
mysql中必知的sql优化及索引优化
文章目录
- 利用联合索引(索引覆盖)减少回表
- 利用索引的有序性减少server层排序
- 使用自增字段作主键优化查询
- mysql联合索引失效的特殊情况
- 数据库事务的四大特性是如何实现的
利用联合索引(索引覆盖)减少回表
假如我们现在有一个student表,有主键id,name,age,address,sex等字段.
其中name字段建了一个普通索引.
当我们执行以下sql时:
select name,age from student where name='a'
会先根据name所在得非聚簇索引找到name所对应得主键id,然后根据主键id去聚簇索引中找到该条数据对应的其他字段,比如说age.最后进行返回. 这个过程叫做回表.
在sql优化中是不推荐回表的,因为会降低查询效率,在以上案例中,如果我们经常需要查询name,age字段,可以考虑给这两个字段创建一个联合索引,当创建联合索引后,以上sql就不再需要进行回表,因为name,age字段信息都会存储在非聚簇索引中.不需要查询非聚簇索引.这种情况也叫做索引覆盖.
利用索引的有序性减少server层排序
假设有一张订单表 order,主要包含了主键订单编码 order_no、订单状态 status、提交时间 create_time 等列,并且创建了 status 列索引和 create_time 列索引。
此时通过创建时间降序获取状态为 1 的订单编码,以下是具体实现代码:
select order_no from order where status =1 order by create_time
你知道其中的问题所在吗?我们又该如何优化?
以上sql并不会用到create_time索引,只会用到status索引,将数据通过status索引查出来返回给server层,在server层通过快速排序算法对数据记性排序,最后进行返回.
我们可以对status和create_time建立联合索引,利用索引的有序性,在联合索引中,会优先按照第一个字段进行排序,如果第一个字段相同,就会按照第二个字段排序.
这样通过status查出来的数据直接就是有序的,避免在server层排序. 如下sql即可:
select order_no from order where status =1
使用自增字段作主键优化查询
在InnoDB中,创建主键索引默认为聚簇索引,数据被存放在了B+树的叶子节点上,也就是说,同一个叶子结点上的数据是按主键id进行顺序存放的,因此,每当有一条数据插入时,数据库会根据主键将其插入到对应的叶子节点上.
如果我们使用自增主键,那么数据将会按顺序添加到叶子节点上,不需要移动已有的数据.当页面写满,会新开辟一个磁盘页.因为不需要移动数据,这种插入的效率非常高.
而如果我们不使用自增主键,就需要根据主键的索引值进行随机插入,那可能就会插入到某个叶子节点的中间位置,此时就需要移动其他数据,甚至需要从一个页面复制到另一个页面,我们将这种情况称为页分裂.页分裂会造成大量的内存碎片,导致结构不紧凑,从而影响查询效率.
因此,在使用InnoDB作为存储引擎时,在没有特殊业务需求的情况下,建议使用自增id作为主键.
mysql联合索引失效的特殊情况
这里指的不是最左匹配原则,而是使用了最左匹配原则的情况下仍会失效的情况
现有一个account表,有主键id,name,money等字段:
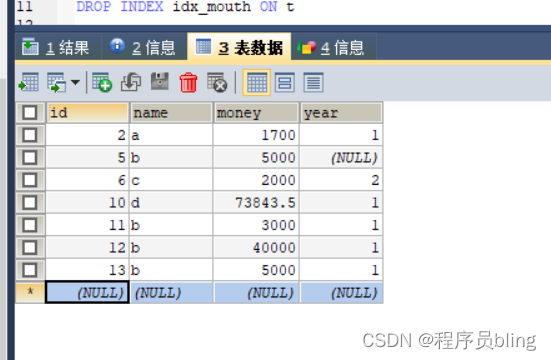
使用name和money做联合索引,name是第一列:

当我查询name='b’的时候是不走索引的
EXPLAIN SELECT * FROM account WHERE NAME='b'

而查询name='c’的时候是走索引的
EXPLAIN SELECT * FROM account WHERE NAME='c'

当查询name=‘b’,不需要回表的时候也是走索引的
EXPLAIN SELECT name,money FROM account WHERE NAME='b'

这是为什么呢?为什么有的走有的不走呢?
这是因为表中的数据分布很不均匀,name='b’的数据占很大一部分,并且由于我们使用SELECT * ,导致每条数据都需要回表,server层分析器发现存在大量的回表操作,这种情况下,全表扫描反而比走索引更加高效, 从而选择了全表扫描.
这种情况和我们使用between类似,当数据量比较小,并且between的范围比较大,也可能不走索引,如果想使用我们期望的索引,需要给server层分析器一个hint,force index(idx_order_id)
数据库事务的四大特性是如何实现的
- 原子性
每个事务是一个整体,不可分割.事务中SQL语句要么全部执行成功,要么都失败.
通过事务的回滚机制,保证一个事务中的要么全部成功,要不全部失败
- 一致性
事务在执行前数据库的状态和执行后数据库的状态保持一致.
关于一致性的解释,这里有一个经典面试题:
a.有一个人在9:00的时候查询数据库中的某一条数据.假设查的是balance=200;数据很多很多.在9:02的时候才查到了这条数据.
b.但是在9:01的时候另外一个人对这条数据进行了更改,改成了balance=100;
问:这个人查询到的是100还是200?
答:是200;在某一时刻查询的就是该时刻数据库的状态.也就是一致性.
- 隔离性
事务与事务之间不应该相互影响.执行时保持隔离的状态.
事务的一致性和隔离性都是通过MVCC+锁机制来实现的,通过MVCC保证读写状态下的一致性和隔离性,通过锁机制保证写写状态下的一致性和隔离性.
- 持久性
事务执行成功之后(commit之后),对数据库的修改是持久的,就算关机.也能保存下来.
通过bin.log+redo.log两阶段提交实现持久性.
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.

下一篇:通达信 34日上升三角形主图源码