
java集合类|Map讲解附加代码和运行结果
目录
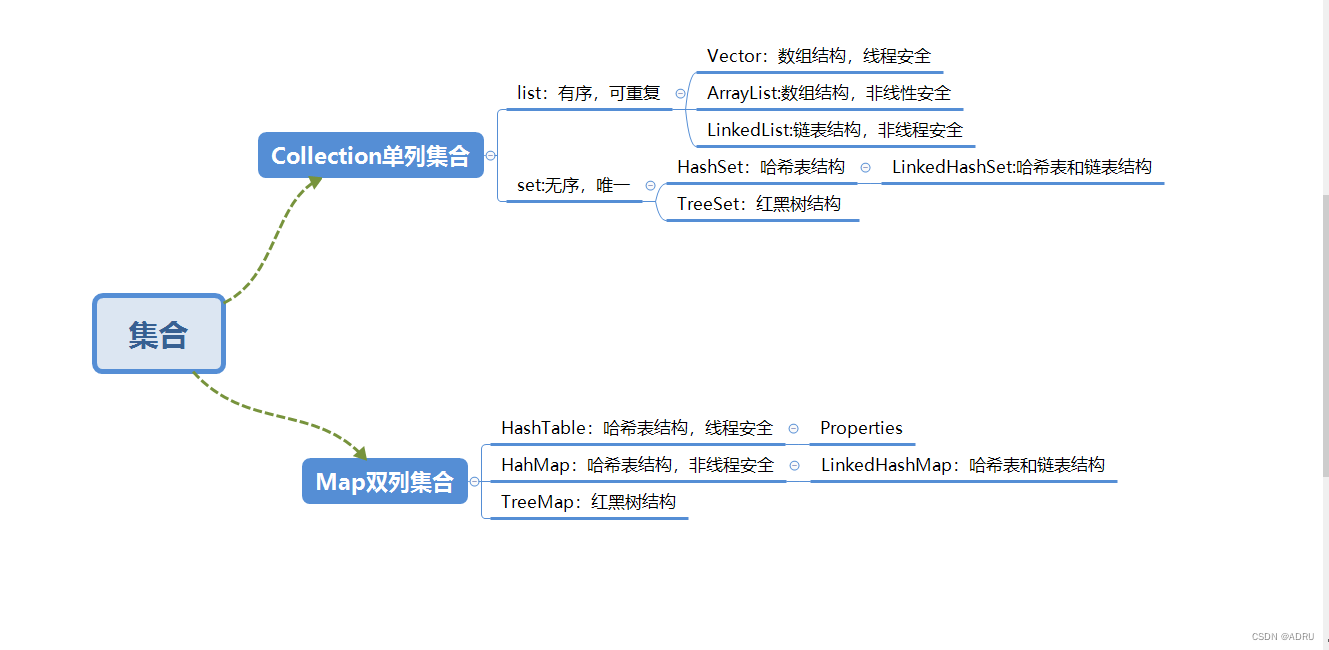
1.Map集合
创建
基本的map使用方法
添加数据,打印数据
获取长度,删除元素,判断元素是否存在
remove()方法,用来删除某一条key,返回值为其对应的value
判断map中是否含有key或者判断是否有value
编辑
hashmap添加另一个同类型的map下的所有数据
map中替换某个key的value
TreeMap
TreeMap的特点
TreeMap基本使用
Hashtable、HashMap、TreeMap的区别
1.Map集合
创建
Map map = new HashMap<>(); 基本的map使用方法
添加数据,打印数据
1.map.put('张三','1212')//此方法用于向map中添加元素此方法的key不允许有重复,如果重复则会发生覆盖如果你的map中存在key的值,则会返回key对应的value如果不存在则返回null
2.map.get("a")//此方法可以获取key对应的value值
测试上述的两个方法
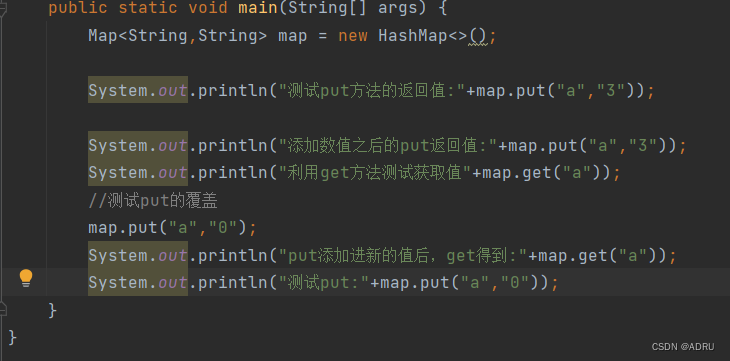
上述方法的测试结果为:
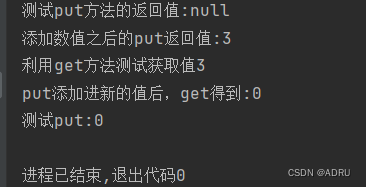
在此我推荐大家用下面的getOrDefault()这个方法,如果没有这个key就返回一个你赋予的值,这样不会出现报空指针的情况,
map.getOrDefault(Object key, V defaultValue)
//当Map集合中有这个key时,就使用这个key的值, 如果没有就使用默认值defaultValue。获取长度,删除元素,判断元素是否存在
map.size()
此方法用于返回map中的数据数量,准确来说就是key_value组数map.claear()
此方法用来清空map集合map.isEmpt()
此方法用来查看map中是否有元素remove()方法,用来删除某一条key,返回值为其对应的value

上述程序输出结果为:
判断map中是否含有key或者判断是否有value
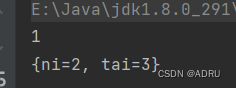
调用containsKey()方法
public static void main(String[] args) {Map map = new HashMap<>();map.put("ji",1);map.put("ni",2);map.put("tai",3);System.out.println(map.containsKey("ji"));System.out.println(map.containsKey("mei"));System.out.println(map.containsValue(1));} 运行结果为:

hashmap添加另一个同类型的map下的所有数据
调用putAll()方法
public static void main(String[] args) {Map map = new HashMap<>();Map map1 = new HashMap<>();map.put("ji",1);map.put("ni",2);map.put("tai",3);map1.put("xiaoheizi",4);map.putAll(map1);System.out.println(map);} 运行结果为:

map中替换某个key的value
调用replace()方法
Map map = new HashMap<>();map.put("ji",1);map.put("ni",2);map.put("tai",3);map.replace("ni",22);System.out.println(map);} 运行结果如图:
![]()
TreeMap
TreeMap的特点

TreeMap基本使用
TreeMap与TreeSet类似,也需要通过存储元素的对象类型实现Comparable接口进而重写compareTo方法来确定排序规则,存储结构也是红黑树,如果要在实例化TreeMap对象的时候确定排序规则,就实现Comparator接口(通过匿名内部类的方式来实现),Comparator实际上就是一个排序规则定制器。
Hashtable、HashMap、TreeMap的区别
HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。存储的内容是基于key-value的键值对映射,不能有重复的key,而且一个key只能映射一个value。HashSet底层就是基于HashMap实现的。
Hashtable的key、value都不能为null;HashMap的key、value可以为null,不过只能有一个key为null,但可以有多个null的value;TreeMap键、值都不能为null。
Hashtable、HashMap具有无序特性。TreeMap是利用红黑树实现的(树中的每个节点的值都会大于或等于它的左子树中的所有节点的值,并且小于或等于它的右子树中的所有节点的值),实现了SortMap接口,能够对保存的记录根据键进行排序。所以一般需求排序的情况下首选TreeMap,默认按键的升序排序(深度优先搜索),也可以自定义实现Comparator接口实现排序方式。