
大数据处理学习笔记2.1 初识Spark
迪丽瓦拉
2025-05-29 16:09:53
0次
文章目录
- 零、本节学习目标
- 一、Spark的概述
- (一)Spark的组件
- 1、Spark Core
- 2、Spark SQL
- 3、Spark Streaming
- 4、MLlib
- 5、Graph X
- 6、独立调度器、Yarn、Mesos
- (二)Spark的发展史
- 二、Spark的特点
- (一)速度快
- (二)易用性
- (三)通用性
- (四)兼容性
- (五)代码简洁
- 1、采用MR实现词频统计
- 2、采用Spark实现词频统计
- 三、Spark的应用场景
- 四、Spark与Hadoop的对比
零、本节学习目标
- 了解什么是Spark计算框架
- 了解Spark计算框架的特点
- 了解Spark计算框架的应用场景
- 理解Spark框架与Hadoop框架的对比
一、Spark的概述
(一)Spark的组件
- Spark在
2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。
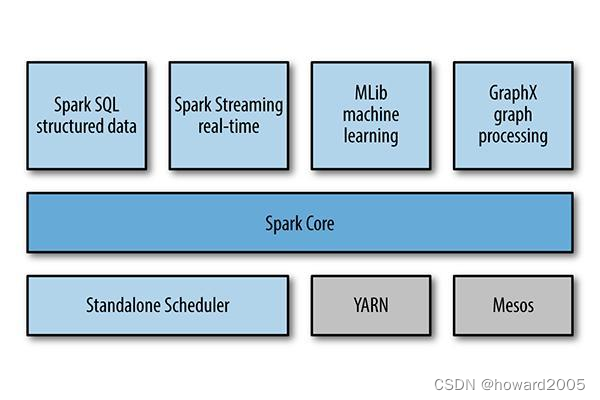
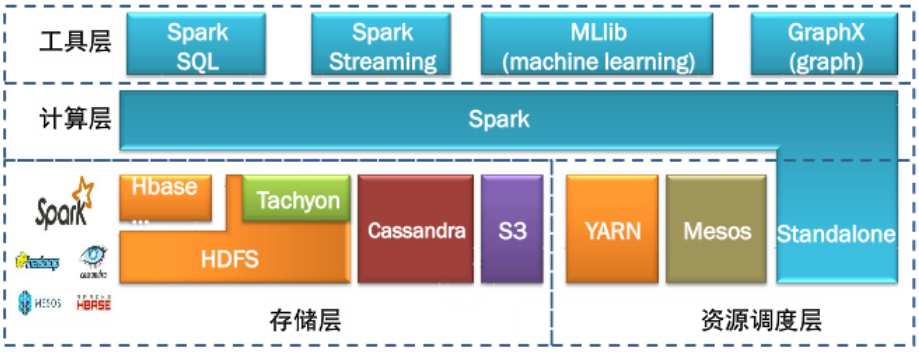
1、Spark Core
- Spark核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含对弹性分布式数据集的API定义。
2、Spark SQL
- 用来操作结构化数据的核心组件,通过Spark SQL可直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。
3、Spark Streaming
- Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业。
4、MLlib
- Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。
5、Graph X
- Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口及丰富的功能和运算符,便于对分布式图处理的需求,能在海量数据上运行复杂的图算法。
6、独立调度器、Yarn、Mesos
- 集群管理器,负责Spark框架高效地在一个到数千个节点之间进行伸缩计算的资源管理。
(二)Spark的发展史
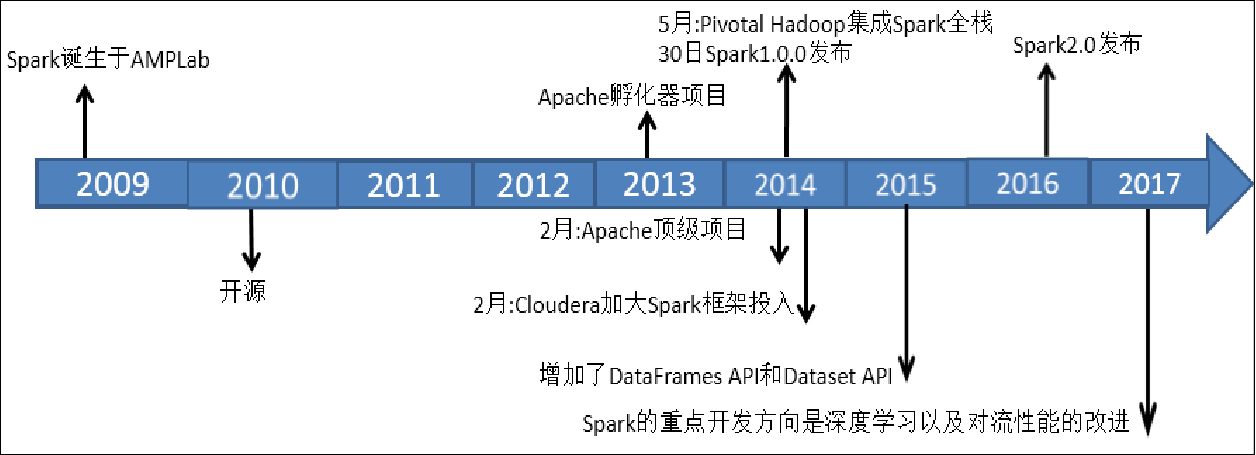
- 对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目,整个过程不到五年时间。
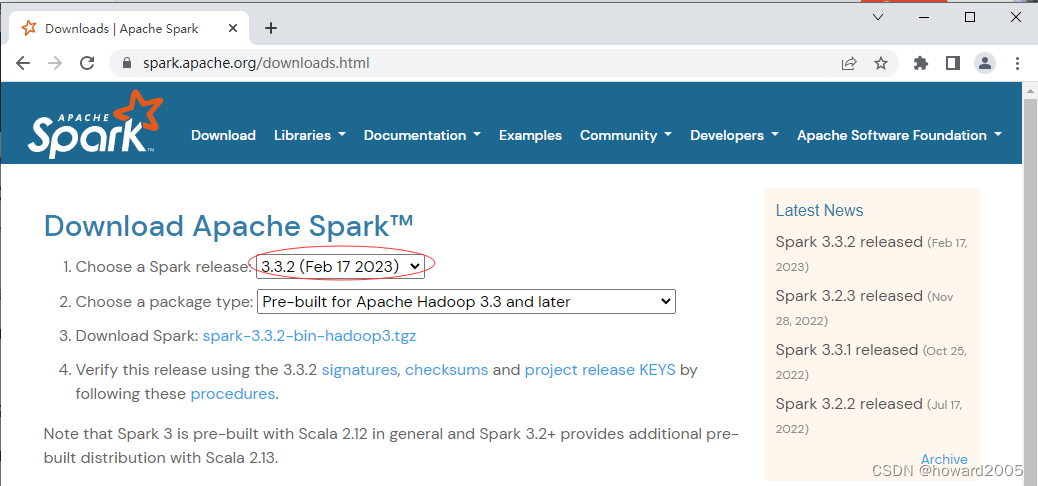
- Spark目前最新版本是2023年2月17日发布的Spark3.3.2
二、Spark的特点
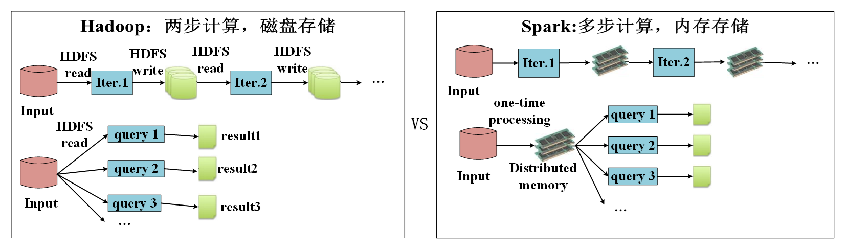
- Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
- Spark官网上给出Spark的特点

(一)速度快
- 与MapReduce相比,Spark可以支持包括Map和Reduce在内的更多操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph,简称DAG),各个操作的中间数据则会被保存在内存中。因此处理速度比MapReduce更加快。Spark通过使用先进的DAG调度器、查询优化器和物理执行引擎,从而能够高性能的实现批处理和流数据处理。
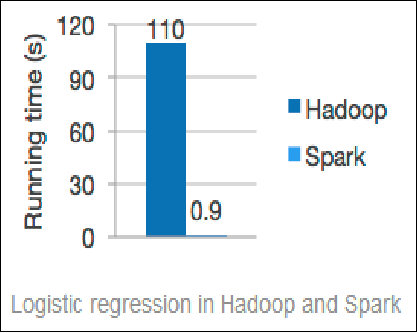
(二)易用性
- Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高级运算符,使得编写并行应用程序变得容易并且可以在Scala、Python或R的交互模式下使用Spark。

(三)通用性
- Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming,并且支持在一个应用中同时使用这些组件。
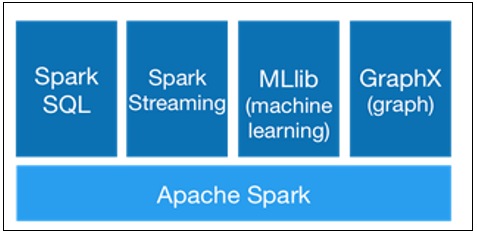
(四)兼容性
- 用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

(五)代码简洁
- 参看【经典案例【词频统计】十一种实现方式】
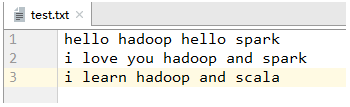
1、采用MR实现词频统计
- 编写WordCountMapper
package net.hw.wc;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WordCountMapper extends Mapper {@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 获取行内容String line = value.toString();// 按空格拆分得到单词数组String[] words = line.split(" ");// 遍历单词数组,生成输出键值对for (int i = 0; i < words.length; i++) {context.write(new Text(words[i]), new IntWritable(1));}}
}
- 编写WordCountReducer
package net.hw.wc;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountReducer extends Reducer {@Overrideprotected void reduce(Text key, Iterable values, Context context)throws IOException, InterruptedException {// 定义键出现次数int count = 0;// 遍历输入值迭代器for (IntWritable value : values) {count += value.get(); // 其实针对此案例,可用count++来处理}// 输出新的键值对,注意要将java的int类型转换成hadoop的IntWritable类型context.write(key, new IntWritable(count));}
}
- 编写WordCountDriver
package net.hw.wc;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;public class WordCountDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(WordCountDriver.class);// 设置Mapper类job.setMapperClass(WordCountMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(IntWritable.class);// 设置Reducer类job.setReducerClass(WordCountReducer.class);// 设置reduce任务输出键类型job.setOutputKeyClass(Text.class);// 设置reduce任务输出值类型job.setOutputValueClass(IntWritable.class);// 设置分区数量(reduce任务的数量,结果文件的数量)job.setNumReduceTasks(3);// 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/word/input");// 创建输出目录Path outputPath = new Path(uri + "/word/result");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录(第二个参数设置是否递归)fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录(只能一个)FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件系统数据字节输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
- 运行程序WordCountDriver,查看结果
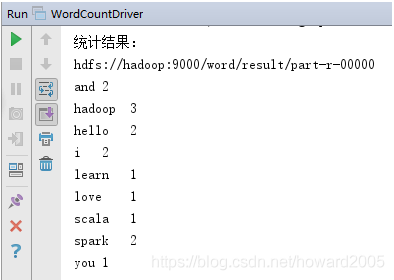
2、采用Spark实现词频统计
- 编写WordCount
package net.hw.spark.wcimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("wordcount")val sc = new SparkContext(conf)val rdd = sc.textFile("test.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)rdd.foreach(println)rdd.saveAsTextFile("result")}
}
- 启动WordCount,查看结果
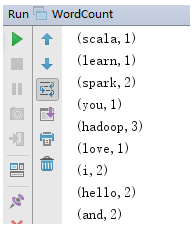
- 大家可以看出,完成同样的词频统计任务,Spark代码比MapReduce代码简洁很多。
三、Spark的应用场景
四、Spark与Hadoop的对比
相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
A.机器学习入门算法(三):基...
机器学习算法(三):K近邻(k-nearest neigh...
数字温湿度传感器DHT11模块...
模块实例https://blog.csdn.net/qq_38393591/article/deta...
有限元三角形单元的等效节点力
文章目录前言一、重新复习一下有限元三角形单元的理论1、三角形单元的形函数(Nÿ...
Redis 所有支持的数据结构...
Redis 是一种开源的基于键值对存储的 NoSQL 数据库,支持多种数据结构。以下是...
win下pytorch安装—c...
安装目录一、cuda安装1.1、cuda版本选择1.2、下载安装二、cudnn安装三、pytorch...
MySQL基础-多表查询
文章目录MySQL基础-多表查询一、案例及引入1、基础概念2、笛卡尔积的理解二、多表查询的分类1、等...
keil调试专题篇
调试的前提是需要连接调试器比如STLINK。 然后点击菜单或者快捷图标均可进入调试模式。 如果前面...
MATLAB | 全网最详细网...
一篇超超超长,超超超全面网络图绘制教程,本篇基本能讲清楚所有绘制要点&#...
IHome主页 - 让你的浏览...
随着互联网的发展,人们越来越离不开浏览器了。每天上班、学习、娱乐,浏览器...
TCP 协议
一、TCP 协议概念 TCP即传输控制协议(Transmission Control ...
营业执照的经营范围有哪些
营业执照的经营范围有哪些 经营范围是指企业可以从事的生产经营与服务项目,是进行公司注册...
C++ 可变体(variant...
一、可变体(variant) 基础用法 Union的问题: 无法知道当前使用的类型是什...
血压计语音芯片,电子医疗设备声...
语音电子血压计是带有语音提示功能的电子血压计,测量前至测量结果全程语音播报...
MySQL OCP888题解0...
文章目录1、原题1.1、英文原题1.2、答案2、题目解析2.1、题干解析2.2、选项解析3、知识点3...
【2023-Pytorch-检...
(肆十二想说的一些话)Yolo这个系列我们已经更新了大概一年的时间,现在基本的流程也走走通了,包含数...
实战项目:保险行业用户分类
这里写目录标题1、项目介绍1.1 行业背景1.2 数据介绍2、代码实现导入数据探索数据处理列标签名异...
记录--我在前端干工地(thr...
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前段时间接触了Th...
43 openEuler搭建A...
文章目录43 openEuler搭建Apache服务器-配置文件说明和管理模块43.1 配置文件说明...