
《动手学深度学习 v2》之计算性能和优化算法
迪丽瓦拉
2025-05-29 03:33:01
0次
计算性能
12.1. 编译器和解释器

# 命令式编程使得新模型的设计变得容易,因为可以依据控制流编写代码,并拥有相对成熟的Python软件生态。
# 符号式编程要求我们先定义并且编译程序,然后再执行程序,其好处是提高了计算性能。import torch
from torch import nn
from d2l import torch as d2l#命令式编程(imperative programming)
def add(a, b):return a + bdef fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return gprint(fancy_func(1, 2, 3, 4))#12.1.1. 符号式编程:代码通常只在完全定义了过程之后才执行计算(Theano和TensorFlow(后者已经获得了命令式编程的扩展))
#只要某个变量不再需要,编译器就可以释放内存(或者从不分配内存),或者将代码转换为一个完全等价的片段
#比如:f = add(c, d)、g = add(e, f)、g = add(e, f) -> 优化和重写为print((1 + 2) + (3 + 4))甚至print(10)
def add_():return '''
def add(a, b):return a + b
'''def fancy_func_():return '''
def fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return g
'''def evoke_():return add_() + fancy_func_() + 'print(fancy_func(1, 2, 3, 4))'#步骤:
prog = evoke_() #1)定义计算流程;
print(prog)
y = compile(prog, '', 'exec') #将流程编译成可执行的程序;
exec(y) #给定输入,调用编译好的程序执行。#12.1.2. 混合式编程
#12.1.3. Sequential的混合式编程
# 生产网络的工厂模式
def get_net():net = nn.Sequential(nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, 2))return net#key:通过使用torch.jit.script函数来转换模型,我们就有能力编译和优化多层感知机中的计算,而模型的计算结果保持不变
x = torch.randn(size=(1, 512))
net = get_net()
print(net(x))
net = torch.jit.script(net)
print(net(x))#验证torch.jit.script
#12.1.3.1. 通过混合式编程加速
#@save
class Benchmark:"""用于测量运行时间"""def __init__(self, description='Done'):self.description = descriptiondef __enter__(self):self.timer = d2l.Timer()return selfdef __exit__(self, *args):print(f'{self.description}: {self.timer.stop():.4f} sec')net = get_net()
with Benchmark('无torchscript'):for i in range(1000): net(x)net = torch.jit.script(net)
with Benchmark('有torchscript'):for i in range(1000): net(x)#12.1.3.2. 序列化
# 编译模型的好处之一是我们可以将模型及其参数序列化(保存)到磁盘。
# 这允许这些训练好的模型部署到其他设备上,并且还能方便地使用其他前端编程语言。同时,通常编译模型的代码执行速度也比命令式编程更快。
net.save('my_mlp')
#!ls -lh my_mlp*
12.2. 异步计算
import os
import subprocess
import numpy
import torch
from torch import nn
from d2l import torch as d2l
#异步编程(asynchronous programming)模型来提高性能
#PyTorch则使用了Python自己的调度器来实现不同的性能权衡。对PyTorch来说GPU操作在默认情况下是异步的。#12.2.1. 通过后端异步处理
# GPU计算热身
device = d2l.try_gpu()with d2l.Benchmark('numpy'):for _ in range(10):a = numpy.random.normal(size=(1000, 1000))b = numpy.dot(a, a)#NumPy点积是在CPU上执行的with d2l.Benchmark('torch'):for _ in range(10):a = torch.randn(size=(1000, 1000), device=device)#1)PyTorch的tensor是在GPU上定义的b = torch.mm(a, a) #2)默认情况下,GPU操作在PyTorch中是异步的with d2l.Benchmark():for _ in range(10):a = torch.randn(size=(1000, 1000), device=device)b = torch.mm(a, a)torch.cuda.synchronize(device) #3)将默认GPU操作变成同步化#广义上说,PyTorch有一个用于与用户直接交互的前端(例如通过Python),还有一个由系统用来执行计算的后端。用户可以用各种前端语言编写PyTorch程序,如Python和C++。不管使用的前端编程语言是什么,PyTorch程序的执行主要发生在C++实现的后端。
#1)Python前端线程不需要执行实际的计算(只是将任务返回到后端队列)。因此,不管Python的性能如何,对程序的整体性能几乎没有影响
#2)为什么是异步的:要使其工作,后端必须能够跟踪计算图中各个步骤之间的依赖关系。因此,不可能并行化相互依赖的操作。
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
print(z)12.3. 自动并行
import torch
from d2l import torch as d2l#通常情况下单个操作符将使用所有CPU或单个GPU上的所有计算资源
#并行化对单设备计算机来说并不是很有用,而并行化对于多个设备就很重要了。虽然并行化通常应用在多个GPU之间,但增加本地CPU以后还将提高少许性能。#12.3.1. 基于GPU的并行计算
devices = d2l.try_all_gpus()
def run(x):return [x.mm(x) for _ in range(50)]x_gpu1 = torch.rand(size=(400, 400), device=devices[0])
x_gpu2 = torch.rand(size=(400, 400), device=devices[1])# 1)预热设备(对设备执行一次传递)来确保缓存的作用不影响最终的结果
run(x_gpu1)
run(x_gpu2)
torch.cuda.synchronize(devices[0])
torch.cuda.synchronize(devices[1])# 2)如果删除两个任务之间的synchronize语句,系统就可以在两个设备上自动实现并行计算
with d2l.Benchmark('GPU1 time'):run(x_gpu1)torch.cuda.synchronize(devices[0])with d2l.Benchmark('GPU2 time'):run(x_gpu2)torch.cuda.synchronize(devices[1])# GPU1 time: 0.4970 sec
# GPU2 time: 0.4988 secwith d2l.Benchmark('GPU1 & GPU2'):run(x_gpu1)run(x_gpu2)torch.cuda.synchronize()#GPU1 & GPU2: 0.4983 sec < GPU1 time: 0.4970 sec + GPU2 time: 0.4988 sec#12.3.2. 并行计算与通信
#当执行分布式优化时,就需要移动数据来聚合多个加速卡上的梯度
def copy_to_cpu(x, non_blocking=False):return [y.to('cpu', non_blocking=non_blocking) for y in x]with d2l.Benchmark('在GPU1上运行'):y = run(x_gpu1)torch.cuda.synchronize()with d2l.Benchmark('复制到CPU'):y_cpu = copy_to_cpu(y)torch.cuda.synchronize()# 在GPU1上运行: 0.0129 sec
# 复制到CPU: 0.0423 sec#key:计算和通信之间存在的依赖关系是必须先计算y[i],然后才能将其复制到CPU。幸运的是,系统可以在计算y[i]的同时复制y[i-1],以减少总的运行时间
with d2l.Benchmark('在GPU1上运行并复制到CPU'):y = run(x_gpu1)y_cpu = copy_to_cpu(y, True)torch.cuda.synchronize()# 在GPU1上运行并复制到CPU: 0.0469 sec < 在GPU1上运行: 0.0129 sec + 复制到CPU: 0.0423 se
12.4 硬件
单机多卡并行

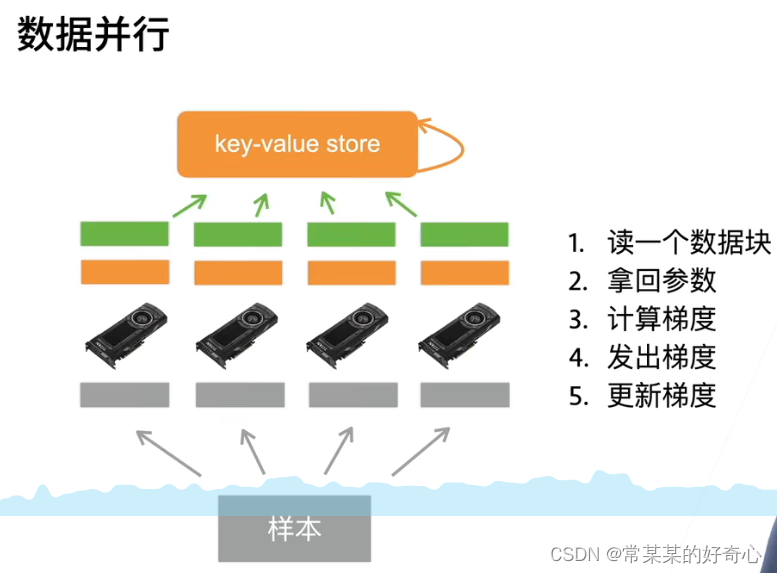
分布式训练



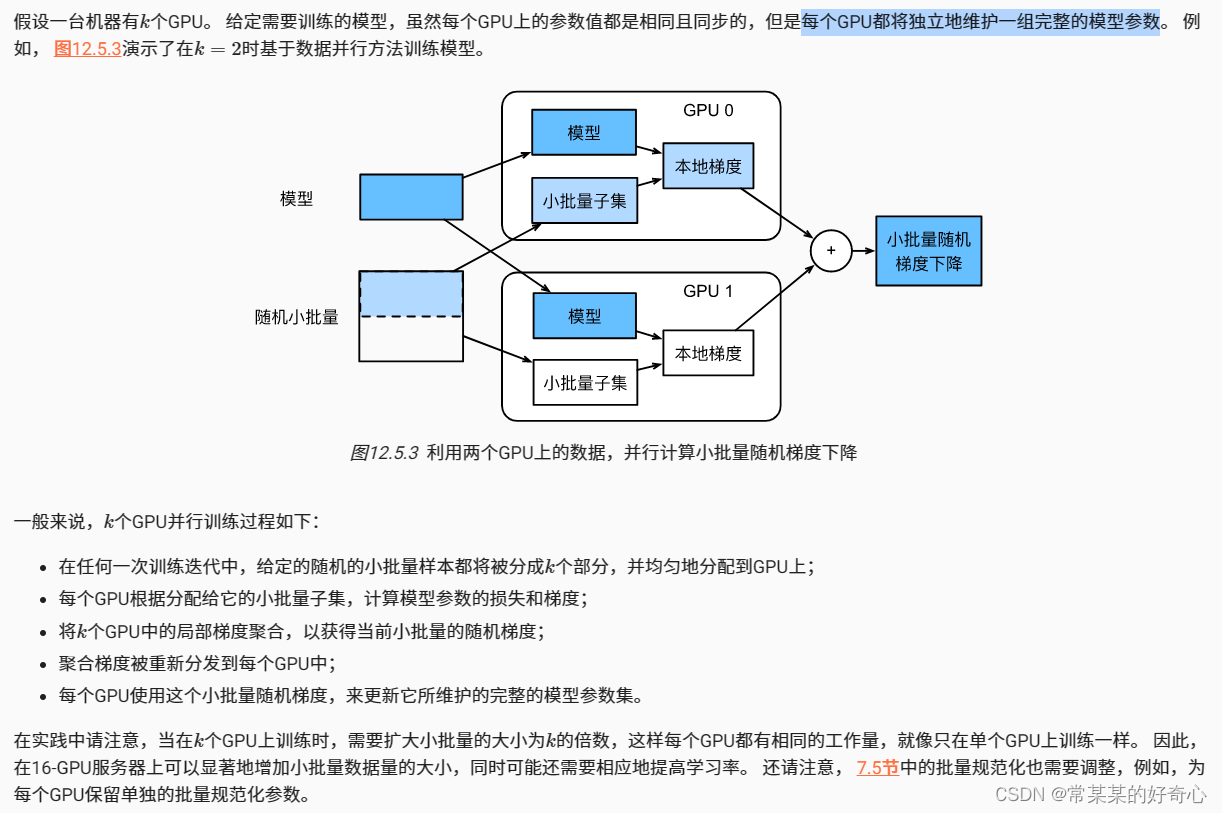
12.5. 多GPU训练:数据划分;累计梯度;model同步更新
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l#12.5.3. 简单网络
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]# 定义模型
def lenet(X, params):h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])h1_activation = F.relu(h1_conv)h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])h2_activation = F.relu(h2_conv)h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))h2 = h2.reshape(h2.shape[0], -1)h3_linear = torch.mm(h2, params[4]) + params[5]h3 = F.relu(h3_linear)y_hat = torch.mm(h3, params[6]) + params[7]return y_hat# 交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')############################核心########################################
#12.5.4. 数据同步 (key-key-key)
#1)注意:每个GPU都将独立地维护一组完整的模型参数
def get_params(params, device):new_params = [p.to(device) for p in params]for p in new_params:p.requires_grad_() #区别之前定义w,b时,就同时指定了requires_grad=Truereturn new_paramsnew_params = get_params(params, d2l.try_gpu(0))
print('b1 权重:', new_params[1])
print('b1 梯度:', new_params[1].grad)#2)在不同设备上创建具有不同值的向量并聚合它们
def allreduce(data):#data[0]的更新for i in range(1, len(data)):data[0][:] += data[i].to(data[0].device)#data[1]到data[len(data)-1]的更新for i in range(1, len(data)):data[i][:] = data[0].to(data[i].device)
'''
data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('allreduce之前:\n', data[0], '\n', data[1])
allreduce(data)
print('allreduce之后:\n', data[0], '\n', data[1])# allreduce之前:
# tensor([[1., 1.]], device='cuda:0')
# tensor([[2., 2.]], device='cuda:1')
# allreduce之后:
# tensor([[3., 3.]], device='cuda:0')
# tensor([[3., 3.]], device='cuda:1')
'''#12.5.5. 数据分发 (key-key-key)
#@save
def split_batch(X, y, devices):"""将X和y拆分到多个设备上"""assert X.shape[0] == y.shape[0]return (nn.parallel.scatter(X, devices),nn.parallel.scatter(y, devices))'''
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input :', data)
print('load into', devices)
print('output:', split)# input : tensor([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
# load into [device(type='cuda', index=0), device(type='cuda', index=1)]
# output: (tensor([[0, 1, 2, 3, 4],
# [5, 6, 7, 8, 9]], device='cuda:0'), tensor([[10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]], device='cuda:1'))
'''#12.5.6. 训练
def train_batch(X, y, device_params, devices, lr):#1)数据分发X_shards, y_shards = split_batch(X, y, devices)#2)在个均小批量子集中进行反向传播# 在每个GPU上分别计算损失ls = [loss(lenet(X_shard, device_W), y_shard).sum()for X_shard, y_shard, device_W in zip(X_shards, y_shards, device_params)]for l in ls: # 反向传播在每个GPU上分别执行l.backward()#3)注意写法# 将每个GPU的所有梯度相加,并将其广播到所有GPUwith torch.no_grad():for i in range(len(device_params[0])):allreduce([device_params[c][i].grad for c in range(len(devices))])#4)# 在每个GPU上分别更新模型参数for params in device_params:d2l.sgd(params, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量####################################################################def train(num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)# 将模型参数复制到num_gpus个GPUdevices = [d2l.try_gpu(i) for i in range(num_gpus)]device_params = [get_params(params, d) for d in devices]num_epochs = 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])timer = d2l.Timer()for epoch in range(num_epochs):timer.start()for X, y in train_iter:# 为单个小批量执行多GPU训练train_batch(X, y, device_params, devices, lr)torch.cuda.synchronize() #GPU同步后,算时间准一些print(timer.stop())# 在GPU0上评估模型animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')train(num_gpus=1, batch_size=256, lr=0.2)
#测试精度:0.84,2.4秒/轮,在[device(type='cuda', index=0)]train(num_gpus=2, batch_size=256, lr=0.2)
#测试精度:0.83,2.5秒/轮,在[device(type='cuda', index=0), device(type='cuda', index=1)]
#未加速可能原因:data读取本身就很慢;本身模型容量太小,batch_size相对单GPU减少一半128,学习性能变低;
#解决:模型增加,batch_size*2(多适合数据集的多样性),学习率也需要调整
12.6. 多GPU的简洁实现
import torch
from torch import nn
from d2l import torch as d2l#12.6.1. 简单网络
#@save
def resnet18(num_classes, in_channels=1):"""稍加修改的ResNet-18模型"""def resnet_block(in_channels, out_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(d2l.Residual(in_channels, out_channels,use_1x1conv=True, strides=2))else:blk.append(d2l.Residual(out_channels, out_channels))return nn.Sequential(*blk)# 该模型使用了更小的卷积核、步长和填充,而且删除了最大汇聚层net = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU())net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))net.add_module("resnet_block2", resnet_block(64, 128, 2))net.add_module("resnet_block3", resnet_block(128, 256, 2))net.add_module("resnet_block4", resnet_block(256, 512, 2))net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1,1)))net.add_module("fc", nn.Sequential(nn.Flatten(),nn.Linear(512, num_classes)))return net#12.6.2. 网络初始化
net = resnet18(10)
# 获取GPU列表
devices = d2l.try_all_gpus()
# 我们将在训练代码实现中初始化网络#12.6.3. 训练
def train(net, num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)# 在多个GPU上设置模型(key)net = nn.DataParallel(net, device_ids=devices)trainer = torch.optim.SGD(net.parameters(), lr)loss = nn.CrossEntropyLoss()timer, num_epochs = d2l.Timer(), 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])for epoch in range(num_epochs):net.train()timer.start()for X, y in train_iter:trainer.zero_grad()X, y = X.to(devices[0]), y.to(devices[0])l = loss(net(X), y) #实际是数据分发,并行化方式(nn.DataParallel)l.backward()trainer.step()timer.stop()animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')train(net, num_gpus=1, batch_size=256, lr=0.1)
#测试精度:0.90,13.6秒/轮,在[device(type='cuda', index=0)]
train(net, num_gpus=2, batch_size=512, lr=0.2)
#测试精度:0.82,8.2秒/轮,在[device(type='cuda', index=0), device(type='cuda', index=1)]
优化算法
11.1. 优化和深度学习
#11.1.1. 优化的目标
import numpy as np
import torch
from d2l import torch as d2ldef f(x):#经验风险:训练数据集的平均损失return x * torch.cos(np.pi * x)
def g(x):#风险:整个数据群的预期损失return f(x) + 0.2 * torch.cos(5 * np.pi * x)# 1)训练数据集的最低经验风险可能与最低风险(泛化误差)不同
x = torch.arange(0.5, 1.5, 0.01)
d2l.set_figsize((4.5, 2.5))
d2l.plot(x, [f(x), g(x)], 'x', 'risk')
d2l.annotate('min of\nempirical risk', (1.0, -1.2), (0.5, -1.1))
d2l.annotate('min of risk', (1.1, -1.05), (0.95, -0.5))
d2l.plt.show()#11.1.2. 深度学习中的优化挑战
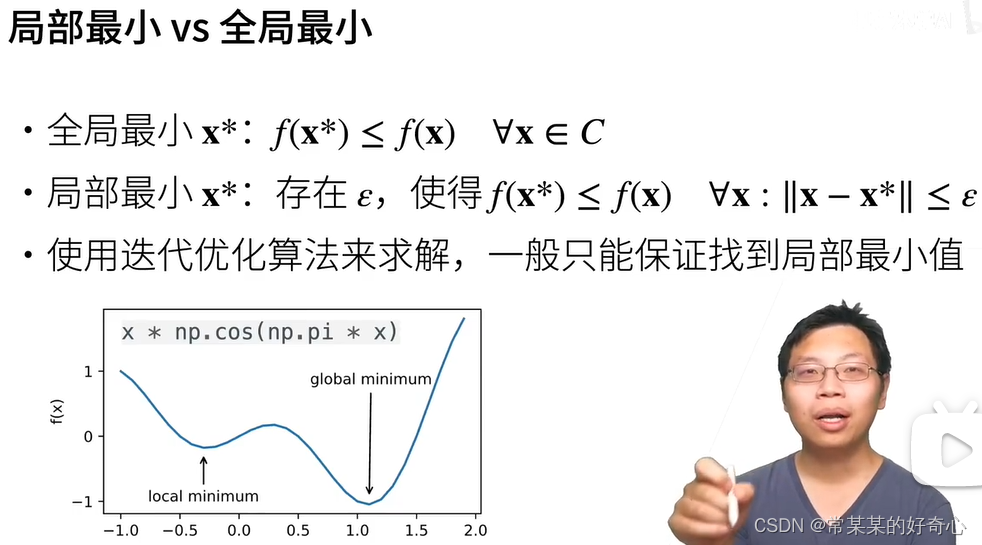
#11.1.2.1. 局部最小值
#当优化问题的数值解接近局部最优值时,随着目标函数解的梯度接近或变为零,通过最终迭代获得的数值解可能仅使目标函数局部最优,而不是全局最优。
# 只有一定程度的噪声可能会使参数跳出局部最小值。事实上,这是小批量随机梯度下降的有利特性之一。在这种情况下,小批量上梯度的自然变化能够将参数从局部极小值中跳出
x = torch.arange(-1.0, 2.0, 0.01)
d2l.plot(x, [f(x), ], 'x', 'f(x)')
d2l.annotate('local minimum', (-0.3, -0.25), (-0.77, -1.0))
d2l.annotate('global minimum', (1.1, -0.95), (0.6, 0.8))
d2l.plt.show()#11.1.2.2. 鞍点
#鞍点(saddle point)是指函数的所有梯度都消失但既不是全局最小值也不是局部最小值的任何位置
#较高维度的鞍点甚至更加隐蔽
x = torch.arange(-2.0, 2.0, 0.01)
d2l.plot(x, [x**3], 'x', 'f(x)')
d2l.annotate('saddle point', (0, -0.2), (-0.52, -5.0))
d2l.plt.show()x, y = torch.meshgrid(torch.linspace(-1.0, 1.0, 101), torch.linspace(-1.0, 1.0, 101))
z = x**2 - y**2ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 10, 'cstride': 10})
ax.plot([0], [0], [0], 'rx')
ticks = [-1, 0, 1]
d2l.plt.xticks(ticks)
d2l.plt.yticks(ticks)
ax.set_zticks(ticks)
d2l.plt.xlabel('x')
d2l.plt.ylabel('y')#11.1.2.3. 梯度消失
x = torch.arange(-2.0, 5.0, 0.01)
d2l.plot(x, [torch.tanh(x)], 'x', 'f(x)')
d2l.annotate('vanishing gradient', (4, 1), (2, 0.0))
d2l.plt.show()
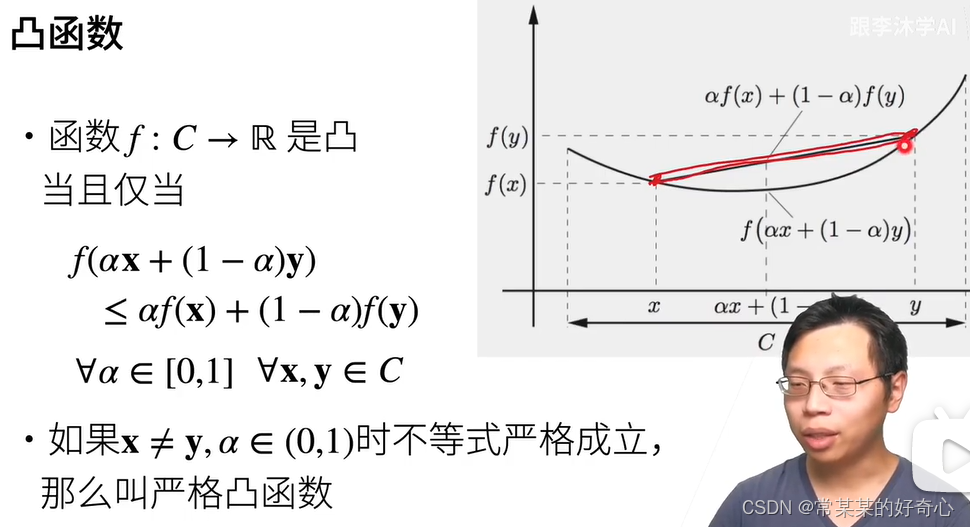
11.2. 凸性
import numpy as np
import torch
from d2l import torch as d2l#11.2.1.2. 凸函数
f = lambda x: 0.5 * x**2 # 凸函数
g = lambda x: torch.cos(np.pi * x) # 非凸函数
h = lambda x: torch.exp(0.5 * x) # 凸函数x, segment = torch.arange(-2, 2, 0.01), torch.tensor([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3))
for ax, func in zip(axes, [f, g, h]):d2l.plot([x, segment], [func(x), func(segment)], axes=ax)
d2l.plt.show()#11.2.2. 性质(凸函数)
#11.2.2.1. 局部极小值是全局极小值
f = lambda x: (x - 1) ** 2
d2l.set_figsize()
d2l.plot([x, segment], [f(x), f(segment)], 'x', 'f(x)')
d2l.plt.show()1.更新权重向量的优化算法
11.3. 梯度下降
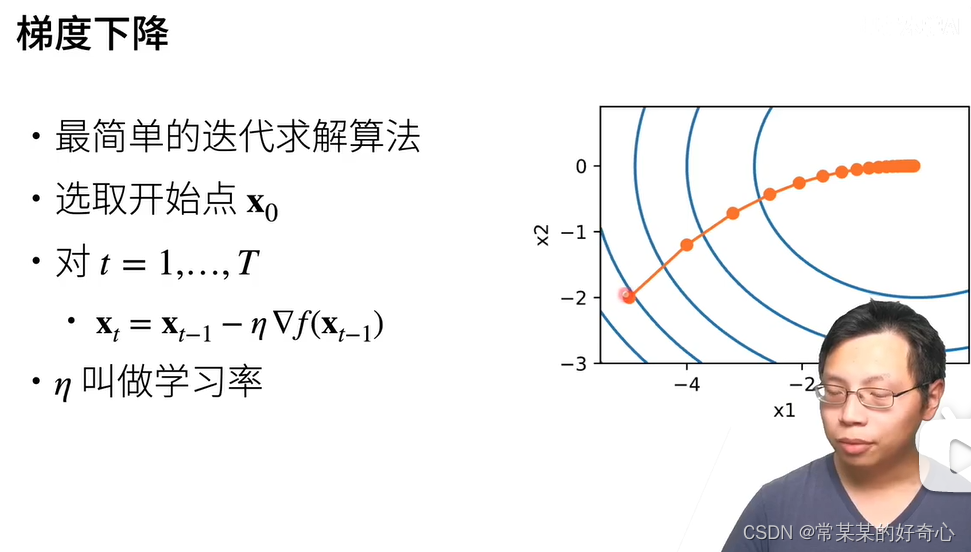
#11.3.1. 一维梯度下降
import numpy as np
import torch
from d2l import torch as d2ldef f(x): # 目标函数return x ** 2
def f_grad(x): # 目标函数的梯度(导数)return 2 * xdef gd(eta, f_grad):x = 10.0results = [x] #key1for i in range(10):x -= eta * f_grad(x)results.append(float(x))print(f'epoch 10, x: {x:f}')return resultsdef show_trace(results, f):n = max(abs(min(results)), abs(max(results)))f_line = torch.arange(-n, n, 0.01)d2l.set_figsize()d2l.plot([f_line, results], [[f(x) for x in f_line], [f(x) for x in results]], 'x', 'f(x)', fmts=['-', '-o'])
results = gd(0.2, f_grad)show_trace(results, f)
d2l.plt.show()#11.3.1.1. 学习率:
# 学习率(learning rate)决定目标函数能否收敛到局部最小值,以及何时收敛到最小值
# (不切实际的)高学习率如何导致较差的局部最小值
show_trace(gd(0.05, f_grad), f)
d2l.plt.show()
show_trace(gd(1.1, f_grad), f)
d2l.plt.show()#11.3.1.2. 局部最小值
c = torch.tensor(0.15 * np.pi)
def f(x): # 目标函数return x * torch.cos(c * x)
def f_grad(x): # 目标函数的梯度return torch.cos(c * x) - c * x * torch.sin(c * x)#这个函数有无穷多个局部最小值。 根据我们选择的学习率,我们最终可能只会得到许多解的一个。
show_trace(gd(2, f_grad), f)
d2l.plt.show()#11.3.2. 多元梯度下降
def train_2d(trainer, steps=20, f_grad=None): #@save"""用定制的训练机优化2D目标函数"""# s1和s2是稍后将使用的内部状态变量x1, x2, s1, s2 = -5, -2, 0, 0results = [(x1, x2)] #key2for i in range(steps):if f_grad:x1, x2, s1, s2 = trainer(x1, x2, s1, s2, f_grad)else:x1, x2, s1, s2 = trainer(x1, x2, s1, s2)results.append((x1, x2))print(f'epoch {i + 1}, x1: {float(x1):f}, x2: {float(x2):f}')return resultsdef show_trace_2d(f, results): #@save"""显示优化过程中2D变量的轨迹"""d2l.set_figsize()d2l.plt.plot(*zip(*results), '-o', color='#ff7f0e')x1, x2 = torch.meshgrid(torch.arange(-5.5, 1.0, 0.1),torch.arange(-3.0, 1.0, 0.1))d2l.plt.contour(x1, x2, f(x1, x2), colors='#1f77b4')d2l.plt.xlabel('x1')d2l.plt.ylabel('x2')def f_2d(x1, x2): # 目标函数return x1 ** 2 + 2 * x2 ** 2
def f_2d_grad(x1, x2): # 目标函数的梯度return (2 * x1, 4 * x2)
def gd_2d(x1, x2, s1, s2, f_grad):g1, g2 = f_grad(x1, x2)return (x1 - eta * g1, x2 - eta * g2, 0, 0)eta = 0.1
show_trace_2d(f_2d, train_2d(gd_2d, f_grad=f_2d_grad))
d2l.plt.show()#11.3.3. 自适应方法
#11.3.3.1. 牛顿法
c = torch.tensor(0.5) #凸
def f(x): # 目标函数return torch.cosh(c * x)
def f_grad(x): # 目标函数的梯度return c * torch.sinh(c * x)
def f_hess(x): # 目标函数的Hessianreturn c**2 * torch.cosh(c * x)def newton(eta=1):x = 10.0results = [x]for i in range(10):x -= eta * f_grad(x) / f_hess(x) #key3results.append(float(x))print('epoch 10, x:', x)return resultsshow_trace(newton(), f)
d2l.plt.show()c = torch.tensor(0.15 * np.pi) #非凸
def f(x): # 目标函数return x * torch.cos(c * x)
def f_grad(x): # 目标函数的梯度return torch.cos(c * x) - c * x * torch.sin(c * x)
def f_hess(x): # 目标函数的Hessianreturn - 2 * c * torch.sin(c * x) - x * c**2 * torch.cos(c * x)#一种方法是用取Hessian的绝对值来修正,另一个策略是重新引入学习率。
# 这似乎违背了初衷,但不完全是——拥有二阶信息可以使我们在曲率较大时保持谨慎,而在目标函数较平坦时则采用较大的学习率。
show_trace(newton(), f)
show_trace(newton(0.5), f)
d2l.plt.show()
11.4. 随机梯度下降 (单样本)
深度学习的 f (即 loss)是 依靠样本 模糊拟合出来的!
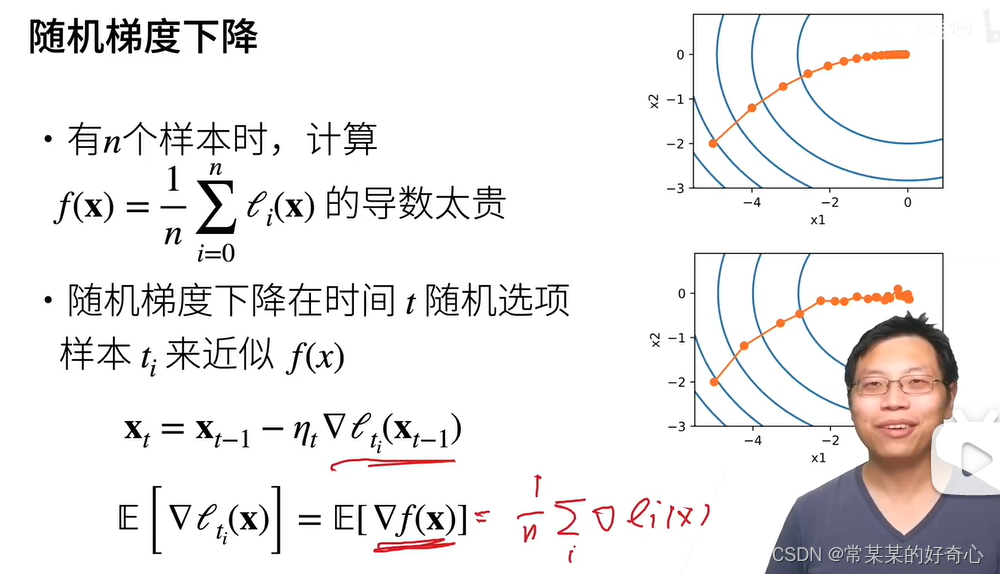
import math
import torch
from d2l import torch as d2l#11.4.1. 随机梯度更新
def f(x1, x2): # 目标函数return x1 ** 2 + 2 * x2 ** 2
def f_grad(x1, x2): # 目标函数的梯度return 2 * x1, 4 * x2def sgd(x1, x2, s1, s2, f_grad):g1, g2 = f_grad(x1, x2)# 模拟有噪声的梯度:向梯度添加均值为0、方差为1的随机噪声,以模拟随机梯度下降g1 += torch.normal(0.0, 1, (1,))g2 += torch.normal(0.0, 1, (1,))eta_t = eta * lr()return (x1 - eta_t * g1, x2 - eta_t * g2, 0, 0)def constant_lr():return 1eta = 0.1
lr = constant_lr #1)常数学习速度:即使我们接近最小值,我们仍然受到通过瞬间梯度所注入的不确定性的影响。
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=50, f_grad=f_grad))
d2l.plt.show()#11.4.2. 动态学习率(key优化)
def exponential_lr():# 在函数外部定义,而在内部更新的全局变量global tt += 1return math.exp(-0.1 * t)t = 1
lr = exponential_lr #2)指数衰减(exponential decay)来更积极地减低它。不幸的是,这往往会导致算法收敛之前过早停止
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=1000, f_grad=f_grad))def polynomial_lr():# 在函数外部定义,而在内部更新的全局变量global tt += 1return (1 + 0.1 * t) ** (-0.5)t = 1
lr = polynomial_lr #3)多项式衰减,其中学习率随迭代次数的平方根倒数衰减,那么仅在50次迭代之后,收敛就会更好
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=50, f_grad=f_grad))
d2l.plt.show()
11.5. 小批量随机梯度下降:平衡收敛速度和计算效率


#11.5.1. 向量化和缓存
import numpy as np
import torch
from torch import nn
from d2l import torch as d2ltimer = d2l.Timer()A = torch.zeros(256, 256)
B = torch.randn(256, 256)
C = torch.randn(256, 256)'''
# 逐元素计算A=BC
timer.start()
for i in range(256):for j in range(256):A[i, j] = torch.dot(B[i, :], C[:, j])
print(timer.stop())
# 逐列计算A=BC
timer.start()
for j in range(256):A[:, j] = torch.mv(B, C[:, j])
print(timer.stop())
# 一次性计算A=BC
timer.start()
A = torch.mm(B, C)
print(timer.stop())
# 乘法和加法作为单独的操作(在实践中融合)
gigaflops = [2/i for i in timer.times]
print(f'performance in Gigaflops: element {gigaflops[0]:.3f}, 'f'column {gigaflops[1]:.3f}, full {gigaflops[2]:.3f}')# 如果我们使用第一个选择,每次我们计算一个元素Aij时,都需要将一行和一列向量复制到CPU中。
# 更糟糕的是,由于矩阵元素是按顺序对齐的,因此当从内存中读取它们时,我们需要访问两个向量中许多不相交的位置。
# 第二种选择相对更有利:我们能够在遍历B的同时,将列向量C:j保留在CPU缓存中。 它将内存带宽需求减半,相应地提高了访问速度。
# 第三种选择表面上是最可取的,然而大多数矩阵可能不能完全放入缓存中。
# 第四种选择提供了一个实践上很有用的方案:我们可以将矩阵的区块移到缓存中然后在本地将它们相乘。#11.5.2. 小批量
# 处理单个观测值需要我们执行许多单一矩阵-矢量(甚至矢量-矢量)乘法,这耗费相当大,而且对应深度学习框架也要巨大的开销。
# 这既适用于计算梯度以更新参数时,也适用于用神经网络预测。timer.start()
for j in range(0, 256, 64):A[:, j:j+64] = torch.mm(B, C[:, j:j+64]) #一次性分为64列的“小批量”
timer.stop()
print(f'performance in Gigaflops: block {2 / timer.times[3]:.3f}')
'''
######
'''
#1.5.3. 读取数据集#@save
d2l.DATA_HUB['airfoil'] = (d2l.DATA_URL + 'airfoil_self_noise.dat','76e5be1548fd8222e5074cf0faae75edff8cf93f')#@save
def get_data_ch11(batch_size=10, n=1500):data = np.genfromtxt(d2l.download('airfoil'),dtype=np.float32, delimiter='\t')data = torch.from_numpy((data - data.mean(axis=0)) / data.std(axis=0))data_iter = d2l.load_array((data[:n, :-1], data[:n, -1]),batch_size, is_train=True)return data_iter, data.shape[1]-1 #data.shape[1]-1:一个样本的特征维度(-1指label的那一维度)#11.5.4. 从零开始实现
def sgd(params, states, hyperparams):for p in params:# key-key-key: 在这里将它的输入参数变得更加通用:添加了一个状态输入states,并将超参数放在字典hyperparams中p.data.sub_(hyperparams['lr'] * p.grad)p.grad.data.zero_()#@save
def train_ch11(trainer_fn, states, hyperparams, data_iter,feature_dim, num_epochs=2):# 初始化模型w = torch.normal(mean=0.0, std=0.01, size=(feature_dim, 1),requires_grad=True)b = torch.zeros((1), requires_grad=True)net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss# 训练模型animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[0, num_epochs], ylim=[0.22, 0.35])n, timer = 0, d2l.Timer()for _ in range(num_epochs):for X, y in data_iter:l = loss(net(X), y).mean()l.backward()trainer_fn([w, b], states, hyperparams)#key-key-keyn += X.shape[0]if n % 200 == 0:timer.stop()animator.add(n/X.shape[0]/len(data_iter),(d2l.evaluate_loss(net, data_iter, loss),))timer.start()print(f'loss: {animator.Y[0][-1]:.3f}, {timer.avg():.3f} sec/epoch')return timer.cumsum(), animator.Y[0]def train_sgd(lr, batch_size, num_epochs=2):data_iter, feature_dim = get_data_ch11(batch_size)return train_ch11(sgd, None, {'lr': lr}, data_iter, feature_dim, num_epochs)gd_res = train_sgd(1, 1500, 10) #1)模型参数每个迭代轮数只迭代一次
d2l.plt.show()
sgd_res = train_sgd(0.005, 1) #2)每个迭代轮数有1500次更新(随机梯度下降的一个迭代轮数耗时更多)
d2l.plt.show()
mini1_res = train_sgd(.4, 100) #3)每个迭代轮数所需的时间比随机梯度下降和批量梯度下降所需的时间短
d2l.plt.show()
mini2_res = train_sgd(.05, 10) #4)每个迭代轮数的时间都会增加,因为每批工作负载的执行效率变得更低
d2l.plt.show()d2l.set_figsize([6, 3])
d2l.plot(*list(map(list, zip(gd_res, sgd_res, mini1_res, mini2_res))),'time (sec)', 'loss', xlim=[1e-2, 10],legend=['gd', 'sgd', 'batch size=100', 'batch size=10'])
d2l.plt.gca().set_xscale('log')
d2l.plt.show()
'''#11.5.5. 简洁实现
#@save
def train_concise_ch11(trainer_fn, hyperparams, data_iter, num_epochs=4):# 初始化模型net = nn.Sequential(nn.Linear(5, 1))def init_weights(m):if type(m) == nn.Linear:torch.nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)optimizer = trainer_fn(net.parameters(), **hyperparams) #key-key-keyloss = nn.MSELoss(reduction='none')animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[0, num_epochs], ylim=[0.22, 0.35])n, timer = 0, d2l.Timer()for _ in range(num_epochs):for X, y in data_iter:optimizer.zero_grad()out = net(X)y = y.reshape(out.shape)l = loss(out, y)l.mean().backward()optimizer.step()n += X.shape[0]if n % 200 == 0:timer.stop()# MSELoss计算平方误差时不带系数1/2animator.add(n/X.shape[0]/len(data_iter),(d2l.evaluate_loss(net, data_iter, loss) / 2,))timer.start()print(f'loss: {animator.Y[0][-1]:.3f}, {timer.avg():.3f} sec/epoch')data_iter, _ = get_data_ch11(10)
trainer = torch.optim.SGD
train_concise_ch11(trainer, {'lr': 0.01}, data_iter)
d2l.plt.show()
11.6. 动量法:结合过去梯度,逐渐平滑梯度更新方向

#11.6.1.2. 条件不佳的问题
import torch
from d2l import torch as d2l'''
# 从构造来看,x2方向的梯度比水平x1方向的梯度大得多,变化也快得多。
# 因此,我们陷入两难:如果选择较小的学习率(0.4),我们会确保解不会在x2方向发散,但要承受在x1方向的缓慢收敛。
# 相反,如果学习率较高(0.6),我们在x1方向上进展很快,但在x2方向将会发散。eta = 0.4
def f_2d(x1, x2):return 0.1 * x1 ** 2 + 2 * x2 ** 2
def gd_2d(x1, x2, s1, s2):return (x1 - eta * 0.2 * x1, x2 - eta * 4 * x2, 0, 0)d2l.show_trace_2d(f_2d, d2l.train_2d(gd_2d))
d2l.plt.show()#11.6.1.3. 动量法
# 毕竟,在x1方向上,这将聚合非常对齐的梯度,从而增加我们在每一步中覆盖的距离。
# 相反,在梯度振荡的x2方向,由于相互抵消了对方的振荡,聚合梯度将减小步长大小。
eta, beta = 0.6, 0.5
def momentum_2d(x1, x2, v1, v2):v1 = beta * v1 + 0.2 * x1v2 = beta * v2 + 4 * x2return x1 - eta * v1, x2 - eta * v2, v1, v2d2l.show_trace_2d(f_2d, d2l.train_2d(momentum_2d))#11.6.1.4. 有效样本权重:结合之前多少个样本梯度
d2l.set_figsize()
betas = [0.95, 0.9, 0.6, 0]
for beta in betas:x = torch.arange(40).detach().numpy()d2l.plt.plot(x, beta ** x, label=f'beta = {beta:.2f}')
d2l.plt.xlabel('time')
d2l.plt.legend()
d2l.plt.show()
'''#11.6.2. 实际实验
#11.6.2.1. 从零开始实现
def init_momentum_states(feature_dim):v_w = torch.zeros((feature_dim, 1))v_b = torch.zeros(1)return (v_w, v_b)
def sgd_momentum(params, states, hyperparams):for p, v in zip(params, states):with torch.no_grad():v[:] = hyperparams['momentum'] * v + p.gradp[:] -= hyperparams['lr'] * vp.grad.data.zero_()def train_momentum(lr, momentum, num_epochs=2):d2l.train_ch11(sgd_momentum,init_momentum_states(feature_dim),{'lr': lr, 'momentum': momentum},data_iter,feature_dim, num_epochs)data_iter, feature_dim = d2l.get_data_ch11(batch_size=10) #feature_dim=data.shape[1]-1:一个样本的特征维度(-1指label的那一维度)
train_momentum(0.02, 0.5)
d2l.plt.show()train_momentum(0.01, 0.9) #将学习率略微降,以确保可控
d2l.plt.show()
train_momentum(0.005, 0.9) #降低学习率进一步解决了任何非平滑优化问题的困难
d2l.plt.show()#11.6.2.2. 简洁实现
trainer = torch.optim.SGD
d2l.train_concise_ch11(trainer, {'lr': 0.005, 'momentum': 0.9}, data_iter)
d2l.plt.show()11.7. AdaGrad算法
#11.7.3. 算法
import math
import torch
from d2l import torch as d2ldef adagrad_2d(x1, x2, s1, s2):eps = 1e-6g1, g2 = 0.2 * x1, 4 * x2s1 += g1 ** 2s2 += g2 ** 2x1 -= eta / math.sqrt(s1 + eps) * g1x2 -= eta / math.sqrt(s2 + eps) * g2return x1, x2, s1, s2def f_2d(x1, x2):return 0.1 * x1 ** 2 + 2 * x2 ** 2eta = 0.4
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))eta = 2
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))
d2l.plt.show()#11.7.4. 从零开始实现
def init_adagrad_states(feature_dim):s_w = torch.zeros((feature_dim, 1))s_b = torch.zeros(1)return (s_w, s_b)def adagrad(params, states, hyperparams):eps = 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] += torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(adagrad, init_adagrad_states(feature_dim),{'lr': 0.1}, data_iter, feature_dim);d2l.plt.show()#11.7.5. 简洁实现
trainer = torch.optim.Adagrad
d2l.train_concise_ch11(trainer, {'lr': 0.1}, data_iter)d2l.plt.show()
11.8. RMSProp算法
#11.8.1. 算法
import math
import torch
from d2l import torch as d2ld2l.set_figsize()
gammas = [0.95, 0.9, 0.8, 0.7]
for gamma in gammas:x = torch.arange(40).detach().numpy()d2l.plt.plot(x, (1-gamma) * gamma ** x, label=f'gamma = {gamma:.2f}')
d2l.plt.xlabel('time')
d2l.plt.show()#11.8.2. 从零开始实现
def rmsprop_2d(x1, x2, s1, s2):g1, g2, eps = 0.2 * x1, 4 * x2, 1e-6s1 = gamma * s1 + (1 - gamma) * g1 ** 2s2 = gamma * s2 + (1 - gamma) * g2 ** 2x1 -= eta / math.sqrt(s1 + eps) * g1x2 -= eta / math.sqrt(s2 + eps) * g2return x1, x2, s1, s2def f_2d(x1, x2):return 0.1 * x1 ** 2 + 2 * x2 ** 2eta, gamma = 0.4, 0.9
d2l.show_trace_2d(f_2d, d2l.train_2d(rmsprop_2d))
d2l.plt.show()def init_rmsprop_states(feature_dim):s_w = torch.zeros((feature_dim, 1))s_b = torch.zeros(1)return (s_w, s_b)def rmsprop(params, states, hyperparams):gamma, eps = hyperparams['gamma'], 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] = gamma * s + (1 - gamma) * torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(rmsprop, init_rmsprop_states(feature_dim),{'lr': 0.01, 'gamma': 0.9}, data_iter, feature_dim);
d2l.plt.show()#11.8.3. 简洁实现trainer = torch.optim.RMSprop
d2l.train_concise_ch11(trainer, {'lr': 0.01, 'alpha': 0.9},data_iter)
d2l.plt.show()
11.9. Adadelta
#11.9.2. 代码实现
import torch
from d2l import torch as d2ldef init_adadelta_states(feature_dim):s_w, s_b = torch.zeros((feature_dim, 1)), torch.zeros(1)delta_w, delta_b = torch.zeros((feature_dim, 1)), torch.zeros(1)return ((s_w, delta_w), (s_b, delta_b))def adadelta(params, states, hyperparams):rho, eps = hyperparams['rho'], 1e-5for p, (s, delta) in zip(params, states):with torch.no_grad():# In-placeupdatesvia[:]s[:] = rho * s + (1 - rho) * torch.square(p.grad)g = (torch.sqrt(delta + eps) / torch.sqrt(s + eps)) * p.gradp[:] -= gdelta[:] = rho * delta + (1 - rho) * g * gp.grad.data.zero_()data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(adadelta, init_adadelta_states(feature_dim),{'rho': 0.9}, data_iter, feature_dim);d2l.plt.show()#简洁
trainer = torch.optim.Adadelta
d2l.train_concise_ch11(trainer, {'rho': 0.9}, data_iter)11.10. Adam算法



#11.10.2. 实现
import torch
from d2l import torch as d2ldef init_adam_states(feature_dim):v_w, v_b = torch.zeros((feature_dim, 1)), torch.zeros(1)s_w, s_b = torch.zeros((feature_dim, 1)), torch.zeros(1)return ((v_w, s_w), (v_b, s_b))def adam(params, states, hyperparams):beta1, beta2, eps = 0.9, 0.999, 1e-6for p, (v, s) in zip(params, states):with torch.no_grad():v[:] = beta1 * v + (1 - beta1) * p.grads[:] = beta2 * s + (1 - beta2) * torch.square(p.grad)v_bias_corr = v / (1 - beta1 ** hyperparams['t'])s_bias_corr = s / (1 - beta2 ** hyperparams['t'])p[:] -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr)+ eps)p.grad.data.zero_()hyperparams['t'] += 1data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(adam,init_adam_states(feature_dim),{'lr': 0.01, 't': 1},data_iter, feature_dim)
d2l.plt.show()#Adam的简洁实现
trainer = torch.optim.Adam
d2l.train_concise_ch11(trainer, {'lr': 0.01}, data_iter)
d2l.plt.show()#11.10.3. Yogi
def yogi(params, states, hyperparams):beta1, beta2, eps = 0.9, 0.999, 1e-3for p, (v, s) in zip(params, states):with torch.no_grad():v[:] = beta1 * v + (1 - beta1) * p.grads[:] = s + (1 - beta2) * torch.square(p.grad) * torch.sign(torch.square(p.grad) - s) #区别于adam的地方v_bias_corr = v / (1 - beta1 ** hyperparams['t'])s_bias_corr = s / (1 - beta2 ** hyperparams['t'])p[:] -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr)+ eps)p.grad.data.zero_()hyperparams['t'] += 1data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(yogi, init_adam_states(feature_dim),{'lr': 0.01, 't': 1}, data_iter, feature_dim)
d2l.plt.show()
2. 调整更新速率
11.11. 学习率调度器
https://zh-v2.d2l.ai/chapter_optimization/lr-scheduler.html



#11.11.1. 一个简单的问题
import math
import torch
from torch import nn
from torch.optim import lr_scheduler
from d2l import torch as d2ldef net_fn():model = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.ReLU(),nn.Linear(120, 84), nn.ReLU(),nn.Linear(84, 10))return modelloss = nn.CrossEntropyLoss()
device = d2l.try_gpu()batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)# 代码几乎与d2l.train_ch6定义在卷积神经网络一章LeNet一节中的相同
def train(net, train_iter, test_iter, num_epochs, loss, trainer, device,scheduler=None):net.to(device)animator = d2l.Animator(xlabel='epoch', xlim=[0, num_epochs],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):metric = d2l.Accumulator(3) # train_loss,train_acc,num_examplesfor i, (X, y) in enumerate(train_iter):net.train()trainer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()trainer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])train_loss = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % 50 == 0:animator.add(epoch + i / len(train_iter),(train_loss, train_acc, None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)animator.add(epoch+1, (None, None, test_acc))###key-key-key: schedulerif scheduler:if scheduler.__module__ == lr_scheduler.__name__:# UsingPyTorchIn-Builtschedulerscheduler.step()else:# Usingcustomdefinedschedulerfor param_group in trainer.param_groups:param_group['lr'] = scheduler(epoch)print(f'train loss {train_loss:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')lr, num_epochs = 0.3, 30
net = net_fn()
# trainer = torch.optim.SGD(net.parameters(), lr=lr)
# train(net, train_iter, test_iter, num_epochs, loss, trainer, device)
# #结论:留意在超过了某点、测试准确度方面的进展停滞时,训练准确度将如何继续提高。 两条曲线之间的间隙表示过拟合
# d2l.plt.show()
#
#
# #11.11.2. 学习率调度器
# #1)学习率的大小很重要。如果它太大,优化就会发散;如果它太小,训练就会需要过长时间,或者我们最终只能得到次优的结果
# #2)衰减速率同样很重要。如果学习率持续过高,我们可能最终会在最小值附近弹跳,从而无法达到最优解。
# #3)初始化。这既涉及参数最初的设置方式(详情请参阅 4.8节),又关系到它们最初的演变方式。这被戏称为预热(warmup),
# # 即我们最初开始向着解决方案迈进的速度有多快。一开始的大步可能没有好处,特别是因为最初的参数集是随机的。最初的更新方向可能也是毫无意义的
#
#
# #普通衰减调度器:多项式衰减
# lr = 0.1
# trainer.param_groups[0]["lr"] = lr
# print(f'learning rate is now {trainer.param_groups[0]["lr"]:.2f}')
#
# class SquareRootScheduler:
# def __init__(self, lr=0.1):
# self.lr = lr
#
# def __call__(self, num_update):
# return self.lr * pow(num_update + 1.0, -0.5)
#
# scheduler = SquareRootScheduler(lr=0.1)
# d2l.plot(torch.arange(num_epochs), [scheduler(t) for t in range(num_epochs)])
# d2l.plt.show()
#
#
# trainer = torch.optim.SGD(net.parameters(), lr)
# train(net, train_iter, test_iter, num_epochs, loss, trainer, device,scheduler) #key:scheduler
# #结论:这比以前好一些:曲线比以前更加平滑,并且过拟合更小了。
# d2l.plt.show()
#
#
# #11.11.3.1. 单因子调度器
# #乘法衰减
# class FactorScheduler:
# def __init__(self, factor=1, stop_factor_lr=1e-7, base_lr=0.1):
# self.factor = factor
# self.stop_factor_lr = stop_factor_lr
# self.base_lr = base_lr
#
# def __call__(self, num_update):
# self.base_lr = max(self.stop_factor_lr, self.base_lr * self.factor)
# return self.base_lr
#
# scheduler = FactorScheduler(factor=0.9, stop_factor_lr=1e-2, base_lr=2.0)
# d2l.plot(torch.arange(50), [scheduler(t) for t in range(50)])
# d2l.plt.show()
#
#
# trainer = torch.optim.SGD(net.parameters(), lr)
# train(net, train_iter, test_iter, num_epochs, loss, trainer, device,
# scheduler)
# d2l.plt.show()
#
#
# #11.11.3.2. 多因子调度器
# trainer = torch.optim.SGD(net.parameters(), lr=0.5)
# scheduler = lr_scheduler.MultiStepLR(trainer, milestones=[15, 30], gamma=0.5)
#
# def get_lr(trainer, scheduler):
# lr = scheduler.get_last_lr()[0]
# trainer.step()
# scheduler.step()
# return lr
#
# d2l.plot(torch.arange(num_epochs), [get_lr(trainer, scheduler) for t in range(num_epochs)])
# #结论:让优化持续进行,直到权重向量的分布达到一个驻点。 此时,我们才将学习率降低,以获得更高质量的代理来达到一个良好的局部最小值。
# d2l.plt.show()
#
#
# train(net, train_iter, test_iter, num_epochs, loss, trainer, device,scheduler)
# d2l.plt.show()#11.11.3.3. 余弦调度器
class CosineScheduler:def __init__(self, max_update, base_lr=0.01, final_lr=0.0,warmup_steps=0, warmup_begin_lr=0):self.final_lr = final_lrself.base_lr_orig = base_lrself.warmup_steps = warmup_stepsself.warmup_begin_lr = warmup_begin_lrself.max_update = max_updateself.max_steps = self.max_update - self.warmup_stepsdef get_warmup_lr(self, epoch):increase = (self.base_lr_orig - self.warmup_begin_lr) * float(epoch) / float(self.warmup_steps)return self.warmup_begin_lr + increasedef __call__(self, epoch):if epoch < self.warmup_steps:return self.get_warmup_lr(epoch)if epoch <= self.max_update:self.base_lr = self.final_lr + \(self.base_lr_orig - self.final_lr) * (1 +math.cos(math.pi * (epoch - self.warmup_steps) / self.max_steps)) / 2return self.base_lrscheduler = CosineScheduler(max_update=20, base_lr=0.3, final_lr=0.01)
d2l.plot(torch.arange(num_epochs), [scheduler(t) for t in range(num_epochs)])
d2l.plt.show()trainer = torch.optim.SGD(net.parameters(), lr=0.3)
train(net, train_iter, test_iter, num_epochs, loss, trainer, device,scheduler)
#结论:在计算机视觉的背景下,这个调度方式可能产生改进的结果。但请注意,如下所示,这种改进并不一定成立。
d2l.plt.show()#11.11.3.4. 余弦调度器+预热:
# 在某些情况下,初始化参数不足以得到良好的解。 这对某些高级网络设计来说尤其棘手,可能导致不稳定的优化结果。
# 预热核心:在此期间(5)学习率将增加至初始最大值(0.3),然后冷却直到优化过程结束(0.01)。 为了简单起见,通常使用线性递增。
scheduler = CosineScheduler(20, warmup_steps=5, base_lr=0.3, final_lr=0.01)
d2l.plot(torch.arange(num_epochs), [scheduler(t) for t in range(num_epochs)])
d2l.plt.show()trainer = torch.optim.SGD(net.parameters(), lr=0.3)
train(net, train_iter, test_iter, num_epochs, loss, trainer, device,scheduler)
d2l.plt.show()
相关内容
热门资讯
linux入门---制作进度条
了解缓冲区 我们首先来看看下面的操作: 我们首先创建了一个文件并在这个文件里面添加了...
C++ 机房预约系统(六):学...
8、 学生模块 8.1 学生子菜单、登录和注销 实现步骤: 在Student.cpp的...
A.机器学习入门算法(三):基...
机器学习算法(三):K近邻(k-nearest neigh...
数字温湿度传感器DHT11模块...
模块实例https://blog.csdn.net/qq_38393591/article/deta...
有限元三角形单元的等效节点力
文章目录前言一、重新复习一下有限元三角形单元的理论1、三角形单元的形函数(Nÿ...
Redis 所有支持的数据结构...
Redis 是一种开源的基于键值对存储的 NoSQL 数据库,支持多种数据结构。以下是...
win下pytorch安装—c...
安装目录一、cuda安装1.1、cuda版本选择1.2、下载安装二、cudnn安装三、pytorch...
MySQL基础-多表查询
文章目录MySQL基础-多表查询一、案例及引入1、基础概念2、笛卡尔积的理解二、多表查询的分类1、等...
keil调试专题篇
调试的前提是需要连接调试器比如STLINK。 然后点击菜单或者快捷图标均可进入调试模式。 如果前面...
MATLAB | 全网最详细网...
一篇超超超长,超超超全面网络图绘制教程,本篇基本能讲清楚所有绘制要点&#...
IHome主页 - 让你的浏览...
随着互联网的发展,人们越来越离不开浏览器了。每天上班、学习、娱乐,浏览器...
TCP 协议
一、TCP 协议概念 TCP即传输控制协议(Transmission Control ...
营业执照的经营范围有哪些
营业执照的经营范围有哪些 经营范围是指企业可以从事的生产经营与服务项目,是进行公司注册...
C++ 可变体(variant...
一、可变体(variant) 基础用法 Union的问题: 无法知道当前使用的类型是什...
血压计语音芯片,电子医疗设备声...
语音电子血压计是带有语音提示功能的电子血压计,测量前至测量结果全程语音播报...
MySQL OCP888题解0...
文章目录1、原题1.1、英文原题1.2、答案2、题目解析2.1、题干解析2.2、选项解析3、知识点3...
【2023-Pytorch-检...
(肆十二想说的一些话)Yolo这个系列我们已经更新了大概一年的时间,现在基本的流程也走走通了,包含数...
实战项目:保险行业用户分类
这里写目录标题1、项目介绍1.1 行业背景1.2 数据介绍2、代码实现导入数据探索数据处理列标签名异...
记录--我在前端干工地(thr...
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前段时间接触了Th...
43 openEuler搭建A...
文章目录43 openEuler搭建Apache服务器-配置文件说明和管理模块43.1 配置文件说明...