模型,其优点是不用去维护 RPC 或者 HTTP 的 Server,从资源的角度减少了网络开销,节省了资源。
点击查看更多技术内容